 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedVisor: Reasoning-Aware Prompt Injection Defense via Zero-Copy KV Cache Reuse
Feb 02, 2026Large Language Models (LLMs) are increasingly vulnerable to Prompt Injection (PI) attacks, where adversarial instructions hidden within retrieved contexts hijack the model's execution flow. Current defenses typically face a critical trade-off: prevention-based fine-tuning often degrades general utility via the "alignment tax", while detection-based filtering incurs prohibitive latency and memory costs. To bridge this gap, we propose RedVisor, a unified framework that synthesizes the explainability of detection systems with the seamless integration of prevention strategies. To the best of our knowledge, RedVisor is the first approach to leverage fine-grained reasoning paths to simultaneously detect attacks and guide the model's safe response. We implement this via a lightweight, removable adapter positioned atop the frozen backbone. This adapter serves a dual function: it first generates an explainable analysis that precisely localizes the injection and articulates the threat, which then explicitly conditions the model to reject the malicious command. Uniquely, the adapter is active only during this reasoning phase and is effectively muted during the subsequent response generation. This architecture yields two distinct advantages: (1) it mathematically preserves the backbone's original utility on benign inputs; and (2) it enables a novel KV Cache Reuse strategy, eliminating the redundant prefill computation inherent to decoupled pipelines. We further pioneer the integration of this defense into the vLLM serving engine with custom kernels. Experiments demonstrate that RedVisor outperforms state-of-the-art defenses in detection accuracy and throughput while incurring negligible utility loss.
Wukong Framework for Not Safe For Work Detection in Text-to-Image systems
Aug 01, 2025



Text-to-Image (T2I) generation is a popular AI-generated content (AIGC) technology enabling diverse and creative image synthesis. However, some outputs may contain Not Safe For Work (NSFW) content (e.g., violence), violating community guidelines. Detecting NSFW content efficiently and accurately, known as external safeguarding, is essential. Existing external safeguards fall into two types: text filters, which analyze user prompts but overlook T2I model-specific variations and are prone to adversarial attacks; and image filters, which analyze final generated images but are computationally costly and introduce latency. Diffusion models, the foundation of modern T2I systems like Stable Diffusion, generate images through iterative denoising using a U-Net architecture with ResNet and Transformer blocks. We observe that: (1) early denoising steps define the semantic layout of the image, and (2) cross-attention layers in U-Net are crucial for aligning text and image regions. Based on these insights, we propose Wukong, a transformer-based NSFW detection framework that leverages intermediate outputs from early denoising steps and reuses U-Net's pre-trained cross-attention parameters. Wukong operates within the diffusion process, enabling early detection without waiting for full image generation. We also introduce a new dataset containing prompts, seeds, and image-specific NSFW labels, and evaluate Wukong on this and two public benchmarks. Results show that Wukong significantly outperforms text-based safeguards and achieves comparable accuracy of image filters, while offering much greater efficiency.
Data Watermarking for Sequential Recommender Systems
Nov 20, 2024



In the era of large foundation models, data has become a crucial component for building high-performance AI systems. As the demand for high-quality and large-scale data continues to rise, data copyright protection is attracting increasing attention. In this work, we explore the problem of data watermarking for sequential recommender systems, where a watermark is embedded into the target dataset and can be detected in models trained on that dataset. We address two specific challenges: dataset watermarking, which protects the ownership of the entire dataset, and user watermarking, which safeguards the data of individual users. We systematically define these problems and present a method named DWRS to address them. Our approach involves randomly selecting unpopular items to create a watermark sequence, which is then inserted into normal users' interaction sequences. Extensive experiments on five representative sequential recommendation models and three benchmark datasets demonstrate the effectiveness of DWRS in protecting data copyright while preserving model utility.
