 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^\text{T}$A: Adaptive Transformation Agent for Text-Guided Subject-Position Variable Background Inpainting
Apr 02, 2025



Image inpainting aims to fill the missing region of an image. Recently, there has been a surge of interest in foreground-conditioned background inpainting, a sub-task that fills the background of an image while the foreground subject and associated text prompt are provided. Existing background inpainting methods typically strictly preserve the subject's original position from the source image, resulting in inconsistencies between the subject and the generated background. To address this challenge, we propose a new task, the "Text-Guided Subject-Position Variable Background Inpainting", which aims to dynamically adjust the subject position to achieve a harmonious relationship between the subject and the inpainted background, and propose the Adaptive Transformation Agent (A$^\text{T}$A) for this task. Firstly, we design a PosAgent Block that adaptively predicts an appropriate displacement based on given features to achieve variable subject-position. Secondly, we design the Reverse Displacement Transform (RDT) module, which arranges multiple PosAgent blocks in a reverse structure, to transform hierarchical feature maps from deep to shallow based on semantic information. Thirdly, we equip A$^\text{T}$A with a Position Switch Embedding to control whether the subject's position in the generated image is adaptively predicted or fixed. Extensive comparative experiments validate the effectiveness of our A$^\text{T}$A approach, which not only demonstrates superior inpainting capabilities in subject-position variable inpainting, but also ensures good performance on subject-position fixed inpainting.
Exploring Real&Synthetic Dataset and Linear Attention in Image Restoration
Dec 05, 2024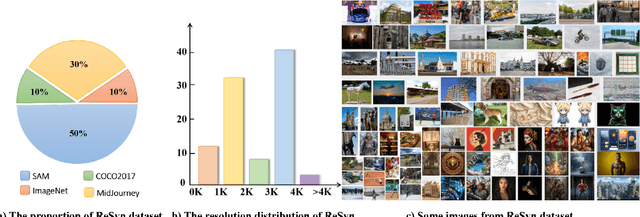
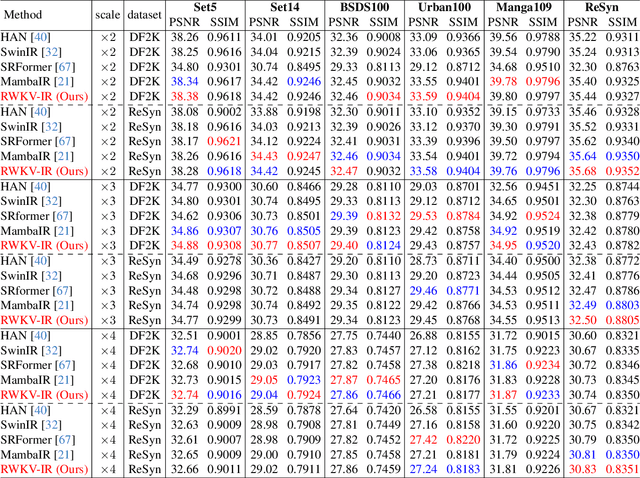
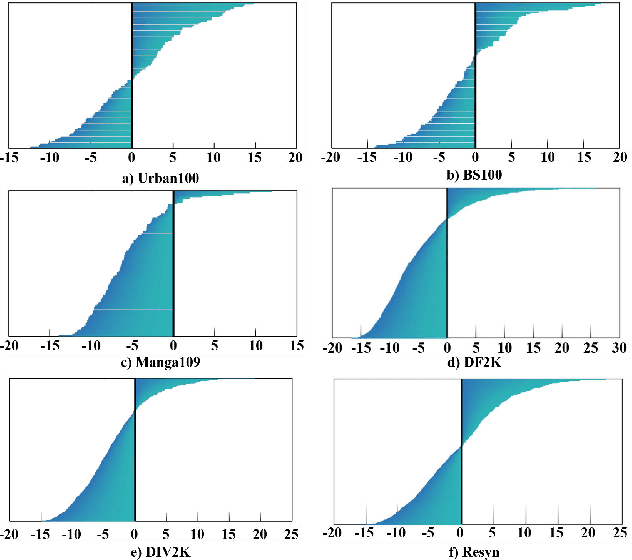

Image Restoration aims to restore degraded images, with deep learning, especially CNNs and Transformers, enhancing performance. However, there's a lack of a unified training benchmark for IR. We identified a bias in image complexity between training and testing datasets, affecting restoration quality. To address this, we created ReSyn, a large-scale IR dataset with balanced complexity, including real and synthetic images. We also established a unified training standard for IR models. Our RWKV-IR model integrates linear complexity RWKV into transformers for global and local receptive fields. It replaces Q-Shift with Depth-wise Convolution for local dependencies and combines Bi-directional attention for global-local awareness. The Cross-Bi-WKV module balances horizontal and vertical attention. Experiments show RWKV-IR's effectiveness in image restoration.
Pinco: Position-induced Consistent Adapter for Diffusion Transformer in Foreground-conditioned Inpainting
Dec 05, 2024Foreground-conditioned inpainting aims to seamlessly fill the background region of an image by utilizing the provided foreground subject and a text description. While existing T2I-based image inpainting methods can be applied to this task, they suffer from issues of subject shape expansion, distortion, or impaired ability to align with the text description, resulting in inconsistencies between the visual elements and the text description. To address these challenges, we propose Pinco, a plug-and-play foreground-conditioned inpainting adapter that generates high-quality backgrounds with good text alignment while effectively preserving the shape of the foreground subject. Firstly, we design a Self-Consistent Adapter that integrates the foreground subject features into the layout-related self-attention layer, which helps to alleviate conflicts between the text and subject features by ensuring that the model can effectively consider the foreground subject's characteristics while processing the overall image layout. Secondly, we design a Decoupled Image Feature Extraction method that employs distinct architectures to extract semantic and shape features separately, significantly improving subject feature extraction and ensuring high-quality preservation of the subject's shape. Thirdly, to ensure precise utilization of the extracted features and to focus attention on the subject region, we introduce a Shared Positional Embedding Anchor, greatly improving the model's understanding of subject features and boosting training efficiency. Extensive experiments demonstrate that our method achieves superior performance and efficiency in foreground-conditioned inpainting.
AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
Dec 10, 2023Anomaly inspection plays an important role in industrial manufacture. Existing anomaly inspection methods are limited in their performance due to insufficient anomaly data. Although anomaly generation methods have been proposed to augment the anomaly data, they either suffer from poor generation authenticity or inaccurate alignment between the generated anomalies and masks. To address the above problems, we propose AnomalyDiffusion, a novel diffusion-based few-shot anomaly generation model, which utilizes the strong prior information of latent diffusion model learned from large-scale dataset to enhance the generation authenticity under few-shot training data. Firstly, we propose Spatial Anomaly Embedding, which consists of a learnable anomaly embedding and a spatial embedding encoded from an anomaly mask, disentangling the anomaly information into anomaly appearance and location information. Moreover, to improve the alignment between the generated anomalies and the anomaly masks, we introduce a novel Adaptive Attention Re-weighting Mechanism. Based on the disparities between the generated anomaly image and normal sample, it dynamically guides the model to focus more on the areas with less noticeable generated anomalies, enabling generation of accurately-matched anomalous image-mask pairs. Extensive experiments demonstrate that our model significantly outperforms the state-of-the-art methods in generation authenticity and diversity, and effectively improves the performance of downstream anomaly inspection tasks. The code and data are available in https://github.com/sjtuplayer/anomalydiffusion.