 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic landslide susceptibility mapping over recent three decades to uncover variations in landslide causes in subtropical urban mountainous areas
Aug 23, 2023



Landslide susceptibility assessment (LSA) is of paramount importance in mitigating landslide risks. Recently, there has been a surge in the utilization of data-driven methods for predicting landslide susceptibility due to the growing availability of aerial and satellite data. Nonetheless, the rapid oscillations within the landslide-inducing environment (LIE), primarily due to significant changes in external triggers such as rainfall, pose difficulties for contemporary data-driven LSA methodologies to accommodate LIEs over diverse timespans. This study presents dynamic landslide susceptibility mapping that simply employs multiple predictive models for annual LSA. In practice, this will inevitably encounter small sample problems due to the limited number of landslide samples in certain years. Another concern arises owing to the majority of the existing LSA approaches train black-box models to fit distinct datasets, yet often failing in generalization and providing comprehensive explanations concerning the interactions between input features and predictions. Accordingly, we proposed to meta-learn representations with fast adaptation ability using a few samples and gradient updates; and apply SHAP for each model interpretation and landslide feature permutation. Additionally, we applied MT-InSAR for LSA result enhancement and validation. The chosen study area is Lantau Island, Hong Kong, where we conducted a comprehensive dynamic LSA spanning from 1992 to 2019. The model interpretation results demonstrate that the primary factors responsible for triggering landslides in Lantau Island are terrain slope and extreme rainfall. The results also indicate that the variation in landslide causes can be primarily attributed to extreme rainfall events, which result from global climate change, and the implementation of the Landslip Prevention and Mitigation Programme (LPMitP) by the Hong Kong government.
BCE-Net: Reliable Building Footprints Change Extraction based on Historical Map and Up-to-Date Images using Contrastive Learning
Apr 14, 2023



Automatic and periodic recompiling of building databases with up-to-date high-resolution images has become a critical requirement for rapidly developing urban environments. However, the architecture of most existing approaches for change extraction attempts to learn features related to changes but ignores objectives related to buildings. This inevitably leads to the generation of significant pseudo-changes, due to factors such as seasonal changes in images and the inclination of building fa\c{c}ades. To alleviate the above-mentioned problems, we developed a contrastive learning approach by validating historical building footprints against single up-to-date remotely sensed images. This contrastive learning strategy allowed us to inject the semantics of buildings into a pipeline for the detection of changes, which is achieved by increasing the distinguishability of features of buildings from those of non-buildings. In addition, to reduce the effects of inconsistencies between historical building polygons and buildings in up-to-date images, we employed a deformable convolutional neural network to learn offsets intuitively. In summary, we formulated a multi-branch building extraction method that identifies newly constructed and removed buildings, respectively. To validate our method, we conducted comparative experiments using the public Wuhan University building change detection dataset and a more practical dataset named SI-BU that we established. Our method achieved F1 scores of 93.99% and 70.74% on the above datasets, respectively. Moreover, when the data of the public dataset were divided in the same manner as in previous related studies, our method achieved an F1 score of 94.63%, which surpasses that of the state-of-the-art method.
