 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiral Language Modeling
Dec 20, 2021

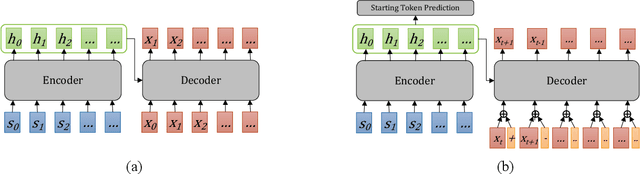
In almost all text generation applications, word sequences are constructed in a left-to-right (L2R) or right-to-left (R2L) manner, as natural language sentences are written either L2R or R2L. However, we find that the natural language written order is not essential for text generation. In this paper, we propose Spiral Language Modeling (SLM), a general approach that enables one to construct natural language sentences beyond the L2R and R2L order. SLM allows one to form natural language text by starting from an arbitrary token inside the result text and expanding the rest tokens around the selected ones. It makes the decoding order a new optimization objective besides the language model perplexity, which further improves the diversity and quality of the generated text. Furthermore, SLM makes it possible to manipulate the text construction process by selecting a proper starting token. SLM also introduces generation orderings as additional regularization to improve model robustness in low-resource scenarios. Experiments on 8 widely studied Neural Machine Translation (NMT) tasks show that SLM is constantly effective with up to 4.7 BLEU increase comparing to the conventional L2R decoding approach.
AR: Auto-Repair the Synthetic Data for Neural Machine Translation
Apr 05, 2020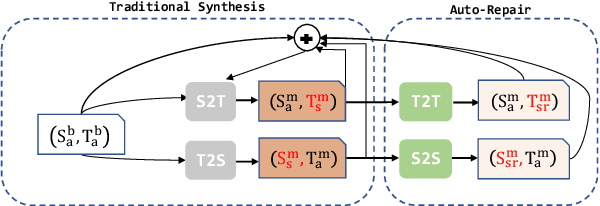
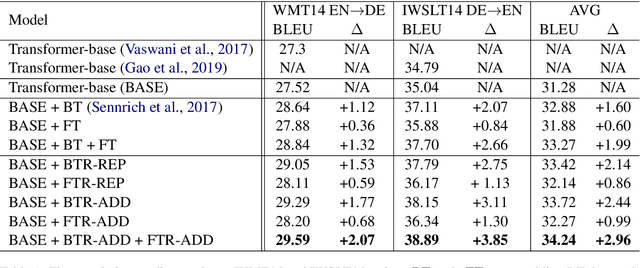
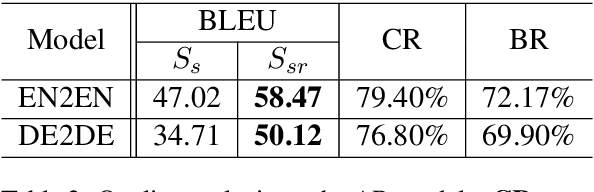
Compared with only using limited authentic parallel data as training corpus, many studies have proved that incorporating synthetic parallel data, which generated by back translation (BT) or forward translation (FT, or selftraining), into the NMT training process can significantly improve translation quality. However, as a well-known shortcoming, synthetic parallel data is noisy because they are generated by an imperfect NMT system. As a result, the improvements in translation quality bring by the synthetic parallel data are greatly diminished. In this paper, we propose a novel Auto- Repair (AR) framework to improve the quality of synthetic data. Our proposed AR model can learn the transformation from low quality (noisy) input sentence to high quality sentence based on large scale monolingual data with BT and FT techniques. The noise in synthetic parallel data will be sufficiently eliminated by the proposed AR model and then the repaired synthetic parallel data can help the NMT models to achieve larger improvements. Experimental results show that our approach can effective improve the quality of synthetic parallel data and the NMT model with the repaired synthetic data achieves consistent improvements on both WMT14 EN!DE and IWSLT14 DE!EN translation tasks.
Merging External Bilingual Pairs into Neural Machine Translation
Dec 02, 2019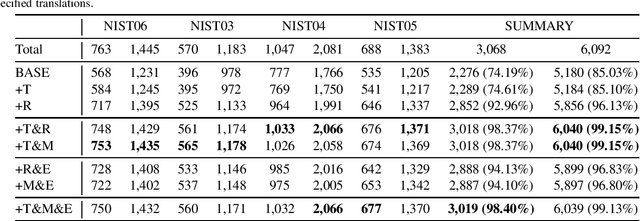
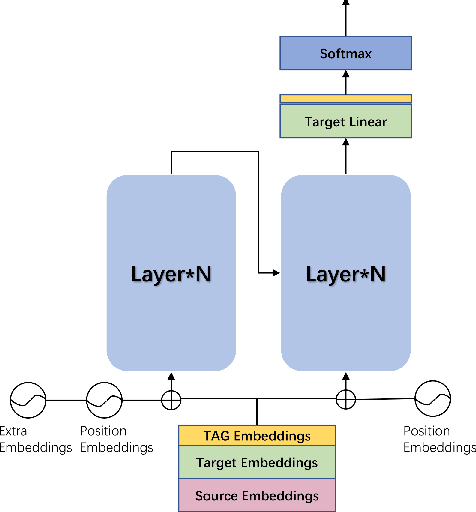
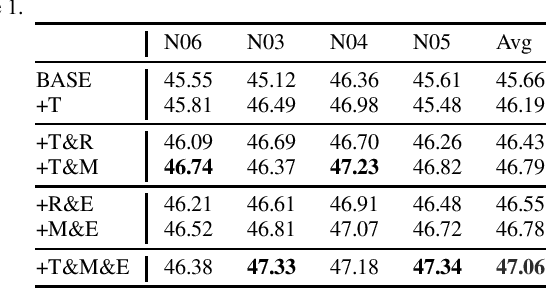