Facet-Aware Multi-Head Mixture-of-Experts Model for Sequential Recommendation
Nov 03, 2024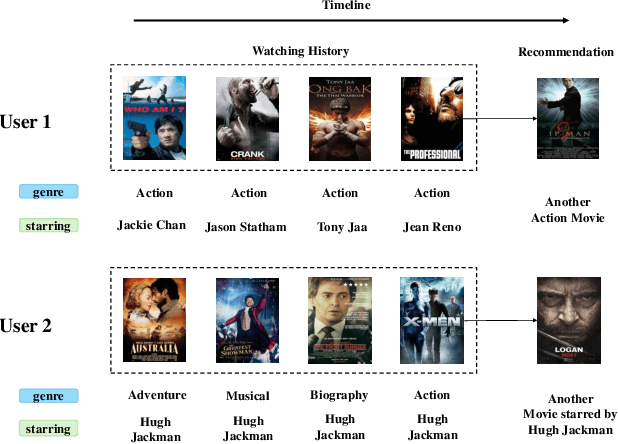
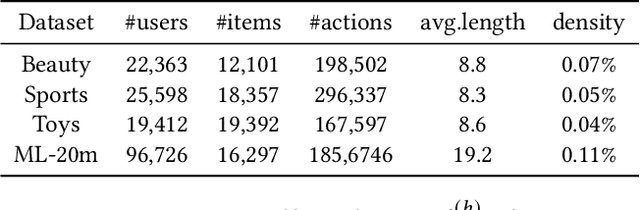
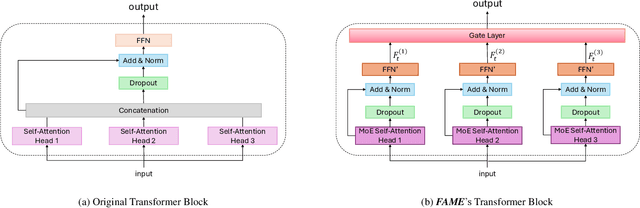
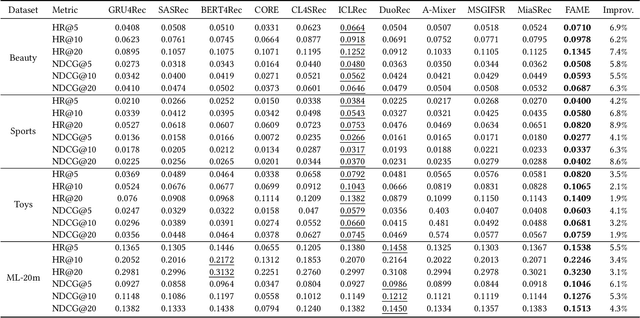
Sequential recommendation (SR) systems excel at capturing users' dynamic preferences by leveraging their interaction histories. Most existing SR systems assign a single embedding vector to each item to represent its features, and various types of models are adopted to combine these item embeddings into a sequence representation vector to capture the user intent. However, we argue that this representation alone is insufficient to capture an item's multi-faceted nature (e.g., movie genres, starring actors). Besides, users often exhibit complex and varied preferences within these facets (e.g., liking both action and musical films in the facet of genre), which are challenging to fully represent. To address the issues above, we propose a novel structure called Facet-Aware Multi-Head Mixture-of-Experts Model for Sequential Recommendation (FAME). We leverage sub-embeddings from each head in the last multi-head attention layer to predict the next item separately. This approach captures the potential multi-faceted nature of items without increasing model complexity. A gating mechanism integrates recommendations from each head and dynamically determines their importance. Furthermore, we introduce a Mixture-of-Experts (MoE) network in each attention head to disentangle various user preferences within each facet. Each expert within the MoE focuses on a specific preference. A learnable router network is adopted to compute the importance weight for each expert and aggregate them. We conduct extensive experiments on four public sequential recommendation datasets and the results demonstrate the effectiveness of our method over existing baseline models.