Semi-Supervised Adversarial Recognition of Refined Window Structures for Inverse Procedural Façade Modeling
Jan 22, 2022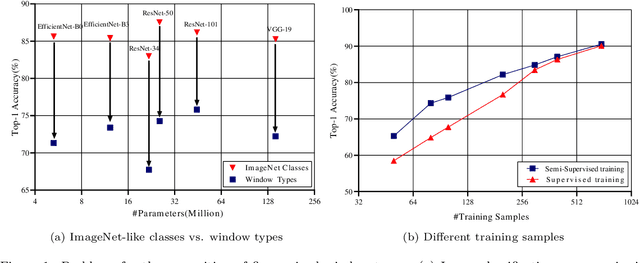

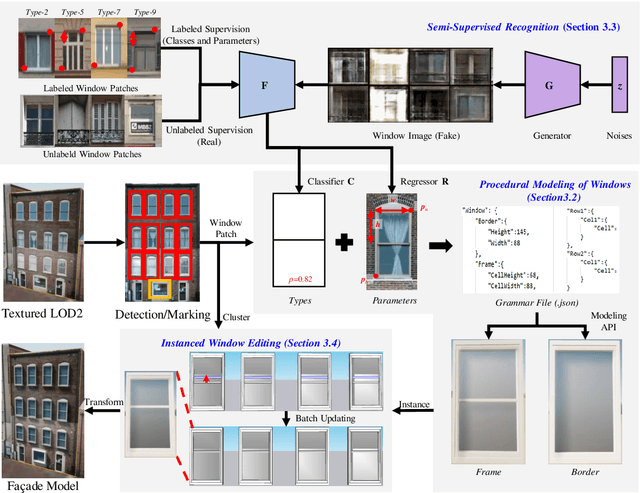
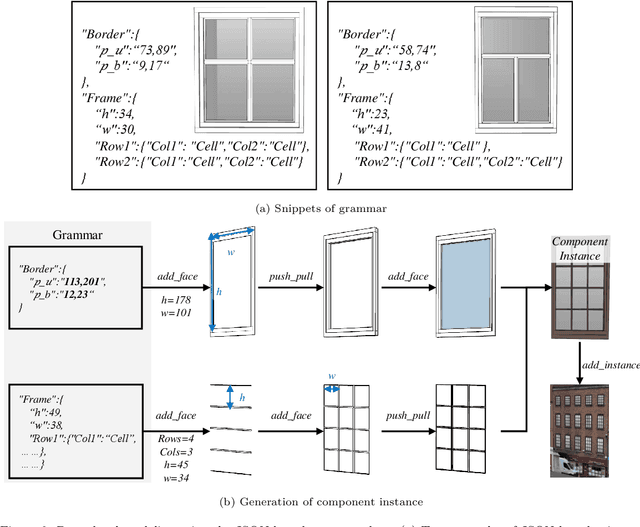
Deep learning methods are notoriously data-hungry, which requires a large number of labeled samples. Unfortunately, the large amount of interactive sample labeling efforts has dramatically hindered the application of deep learning methods, especially for 3D modeling tasks, which require heterogeneous samples. To alleviate the work of data annotation for learned 3D modeling of fa\c{c}ades, this paper proposed a semi-supervised adversarial recognition strategy embedded in inverse procedural modeling. Beginning with textured LOD-2 (Level-of-Details) models, we use the classical convolutional neural networks to recognize the types and estimate the parameters of windows from image patches. The window types and parameters are then assembled into procedural grammar. A simple procedural engine is built inside an existing 3D modeling software, producing fine-grained window geometries. To obtain a useful model from a few labeled samples, we leverage the generative adversarial network to train the feature extractor in a semi-supervised manner. The adversarial training strategy can also exploit unlabeled data to make the training phase more stable. Experiments using publicly available fa\c{c}ade image datasets reveal that the proposed training strategy can obtain about 10% improvement in classification accuracy and 50% improvement in parameter estimation under the same network structure. In addition, performance gains are more pronounced when testing against unseen data featuring different fa\c{c}ade styles.
