 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations
Apr 12, 2025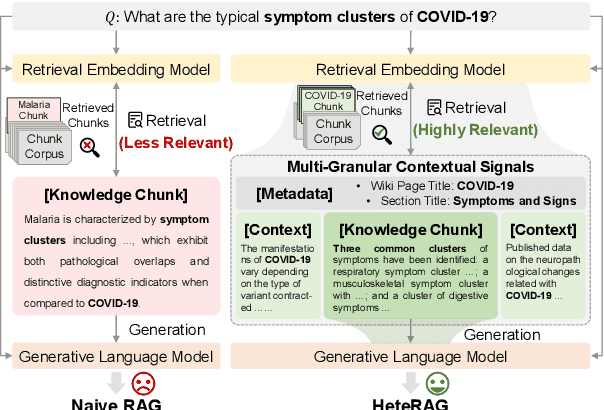

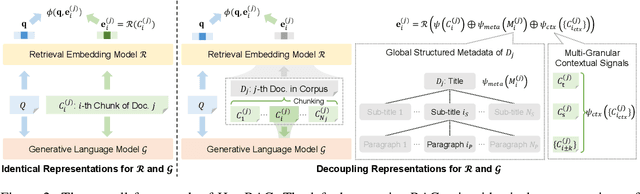

Retrieval-augmented generation (RAG) methods can enhance the performance of LLMs by incorporating retrieved knowledge chunks into the generation process. In general, the retrieval and generation steps usually have different requirements for these knowledge chunks. The retrieval step benefits from comprehensive information to improve retrieval accuracy, whereas excessively long chunks may introduce redundant contextual information, thereby diminishing both the effectiveness and efficiency of the generation process. However, existing RAG methods typically employ identical representations of knowledge chunks for both retrieval and generation, resulting in suboptimal performance. In this paper, we propose a heterogeneous RAG framework (\myname) that decouples the representations of knowledge chunks for retrieval and generation, thereby enhancing the LLMs in both effectiveness and efficiency. Specifically, we utilize short chunks to represent knowledge to adapt the generation step and utilize the corresponding chunk with its contextual information from multi-granular views to enhance retrieval accuracy. We further introduce an adaptive prompt tuning method for the retrieval model to adapt the heterogeneous retrieval augmented generation process. Extensive experiments demonstrate that \myname achieves significant improvements compared to baselines.
InferTurbo: A Scalable System for Boosting Full-graph Inference of Graph Neural Network over Huge Graphs
Jul 01, 2023GNN inference is a non-trivial task, especially in industrial scenarios with giant graphs, given three main challenges, i.e., scalability tailored for full-graph inference on huge graphs, inconsistency caused by stochastic acceleration strategies (e.g., sampling), and the serious redundant computation issue. To address the above challenges, we propose a scalable system named InferTurbo to boost the GNN inference tasks in industrial scenarios. Inspired by the philosophy of ``think-like-a-vertex", a GAS-like (Gather-Apply-Scatter) schema is proposed to describe the computation paradigm and data flow of GNN inference. The computation of GNNs is expressed in an iteration manner, in which a vertex would gather messages via in-edges and update its state information by forwarding an associated layer of GNNs with those messages and then send the updated information to other vertexes via out-edges. Following the schema, the proposed InferTurbo can be built with alternative backends (e.g., batch processing system or graph computing system). Moreover, InferTurbo introduces several strategies like shadow-nodes and partial-gather to handle nodes with large degrees for better load balancing. With InferTurbo, GNN inference can be hierarchically conducted over the full graph without sampling and redundant computation. Experimental results demonstrate that our system is robust and efficient for inference tasks over graphs containing some hub nodes with many adjacent edges. Meanwhile, the system gains a remarkable performance compared with the traditional inference pipeline, and it can finish a GNN inference task over a graph with tens of billions of nodes and hundreds of billions of edges within 2 hours.
KGNN: Distributed Framework for Graph Neural Knowledge Representation
May 17, 2022
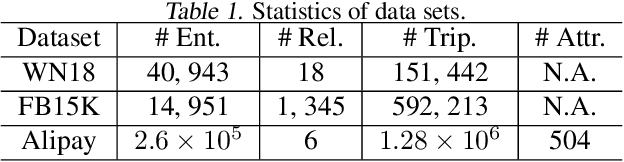
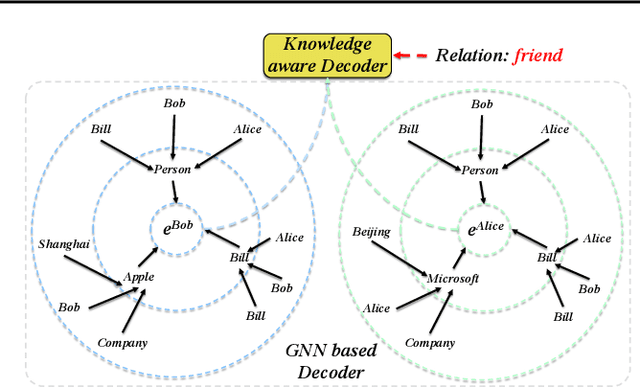
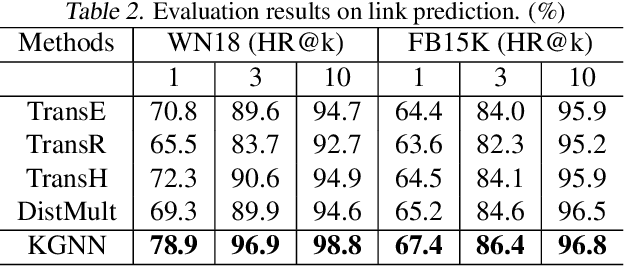
Knowledge representation learning has been commonly adopted to incorporate knowledge graph (KG) into various online services. Although existing knowledge representation learning methods have achieved considerable performance improvement, they ignore high-order structure and abundant attribute information, resulting unsatisfactory performance on semantics-rich KGs. Moreover, they fail to make prediction in an inductive manner and cannot scale to large industrial graphs. To address these issues, we develop a novel framework called KGNN to take full advantage of knowledge data for representation learning in the distributed learning system. KGNN is equipped with GNN based encoder and knowledge aware decoder, which aim to jointly explore high-order structure and attribute information together in a fine-grained fashion and preserve the relation patterns in KGs, respectively. Extensive experiments on three datasets for link prediction and triplet classification task demonstrate the effectiveness and scalability of KGNN framework.