 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanDrop: Simple and Effective Counterfactual Learning for Long Sequences
Paper and Code
Aug 03, 2022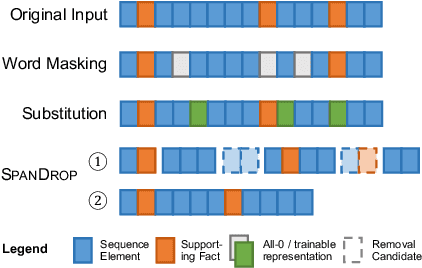
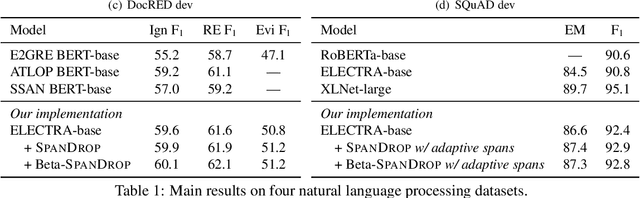
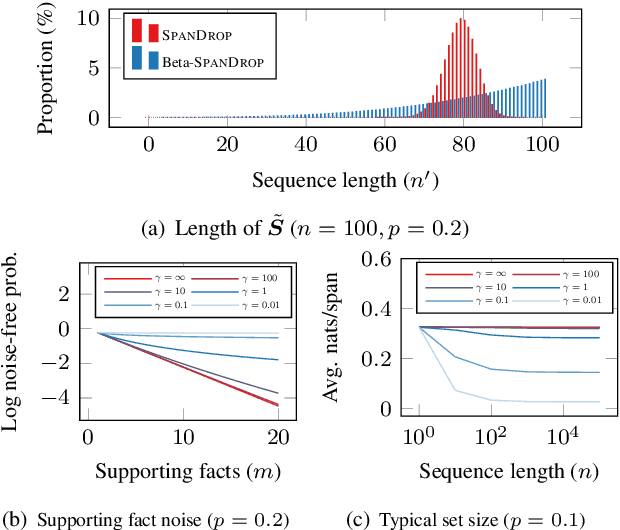
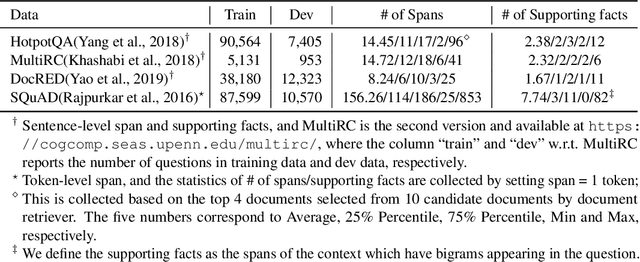
Distilling supervision signal from a long sequence to make predictions is a challenging task in machine learning, especially when not all elements in the input sequence contribute equally to the desired output. In this paper, we propose SpanDrop, a simple and effective data augmentation technique that helps models identify the true supervision signal in a long sequence with very few examples. By directly manipulating the input sequence, SpanDrop randomly ablates parts of the sequence at a time and ask the model to perform the same task to emulate counterfactual learning and achieve input attribution. Based on theoretical analysis of its properties, we also propose a variant of SpanDrop based on the beta-Bernoulli distribution, which yields diverse augmented sequences while providing a learning objective that is more consistent with the original dataset. We demonstrate the effectiveness of SpanDrop on a set of carefully designed toy tasks, as well as various natural language processing tasks that require reasoning over long sequences to arrive at the correct answer, and show that it helps models improve performance both when data is scarce and abundant.