Meta-learning an Intermediate Representation for Few-shot Block-wise Prediction of Landslide Susceptibility
Oct 03, 2021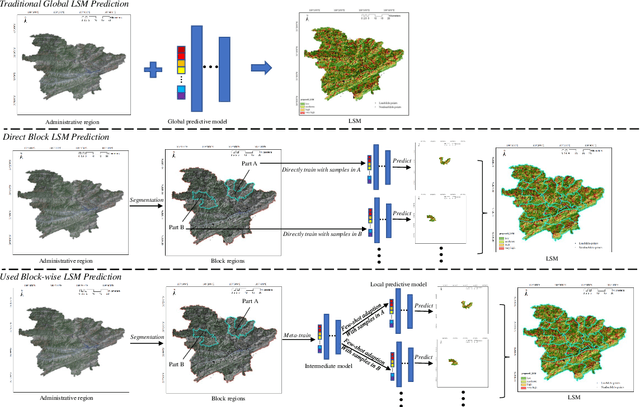
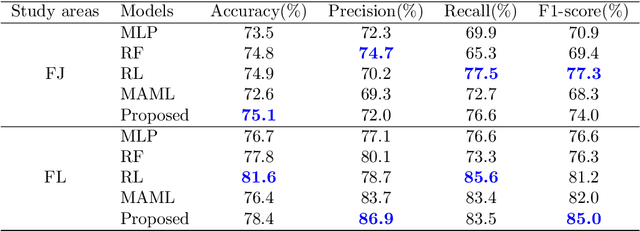
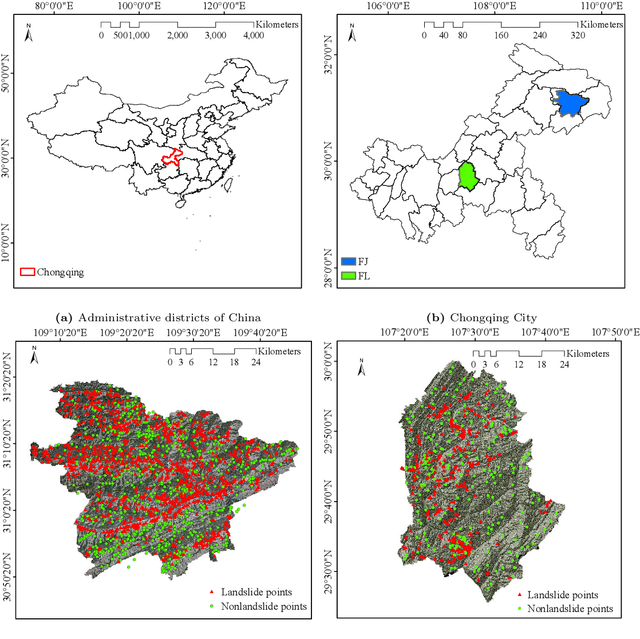
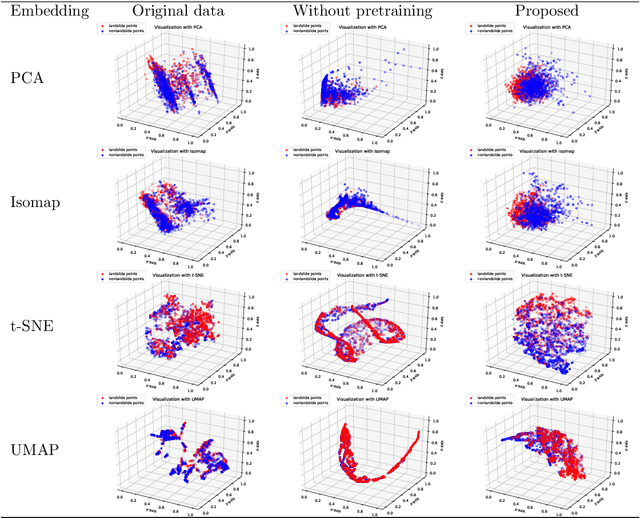
Predicting a landslide susceptibility map (LSM) is essential for risk recognition and disaster prevention. Despite the successful application of data-driven prediction approaches, current data-driven methods generally apply a single global model to predict the LSM for an entire target region. However, we argue that, in complex circumstances, especially in large-scale areas, each part of the region holds different landslide-inducing environments, and therefore, should be predicted individually with respective models. In this study, target scenarios were segmented into blocks for individual analysis using topographical factors. But simply conducting training and testing using limited samples within each block is hardly possible for a satisfactory LSM prediction, due to the adverse effect of \textit{overfitting}. To solve the problems, we train an intermediate representation by the meta-learning paradigm, which is superior for capturing information from LSM tasks in order to generalize proficiently. We chose this based on the hypothesis that there are more general concepts among LSM tasks that are sensitive to variations in input features. Thus, using the intermediate representation, we can easily adapt the model for different blocks or even unseen tasks using few exemplar samples. Experimental results on two study areas demonstrated the validity of our block-wise analysis in large scenarios and revealed the top few-shot adaption performances of the proposed methods.
