 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging External Bilingual Pairs into Neural Machine Translation
Paper and Code
Dec 02, 2019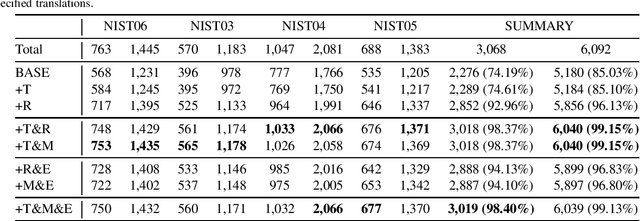
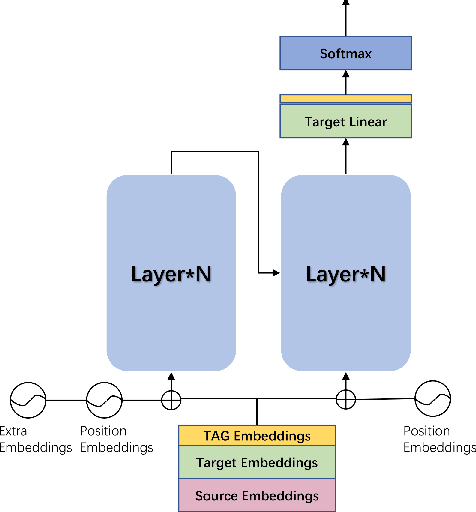
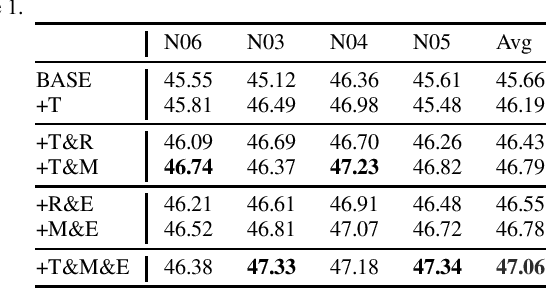

As neural machine translation (NMT) is not easily amenable to explicit correction of errors, incorporating pre-specified translations into NMT is widely regarded as a non-trivial challenge. In this paper, we propose and explore three methods to endow NMT with pre-specified bilingual pairs. Instead, for instance, of modifying the beam search algorithm during decoding or making complex modifications to the attention mechanism --- mainstream approaches to tackling this challenge ---, we experiment with the training data being appropriately pre-processed to add information about pre-specified translations. Extra embeddings are also used to distinguish pre-specified tokens from the other tokens. Extensive experimentation and analysis indicate that over 99% of the pre-specified phrases are successfully translated (given a 85% baseline) and that there is also a substantive improvement in translation quality with the methods explored here.