 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence rates for pretraining and dropout: Guiding learning parameters using network structure
Paper and Code
Feb 22, 2017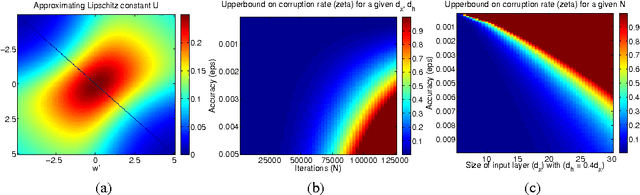



Unsupervised pretraining and dropout have been well studied, especially with respect to regularization and output consistency. However, our understanding about the explicit convergence rates of the parameter estimates, and their dependence on the learning (like denoising and dropout rate) and structural (like depth and layer lengths) aspects of the network is less mature. An interesting question in this context is to ask if the network structure could "guide" the choices of such learning parameters. In this work, we explore these gaps between network structure, the learning mechanisms and their interaction with parameter convergence rates. We present a way to address these issues based on the backpropagation convergence rates for general nonconvex objectives using first-order information. We then incorporate two learning mechanisms into this general framework -- denoising autoencoder and dropout, and subsequently derive the convergence rates of deep networks. Building upon these bounds, we provide insights into the choices of learning parameters and network sizes that achieve certain levels of convergence accuracy. The results derived here support existing empirical observations, and we also conduct a set of experiments to evaluate them.