Mask-based Membership Inference Attacks for Retrieval-Augmented Generation
Oct 26, 2024
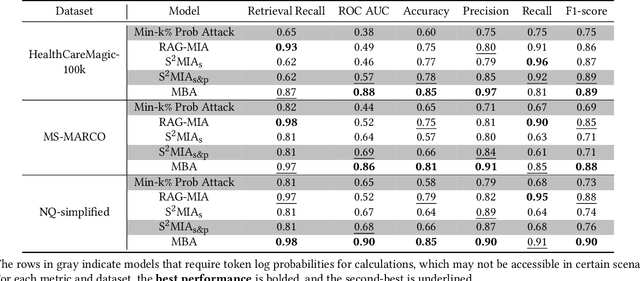
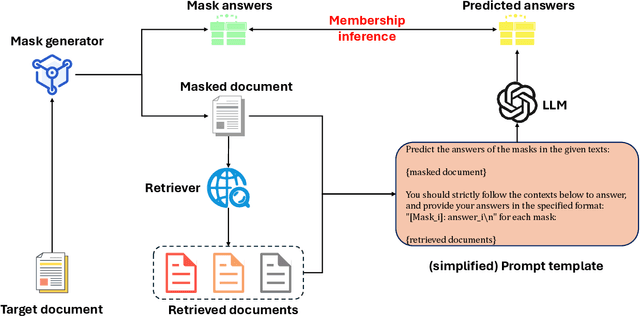
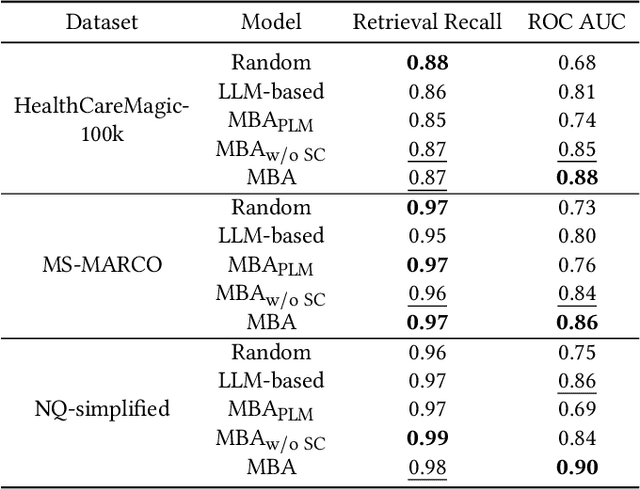
Retrieval-Augmented Generation (RAG) has been an effective approach to mitigate hallucinations in large language models (LLMs) by incorporating up-to-date and domain-specific knowledge. Recently, there has been a trend of storing up-to-date or copyrighted data in RAG knowledge databases instead of using it for LLM training. This practice has raised concerns about Membership Inference Attacks (MIAs), which aim to detect if a specific target document is stored in the RAG system's knowledge database so as to protect the rights of data producers. While research has focused on enhancing the trustworthiness of RAG systems, existing MIAs for RAG systems remain largely insufficient. Previous work either relies solely on the RAG system's judgment or is easily influenced by other documents or the LLM's internal knowledge, which is unreliable and lacks explainability. To address these limitations, we propose a Mask-Based Membership Inference Attacks (MBA) framework. Our framework first employs a masking algorithm that effectively masks a certain number of words in the target document. The masked text is then used to prompt the RAG system, and the RAG system is required to predict the mask values. If the target document appears in the knowledge database, the masked text will retrieve the complete target document as context, allowing for accurate mask prediction. Finally, we adopt a simple yet effective threshold-based method to infer the membership of target document by analyzing the accuracy of mask prediction. Our mask-based approach is more document-specific, making the RAG system's generation less susceptible to distractions from other documents or the LLM's internal knowledge. Extensive experiments demonstrate the effectiveness of our approach compared to existing baseline models.
Attention Is Not the Only Choice: Counterfactual Reasoning for Path-Based Explainable Recommendation
Jan 11, 2024Compared with only pursuing recommendation accuracy, the explainability of a recommendation model has drawn more attention in recent years. Many graph-based recommendations resort to informative paths with the attention mechanism for the explanation. Unfortunately, these attention weights are intentionally designed for model accuracy but not explainability. Recently, some researchers have started to question attention-based explainability because the attention weights are unstable for different reproductions, and they may not always align with human intuition. Inspired by the counterfactual reasoning from causality learning theory, we propose a novel explainable framework targeting path-based recommendations, wherein the explainable weights of paths are learned to replace attention weights. Specifically, we design two counterfactual reasoning algorithms from both path representation and path topological structure perspectives. Moreover, unlike traditional case studies, we also propose a package of explainability evaluation solutions with both qualitative and quantitative methods. We conduct extensive experiments on three real-world datasets, the results of which further demonstrate the effectiveness and reliability of our method.
