 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Operator Learning from Limited Data on Irregular Domains
May 25, 2025Operator learning seeks to approximate mappings from input functions to output solutions, particularly in the context of partial differential equations (PDEs). While recent advances such as DeepONet and Fourier Neural Operator (FNO) have demonstrated strong performance, they often rely on regular grid discretizations, limiting their applicability to complex or irregular domains. In this work, we propose a Graph-based Operator Learning with Attention (GOLA) framework that addresses this limitation by constructing graphs from irregularly sampled spatial points and leveraging attention-enhanced Graph Neural Netwoks (GNNs) to model spatial dependencies with global information. To improve the expressive capacity, we introduce a Fourier-based encoder that projects input functions into a frequency space using learnable complex coefficients, allowing for flexible embeddings even with sparse or nonuniform samples. We evaluated our approach across a range of 2D PDEs, including Darcy Flow, Advection, Eikonal, and Nonlinear Diffusion, under varying sampling densities. Our method consistently outperforms baselines, particularly in data-scarce regimes, demonstrating strong generalization and efficiency on irregular domains.
Pseudo-Physics-Informed Neural Operators: Enhancing Operator Learning from Limited Data
Feb 04, 2025



Neural operators have shown great potential in surrogate modeling. However, training a well-performing neural operator typically requires a substantial amount of data, which can pose a major challenge in complex applications. In such scenarios, detailed physical knowledge can be unavailable or difficult to obtain, and collecting extensive data is often prohibitively expensive. To mitigate this challenge, we propose the Pseudo Physics-Informed Neural Operator (PPI-NO) framework. PPI-NO constructs a surrogate physics system for the target system using partial differential equations (PDEs) derived from simple, rudimentary physics principles, such as basic differential operators. This surrogate system is coupled with a neural operator model, using an alternating update and learning process to iteratively enhance the model's predictive power. While the physics derived via PPI-NO may not mirror the ground-truth underlying physical laws -- hence the term ``pseudo physics'' -- this approach significantly improves the accuracy of standard operator learning models in data-scarce scenarios, which is evidenced by extensive evaluations across five benchmark tasks and a fatigue modeling application.
Communication-Efficient Actor-Critic Methods for Homogeneous Markov Games
Feb 18, 2022
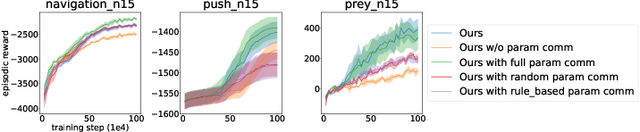
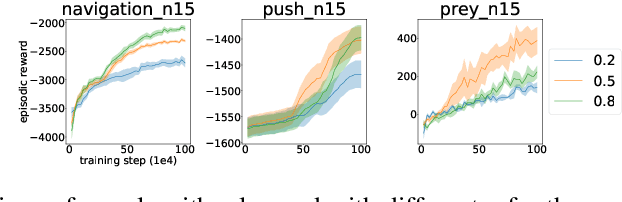
Recent success in cooperative multi-agent reinforcement learning (MARL) relies on centralized training and policy sharing. Centralized training eliminates the issue of non-stationarity MARL yet induces large communication costs, and policy sharing is empirically crucial to efficient learning in certain tasks yet lacks theoretical justification. In this paper, we formally characterize a subclass of cooperative Markov games where agents exhibit a certain form of homogeneity such that policy sharing provably incurs no suboptimality. This enables us to develop the first consensus-based decentralized actor-critic method where the consensus update is applied to both the actors and the critics while ensuring convergence. We also develop practical algorithms based on our decentralized actor-critic method to reduce the communication cost during training, while still yielding policies comparable with centralized training.