As neural machine translation (NMT) is not easily amenable to explicit correction of errors, incorporating pre-specified translations into NMT is widely regarded as a non-trivial challenge. In this paper, we propose and explore three methods to endow NMT with pre-specified bilingual pairs. Instead, for instance, of modifying the beam search algorithm during decoding or making complex modifications to the attention mechanism --- mainstream approaches to tackling this challenge ---, we experiment with the training data being appropriately pre-processed to add information about pre-specified translations. Extra embeddings are also used to distinguish pre-specified tokens from the other tokens. Extensive experimentation and analysis indicate that over 99% of the pre-specified phrases are successfully translated (given a 85% baseline) and that there is also a substantive improvement in translation quality with the methods explored here.
Learning to Reuse Translations: Guiding Neural Machine Translation with Examples
Nov 28, 2019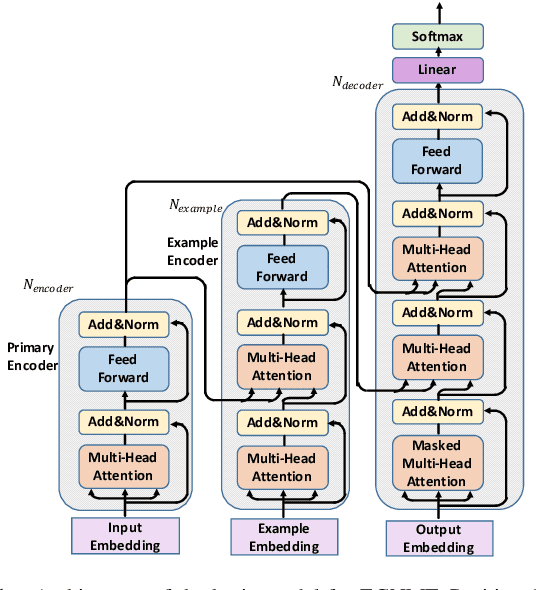
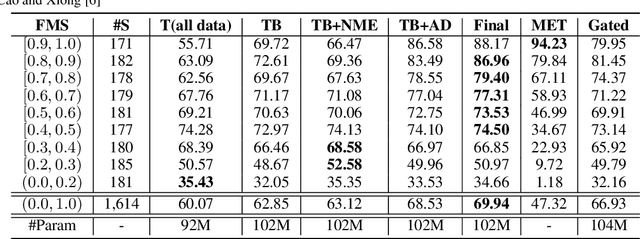
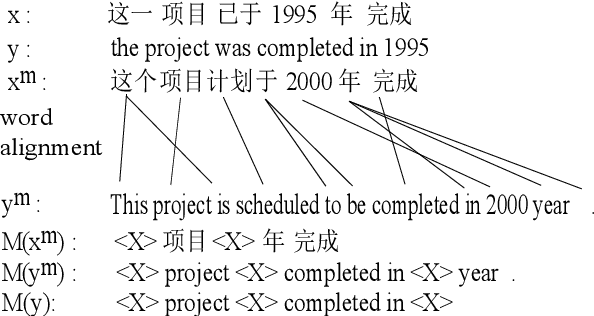

