 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edget-READi: Transformer-Powered Robust and Efficient Multimodal Inference for Autonomous Driving
Paper and Code
Oct 13, 2024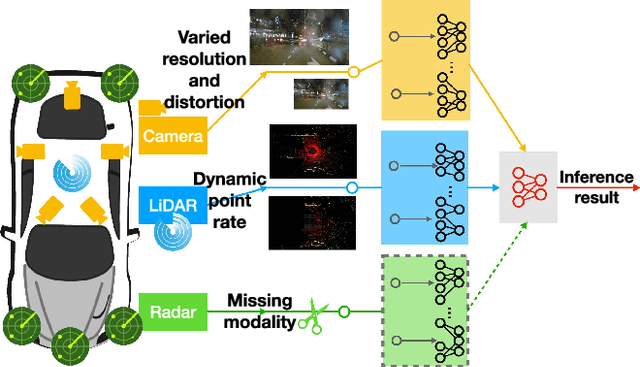
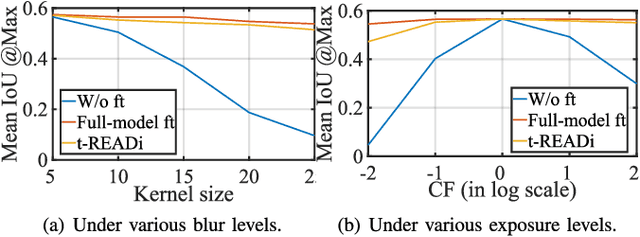
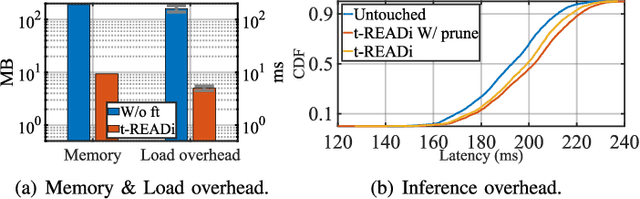
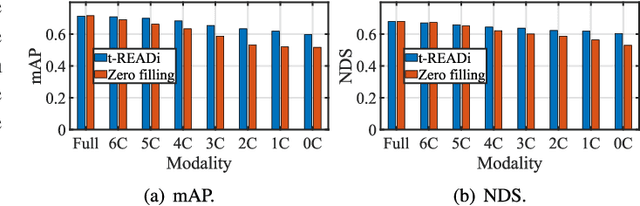
Given the wide adoption of multimodal sensors (e.g., camera, lidar, radar) by autonomous vehicles (AVs), deep analytics to fuse their outputs for a robust perception become imperative. However, existing fusion methods often make two assumptions rarely holding in practice: i) similar data distributions for all inputs and ii) constant availability for all sensors. Because, for example, lidars have various resolutions and failures of radars may occur, such variability often results in significant performance degradation in fusion. To this end, we present tREADi, an adaptive inference system that accommodates the variability of multimodal sensory data and thus enables robust and efficient perception. t-READi identifies variation-sensitive yet structure-specific model parameters; it then adapts only these parameters while keeping the rest intact. t-READi also leverages a cross-modality contrastive learning method to compensate for the loss from missing modalities. Both functions are implemented to maintain compatibility with existing multimodal deep fusion methods. The extensive experiments evidently demonstrate that compared with the status quo approaches, t-READi not only improves the average inference accuracy by more than 6% but also reduces the inference latency by almost 15x with the cost of only 5% extra memory overhead in the worst case under realistic data and modal variations.