 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Neural Machine Translation with Consistency-Aware Meta-Learning
Mar 20, 2023



Neural machine translation (NMT) has achieved remarkable success in producing high-quality translations. However, current NMT systems suffer from a lack of reliability, as their outputs that are often affected by lexical or syntactic changes in inputs, resulting in large variations in quality. This limitation hinders the practicality and trustworthiness of NMT. A contributing factor to this problem is that NMT models trained with the one-to-one paradigm struggle to handle the source diversity phenomenon, where inputs with the same meaning can be expressed differently. In this work, we treat this problem as a bilevel optimization problem and present a consistency-aware meta-learning (CAML) framework derived from the model-agnostic meta-learning (MAML) algorithm to address it. Specifically, the NMT model with CAML (named CoNMT) first learns a consistent meta representation of semantically equivalent sentences in the outer loop. Subsequently, a mapping from the meta representation to the output sentence is learned in the inner loop, allowing the NMT model to translate semantically equivalent sentences to the same target sentence. We conduct experiments on the NIST Chinese to English task, three WMT translation tasks, and the TED M2O task. The results demonstrate that CoNMT effectively improves overall translation quality and reliably handles diverse inputs.
AR: Auto-Repair the Synthetic Data for Neural Machine Translation
Apr 05, 2020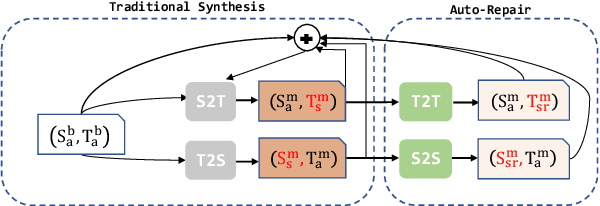
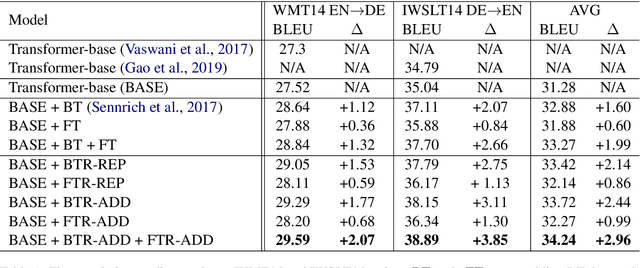
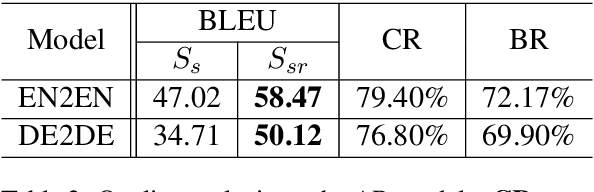
Compared with only using limited authentic parallel data as training corpus, many studies have proved that incorporating synthetic parallel data, which generated by back translation (BT) or forward translation (FT, or selftraining), into the NMT training process can significantly improve translation quality. However, as a well-known shortcoming, synthetic parallel data is noisy because they are generated by an imperfect NMT system. As a result, the improvements in translation quality bring by the synthetic parallel data are greatly diminished. In this paper, we propose a novel Auto- Repair (AR) framework to improve the quality of synthetic data. Our proposed AR model can learn the transformation from low quality (noisy) input sentence to high quality sentence based on large scale monolingual data with BT and FT techniques. The noise in synthetic parallel data will be sufficiently eliminated by the proposed AR model and then the repaired synthetic parallel data can help the NMT models to achieve larger improvements. Experimental results show that our approach can effective improve the quality of synthetic parallel data and the NMT model with the repaired synthetic data achieves consistent improvements on both WMT14 EN!DE and IWSLT14 DE!EN translation tasks.