In this paper, we study the problem of enabling neural machine translation (NMT) to reuse previous translations from similar examples in target prediction. Distinguishing reusable translations from noisy segments and learning to reuse them in NMT are non-trivial. To solve these challenges, we propose an Example-Guided NMT (EGNMT) framework with two models: (1) a noise-masked encoder model that masks out noisy words according to word alignments and encodes the noise-masked sentences with an additional example encoder and (2) an auxiliary decoder model that predicts reusable words via an auxiliary decoder sharing parameters with the primary decoder. We define and implement the two models with the state-of-the-art Transformer. Experiments show that the noise-masked encoder model allows NMT to learn useful information from examples with low fuzzy match scores (FMS) while the auxiliary decoder model is good for high-FMS examples. More experiments on Chinese-English, English-German and English-Spanish translation demonstrate that the combination of the two EGNMT models can achieve improvements of up to +9 BLEU points over the baseline system and +7 BLEU points over a two-encoder Transformer.
Modeling Coherence for Neural Machine Translation with Dynamic and Topic Caches
Jun 14, 2018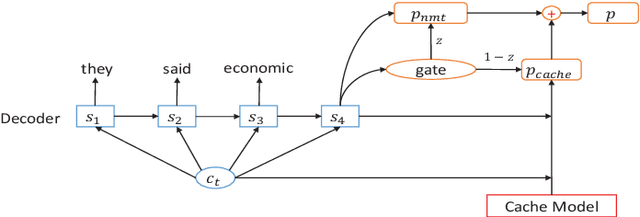
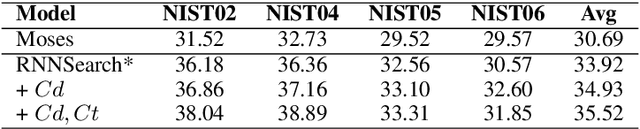

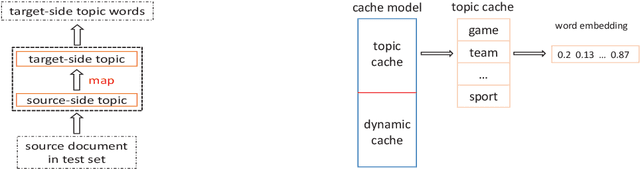
Sentences in a well-formed text are connected to each other via various links to form the cohesive structure of the text. Current neural machine translation (NMT) systems translate a text in a conventional sentence-by-sentence fashion, ignoring such cross-sentence links and dependencies. This may lead to generate an incoherent target text for a coherent source text. In order to handle this issue, we propose a cache-based approach to modeling coherence for neural machine translation by capturing contextual information either from recently translated sentences or the entire document. Particularly, we explore two types of caches: a dynamic cache, which stores words from the best translation hypotheses of preceding sentences, and a topic cache, which maintains a set of target-side topical words that are semantically related to the document to be translated. On this basis, we build a new layer to score target words in these two caches with a cache-based neural model. Here the estimated probabilities from the cache-based neural model are combined with NMT probabilities into the final word prediction probabilities via a gating mechanism. Finally, the proposed cache-based neural model is trained jointly with NMT system in an end-to-end manner. Experiments and analysis presented in this paper demonstrate that the proposed cache-based model achieves substantial improvements over several state-of-the-art SMT and NMT baselines.
Fusing Recency into Neural Machine Translation with an Inter-Sentence Gate Model
Jun 12, 2018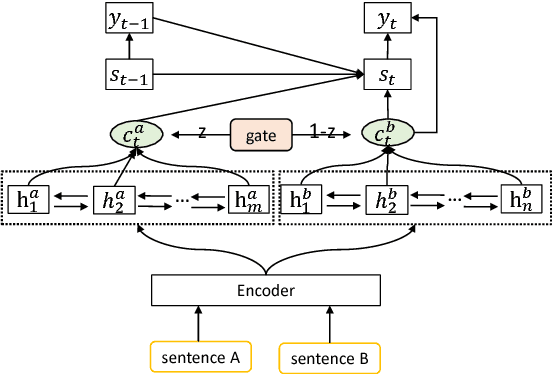

