 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022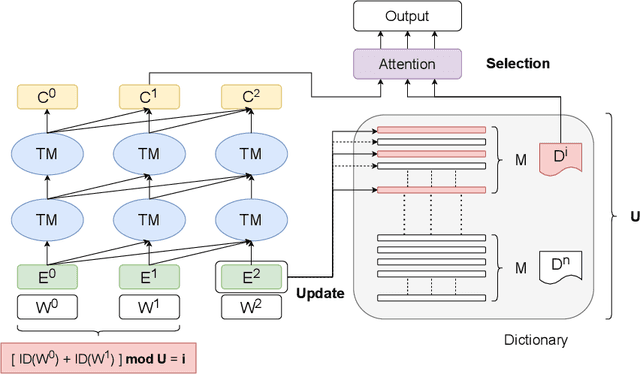
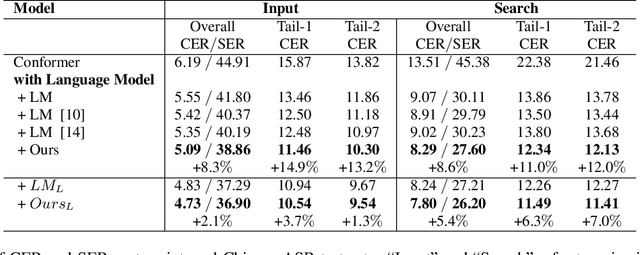
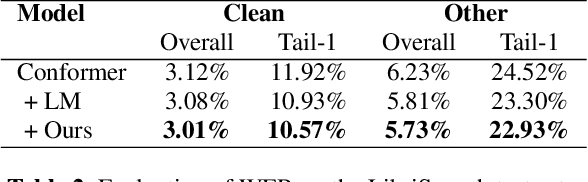
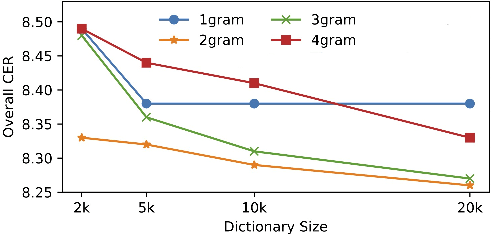
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
Learn To Remember: Transformer with Recurrent Memory for Document-Level Machine Translation
May 03, 2022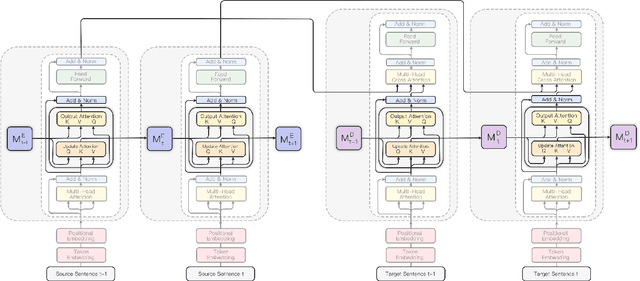
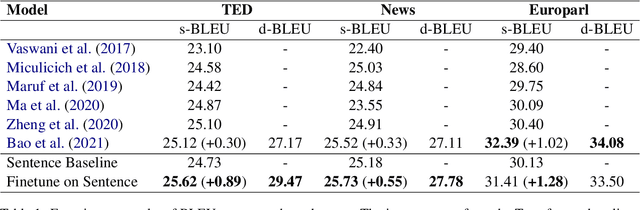


