 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacet-Aware Multi-Head Mixture-of-Experts Model for Sequential Recommendation
Paper and Code
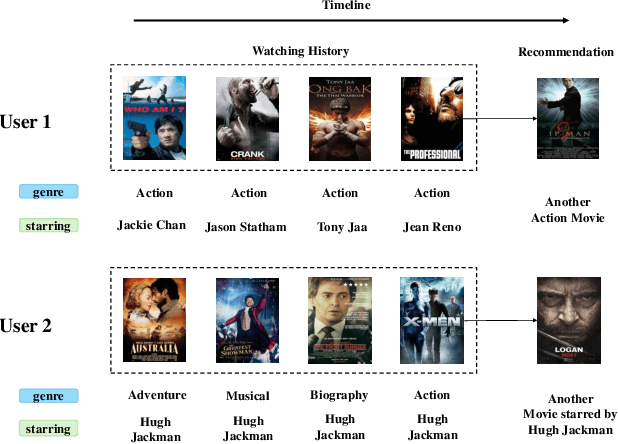
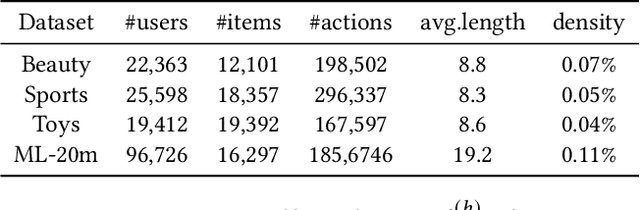
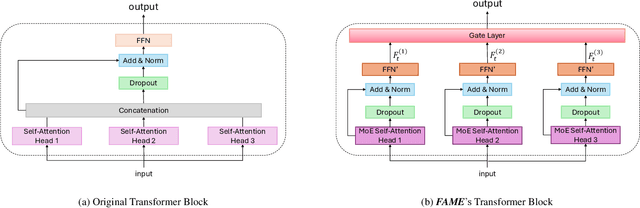
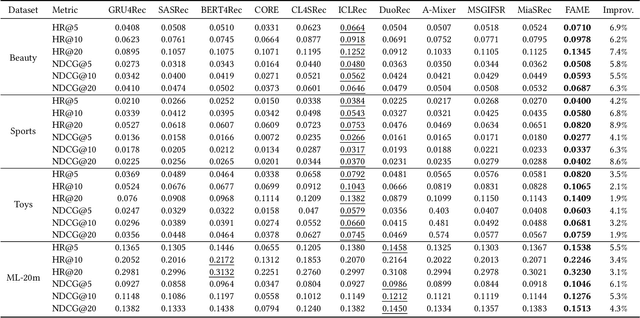
Sequential recommendation (SR) systems excel at capturing users' dynamic preferences by leveraging their interaction histories. Most existing SR systems assign a single embedding vector to each item to represent its features, and various types of models are adopted to combine these item embeddings into a sequence representation vector to capture the user intent. However, we argue that this representation alone is insufficient to capture an item's multi-faceted nature (e.g., movie genres, starring actors). Besides, users often exhibit complex and varied preferences within these facets (e.g., liking both action and musical films in the facet of genre), which are challenging to fully represent. To address the issues above, we propose a novel structure called Facet-Aware Multi-Head Mixture-of-Experts Model for Sequential Recommendation (FAME). We leverage sub-embeddings from each head in the last multi-head attention layer to predict the next item separately. This approach captures the potential multi-faceted nature of items without increasing model complexity. A gating mechanism integrates recommendations from each head and dynamically determines their importance. Furthermore, we introduce a Mixture-of-Experts (MoE) network in each attention head to disentangle various user preferences within each facet. Each expert within the MoE focuses on a specific preference. A learnable router network is adopted to compute the importance weight for each expert and aggregate them. We conduct extensive experiments on four public sequential recommendation datasets and the results demonstrate the effectiveness of our method over existing baseline models.