Reinforcement Learning based Path Exploration for Sequential Explainable Recommendation
Nov 24, 2021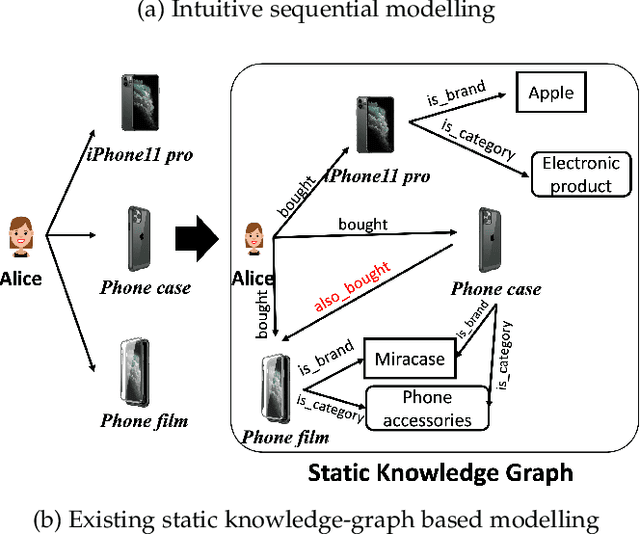
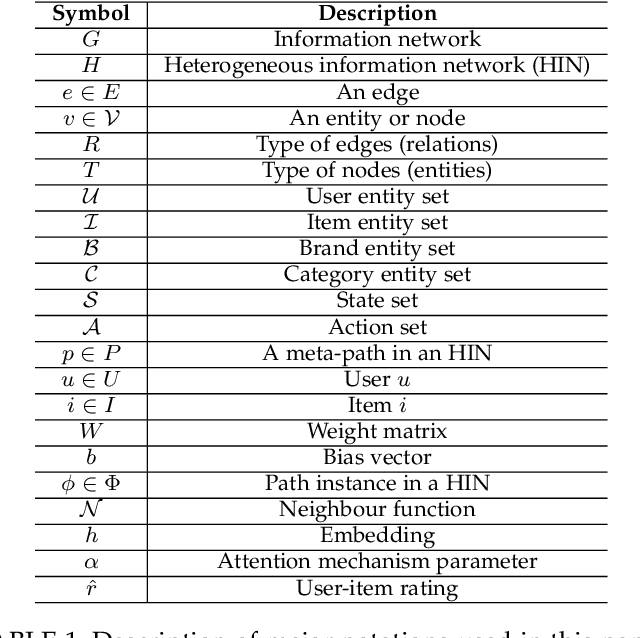
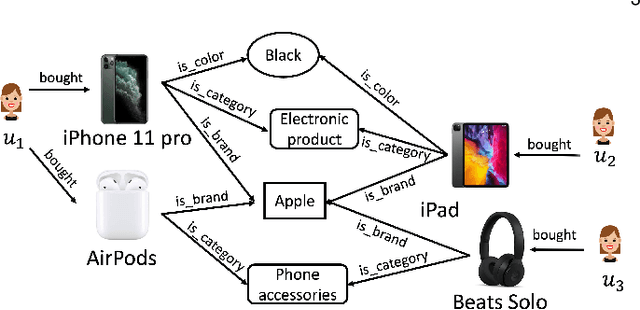
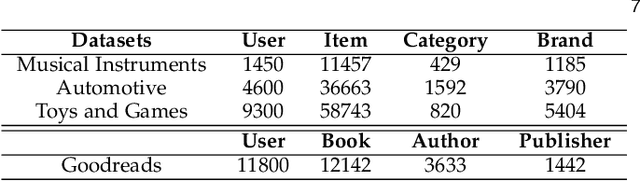
Recent advances in path-based explainable recommendation systems have attracted increasing attention thanks to the rich information provided by knowledge graphs. Most existing explainable recommendations only utilize static knowledge graphs and ignore the dynamic user-item evolutions, leading to less convincing and inaccurate explanations. Although there are some works that realize that modelling user's temporal sequential behaviour could boost the performance and explainability of the recommender systems, most of them either only focus on modelling user's sequential interactions within a path or independently and separately of the recommendation mechanism. In this paper, we propose a novel Temporal Meta-path Guided Explainable Recommendation leveraging Reinforcement Learning (TMER-RL), which utilizes reinforcement item-item path modelling between consecutive items with attention mechanisms to sequentially model dynamic user-item evolutions on dynamic knowledge graph for explainable recommendation. Compared with existing works that use heavy recurrent neural networks to model temporal information, we propose simple but effective neural networks to capture users' historical item features and path-based context to characterize the next purchased item. Extensive evaluations of TMER on two real-world datasets show state-of-the-art performance compared against recent strong baselines.