Defense Against Model Extraction Attacks on Recommender Systems
Oct 25, 2023



The robustness of recommender systems has become a prominent topic within the research community. Numerous adversarial attacks have been proposed, but most of them rely on extensive prior knowledge, such as all the white-box attacks or most of the black-box attacks which assume that certain external knowledge is available. Among these attacks, the model extraction attack stands out as a promising and practical method, involving training a surrogate model by repeatedly querying the target model. However, there is a significant gap in the existing literature when it comes to defending against model extraction attacks on recommender systems. In this paper, we introduce Gradient-based Ranking Optimization (GRO), which is the first defense strategy designed to counter such attacks. We formalize the defense as an optimization problem, aiming to minimize the loss of the protected target model while maximizing the loss of the attacker's surrogate model. Since top-k ranking lists are non-differentiable, we transform them into swap matrices which are instead differentiable. These swap matrices serve as input to a student model that emulates the surrogate model's behavior. By back-propagating the loss of the student model, we obtain gradients for the swap matrices. These gradients are used to compute a swap loss, which maximizes the loss of the student model. We conducted experiments on three benchmark datasets to evaluate the performance of GRO, and the results demonstrate its superior effectiveness in defending against model extraction attacks.
Generating Counterfactual Hard Negative Samples for Graph Contrastive Learning
Jul 01, 2022
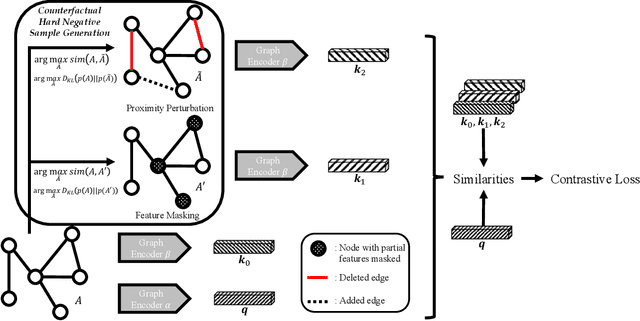
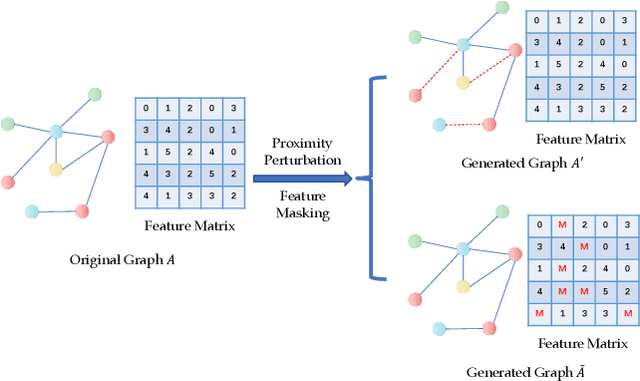
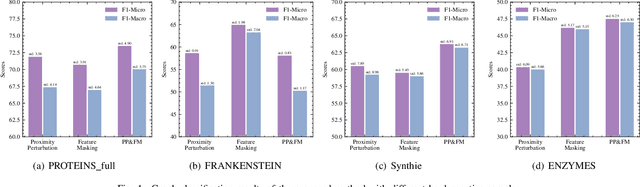
Graph contrastive learning has emerged as a powerful tool for unsupervised graph representation learning. The key to the success of graph contrastive learning is to acquire high-quality positive and negative samples as contrasting pairs for the purpose of learning underlying structural semantics of the input graph. Recent works usually sample negative samples from the same training batch with the positive samples, or from an external irrelevant graph. However, a significant limitation lies in such strategies, which is the unavoidable problem of sampling false negative samples. In this paper, we propose a novel method to utilize \textbf{C}ounterfactual mechanism to generate artificial hard negative samples for \textbf{G}raph \textbf{C}ontrastive learning, namely \textbf{CGC}, which has a different perspective compared to those sampling-based strategies. We utilize counterfactual mechanism to produce hard negative samples, which ensures that the generated samples are similar to, but have labels that different from the positive sample. The proposed method achieves satisfying results on several datasets compared to some traditional unsupervised graph learning methods and some SOTA graph contrastive learning methods. We also conduct some supplementary experiments to give an extensive illustration of the proposed method, including the performances of CGC with different hard negative samples and evaluations for hard negative samples generated with different similarity measurements.