Fast and Regularized Reconstruction of Building Façades from Street-View Images using Binary Integer Programming
Feb 20, 2020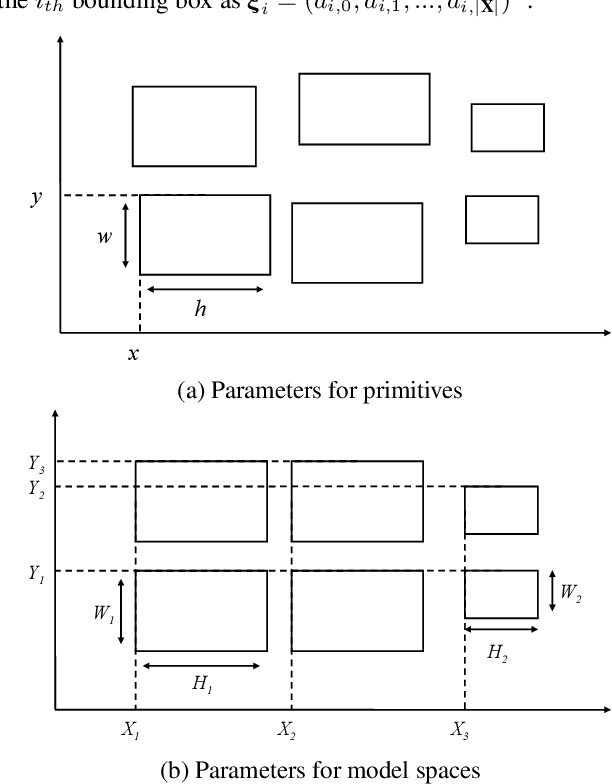
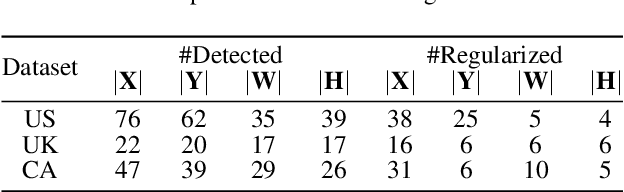
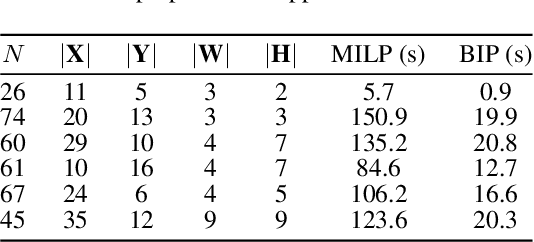

Regularized arrangement of primitives on building fa\c{c}ades to aligned locations and consistent sizes is important towards structured reconstruction of urban environment. Mixed integer linear programing was used to solve the problem, however, it is extreamly time consuming even for state-of-the-art commercial solvers. Aiming to alleviate this issue, we cast the problem into binary integer programming, which omits the requirements for real value parameters and is more efficient to be solved . Firstly, the bounding boxes of the primitives are detected using the YOLOv3 architecture in real-time. Secondly, the coordinates of the upper left corners and the sizes of the bounding boxes are automatically clustered in a binary integer programming optimization, which jointly considers the geometric fitness, regularity and additional constraints; this step does not require \emph{a priori} knowledge, such as the number of clusters or pre-defined grammars. Finally, the regularized bounding boxes can be directly used to guide the fa\c{c}ade reconstruction in an interactive envinronment. Experimental evaluations have revealed that the accuracies for the extraction of primitives