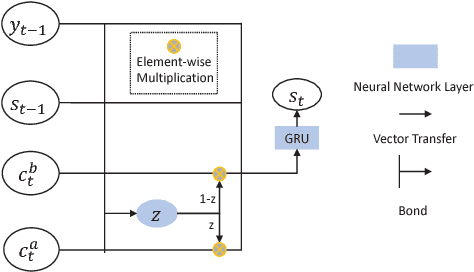

Neural machine translation (NMT) systems are usually trained on a large amount of bilingual sentence pairs and translate one sentence at a time, ignoring inter-sentence information. This may make the translation of a sentence ambiguous or even inconsistent with the translations of neighboring sentences. In order to handle this issue, we propose an inter-sentence gate model that uses the same encoder to encode two adjacent sentences and controls the amount of information flowing from the preceding sentence to the translation of the current sentence with an inter-sentence gate. In this way, our proposed model can capture the connection between sentences and fuse recency from neighboring sentences into neural machine translation. On several NIST Chinese-English translation tasks, our experiments demonstrate that the proposed inter-sentence gate model achieves substantial improvements over the baseline.
Attention Focusing for Neural Machine Translation by Bridging Source and Target Embeddings
May 10, 2018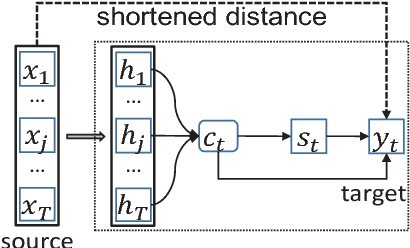
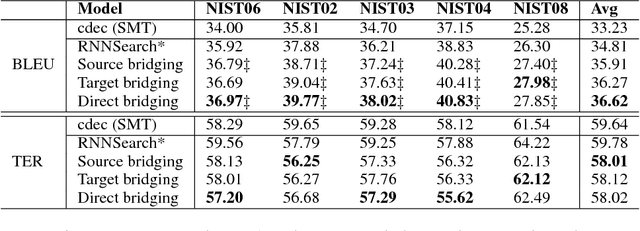


In neural machine translation, a source sequence of words is encoded into a vector from which a target sequence is generated in the decoding phase. Differently from statistical machine translation, the associations between source words and their possible target counterparts are not explicitly stored. Source and target words are at the two ends of a long information processing procedure, mediated by hidden states at both the source encoding and the target decoding phases. This makes it possible that a source word is incorrectly translated into a target word that is not any of its admissible equivalent counterparts in the target language. In this paper, we seek to somewhat shorten the distance between source and target words in that procedure, and thus strengthen their association, by means of a method we term bridging source and target word embeddings. We experiment with three strategies: (1) a source-side bridging model, where source word embeddings are moved one step closer to the output target sequence; (2) a target-side bridging model, which explores the more relevant source word embeddings for the prediction of the target sequence; and (3) a direct bridging model, which directly connects source and target word embeddings seeking to minimize errors in the translation of ones by the others. Experiments and analysis presented in this paper demonstrate that the proposed bridging models are able to significantly improve quality of both sentence translation, in general, and alignment and translation of individual source words with target words, in particular.
Apply Chinese Radicals Into Neural Machine Translation: Deeper Than Character Level
May 08, 2018



In neural machine translation (NMT), researchers face the challenge of un-seen (or out-of-vocabulary OOV) words translation. To solve this, some researchers propose the splitting of western languages such as English and German into sub-words or compounds. In this paper, we try to address this OOV issue and improve the NMT adequacy with a harder language Chinese whose characters are even more sophisticated in composition. We integrate the Chinese radicals into the NMT model with different settings to address the unseen words challenge in Chinese to English translation. On the other hand, this also can be considered as semantic part of the MT system since the Chinese radicals usually carry the essential meaning of the words they are constructed in. Meaningful radicals and new characters can be integrated into the NMT systems with our models. We use an attention-based NMT system as a strong baseline system. The experiments on standard Chinese-to-English NIST translation shared task data 2006 and 2008 show that our designed models outperform the baseline model in a wide range of state-of-the-art evaluation metrics including LEPOR, BEER, and CharacTER, in addition to the traditional BLEU and NIST scores, especially on the adequacy-level translation. We also have some interesting findings from the results of our various experiment settings about the performance of words and characters in Chinese NMT, which is different with other languages. For instance, the full character level NMT may perform very well or the state of the art in some other languages as researchers demonstrated recently, however, in the Chinese NMT model, word boundary knowledge is important for the model learning.