 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Masked Autoencoder
Paper and Code
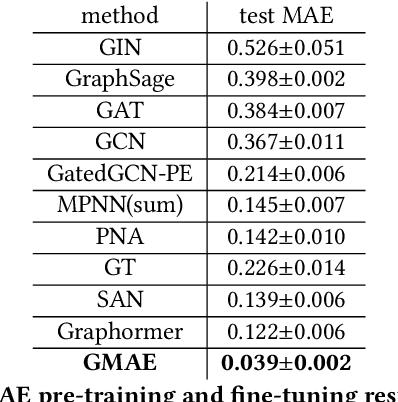
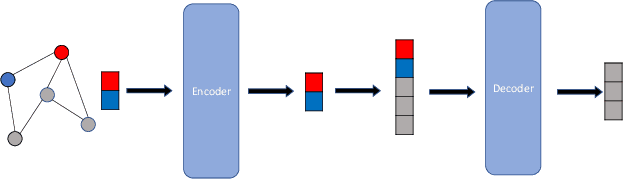
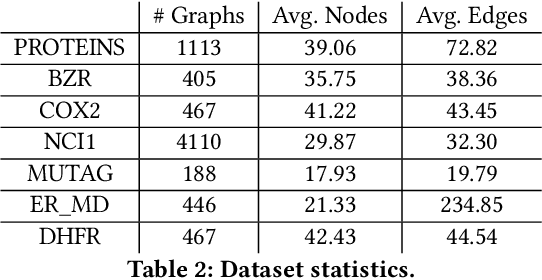
Transformers have achieved state-of-the-art performance in learning graph representations. However, there are still some challenges when applying transformers to real-world scenarios due to the fact that deep transformers are hard to be trained from scratch and the memory consumption is large. To address the two challenges, we propose Graph Masked Autoencoders (GMAE), a self-supervised model for learning graph representations, where vanilla graph transformers are used as the encoder and the decoder. GMAE takes partially masked graphs as input, and reconstructs the features of the masked nodes. We adopt asymmetric encoder-decoder design, where the encoder is a deep graph transformer and the decoder is a shallow graph transformer. The masking mechanism and the asymmetric design make GMAE a memory-efficient model compared with conventional transformers. We show that, compared with training from scratch, the graph transformer pre-trained using GMAE can achieve much better performance after fine-tuning. We also show that, when serving as a conventional self-supervised graph representation model and using an SVM model as the downstream graph classifier, GMAE achieves state-of-the-art performance on 5 of the 7 benchmark datasets.