are above 0.85, which is sufficient for the following 3D reconstruction. The proposed approach only takes about $ 10\% $ to $ 20\% $ of the runtime than previous approach and reduces the diversity of the bounding boxes to about $20\%$ to $50\%$
CTL Model Update for System Modifications
Oct 31, 2011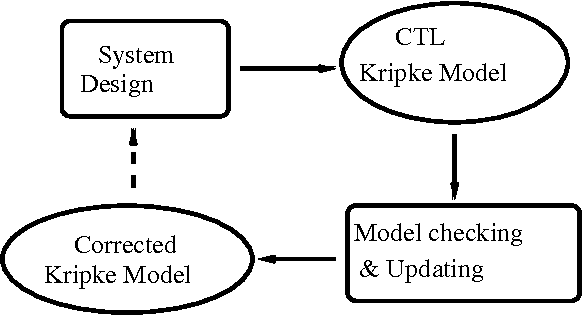
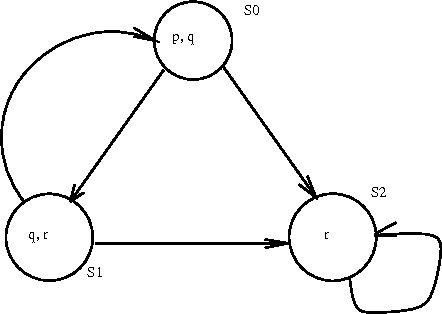
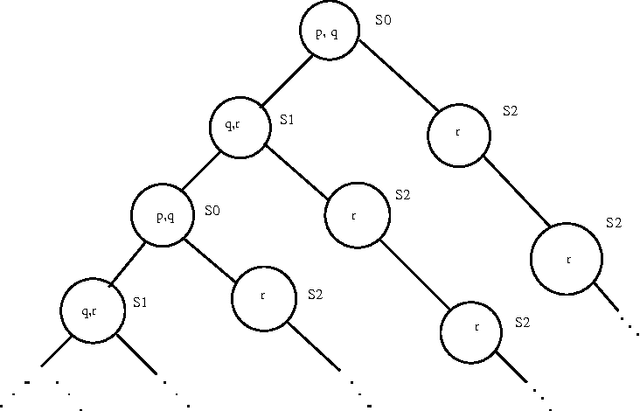
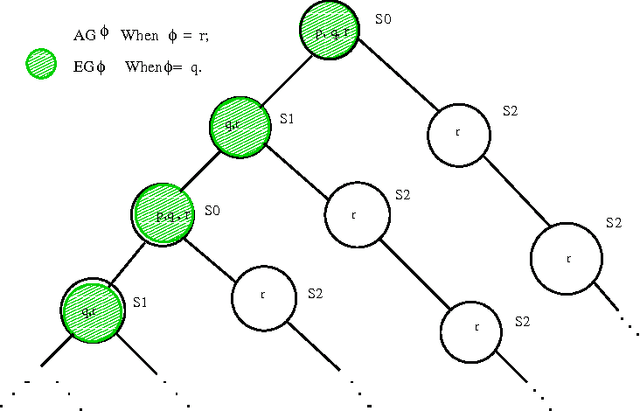
Model checking is a promising technology, which has been applied for verification of many hardware and software systems. In this paper, we introduce the concept of model update towards the development of an automatic system modification tool that extends model checking functions. We define primitive update operations on the models of Computation Tree Logic (CTL) and formalize the principle of minimal change for CTL model update. These primitive update operations, together with the underlying minimal change principle, serve as the foundation for CTL model update. Essential semantic and computational characterizations are provided for our CTL model update approach. We then describe a formal algorithm that implements this approach. We also illustrate two case studies of CTL model updates for the well-known microwave oven example and the Andrew File System 1, from which we further propose a method to optimize the update results in complex system modifications.