The Transformer architecture has led to significant gains in machine translation. However, most studies focus on only sentence-level translation without considering the context dependency within documents, leading to the inadequacy of document-level coherence. Some recent research tried to mitigate this issue by introducing an additional context encoder or translating with multiple sentences or even the entire document. Such methods may lose the information on the target side or have an increasing computational complexity as documents get longer. To address such problems, we introduce a recurrent memory unit to the vanilla Transformer, which supports the information exchange between the sentence and previous context. The memory unit is recurrently updated by acquiring information from sentences, and passing the aggregated knowledge back to subsequent sentence states. We follow a two-stage training strategy, in which the model is first trained at the sentence level and then finetuned for document-level translation. We conduct experiments on three popular datasets for document-level machine translation and our model has an average improvement of 0.91 s-BLEU over the sentence-level baseline. We also achieve state-of-the-art results on TED and News, outperforming the previous work by 0.36 s-BLEU and 1.49 d-BLEU on average.
The NLP Task Effectiveness of Long-Range Transformers
Feb 16, 2022
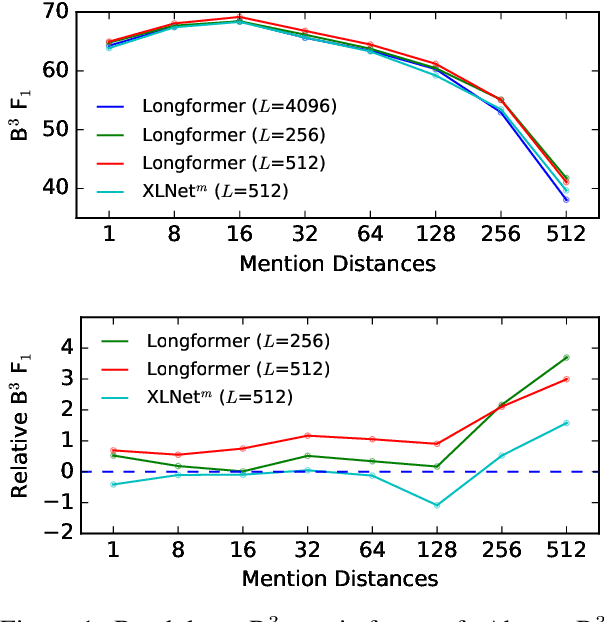


Transformer models cannot easily scale to long sequences due to their O(N^2) time and space complexity. This has led to Transformer variants seeking to lessen computational complexity, such as Longformer and Performer. While such models have theoretically greater efficiency, their effectiveness on real NLP tasks has not been well studied. We benchmark 7 variants of Transformer models on 5 difficult NLP tasks and 7 datasets. We design experiments to isolate the effect of pretraining and hyperparameter settings, to focus on their capacity for long-range attention. Moreover, we present various methods to investigate attention behaviors, to illuminate model details beyond metric scores. We find that attention of long-range transformers has advantages on content selection and query-guided decoding, but they come with previously unrecognized drawbacks such as insufficient attention to distant tokens.
Spiral Language Modeling
Dec 20, 2021

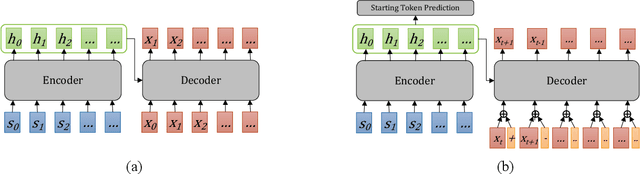
In almost all text generation applications, word sequences are constructed in a left-to-right (L2R) or right-to-left (R2L) manner, as natural language sentences are written either L2R or R2L. However, we find that the natural language written order is not essential for text generation. In this paper, we propose Spiral Language Modeling (SLM), a general approach that enables one to construct natural language sentences beyond the L2R and R2L order. SLM allows one to form natural language text by starting from an arbitrary token inside the result text and expanding the rest tokens around the selected ones. It makes the decoding order a new optimization objective besides the language model perplexity, which further improves the diversity and quality of the generated text. Furthermore, SLM makes it possible to manipulate the text construction process by selecting a proper starting token. SLM also introduces generation orderings as additional regularization to improve model robustness in low-resource scenarios. Experiments on 8 widely studied Neural Machine Translation (NMT) tasks show that SLM is constantly effective with up to 4.7 BLEU increase comparing to the conventional L2R decoding approach.