Graph Masked Autoencoder
Feb 17, 2022
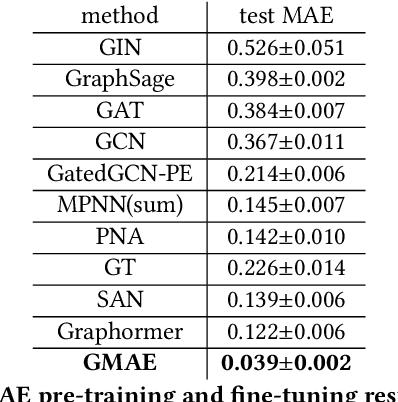
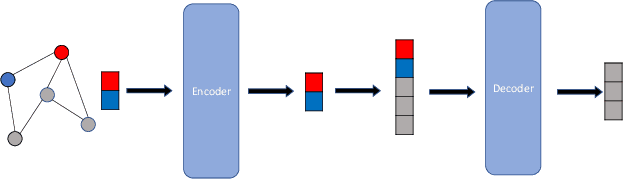
Transformers have achieved state-of-the-art performance in learning graph representations. However, there are still some challenges when applying transformers to real-world scenarios due to the fact that deep transformers are hard to be trained from scratch and the memory consumption is large. To address the two challenges, we propose Graph Masked Autoencoders (GMAE), a self-supervised model for learning graph representations, where vanilla graph transformers are used as the encoder and the decoder. GMAE takes partially masked graphs as input, and reconstructs the features of the masked nodes. We adopt asymmetric encoder-decoder design, where the encoder is a deep graph transformer and the decoder is a shallow graph transformer. The masking mechanism and the asymmetric design make GMAE a memory-efficient model compared with conventional transformers. We show that, compared with training from scratch, the graph transformer pre-trained using GMAE can achieve much better performance after fine-tuning. We also show that, when serving as a conventional self-supervised graph representation model and using an SVM model as the downstream graph classifier, GMAE achieves state-of-the-art performance on 5 of the 7 benchmark datasets.
Unsupervised Graph Poisoning Attack via Contrastive Loss Back-propagation
Jan 27, 2022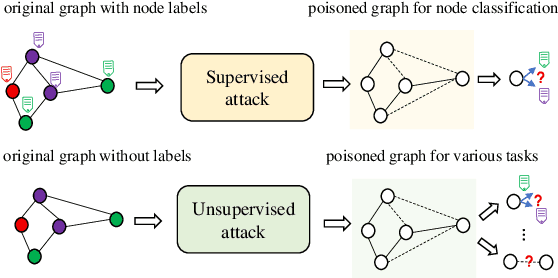
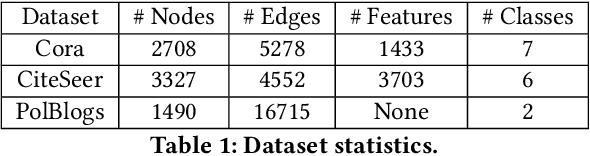
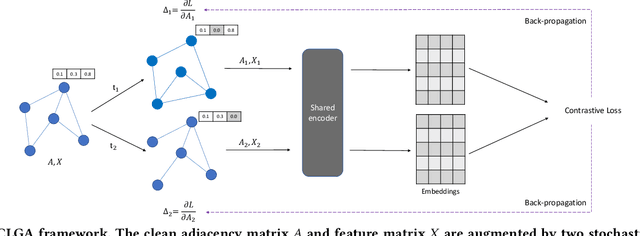
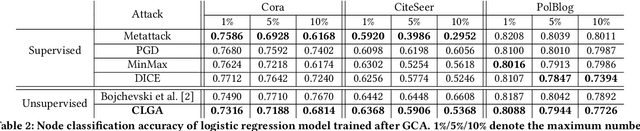
Graph contrastive learning is the state-of-the-art unsupervised graph representation learning framework and has shown comparable performance with supervised approaches. However, evaluating whether the graph contrastive learning is robust to adversarial attacks is still an open problem because most existing graph adversarial attacks are supervised models, which means they heavily rely on labels and can only be used to evaluate the graph contrastive learning in a specific scenario. For unsupervised graph representation methods such as graph contrastive learning, it is difficult to acquire labels in real-world scenarios, making traditional supervised graph attack methods difficult to be applied to test their robustness. In this paper, we propose a novel unsupervised gradient-based adversarial attack that does not rely on labels for graph contrastive learning. We compute the gradients of the adjacency matrices of the two views and flip the edges with gradient ascent to maximize the contrastive loss. In this way, we can fully use multiple views generated by the graph contrastive learning models and pick the most informative edges without knowing their labels, and therefore can promisingly support our model adapted to more kinds of downstream tasks. Extensive experiments show that our attack outperforms unsupervised baseline attacks and has comparable performance with supervised attacks in multiple downstream tasks including node classification and link prediction. We further show that our attack can be transferred to other graph representation models as well.