 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Adversarial Recognition of Refined Window Structures for Inverse Procedural Façade Modeling
Jan 22, 2022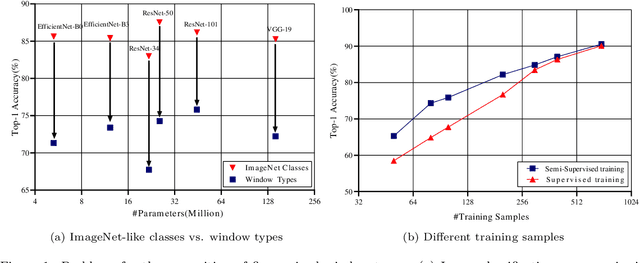

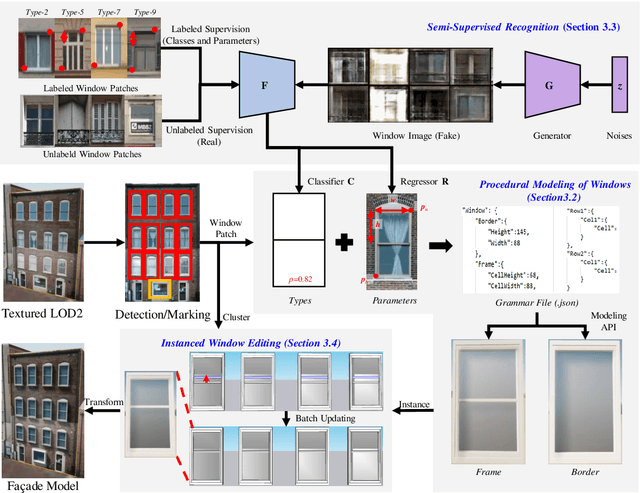
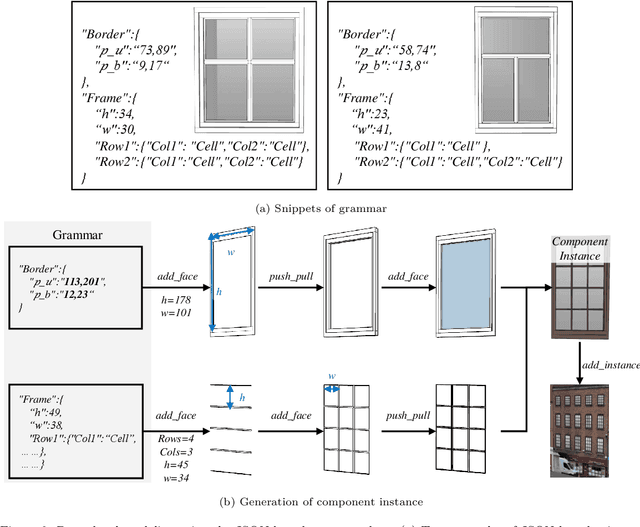
Deep learning methods are notoriously data-hungry, which requires a large number of labeled samples. Unfortunately, the large amount of interactive sample labeling efforts has dramatically hindered the application of deep learning methods, especially for 3D modeling tasks, which require heterogeneous samples. To alleviate the work of data annotation for learned 3D modeling of fa\c{c}ades, this paper proposed a semi-supervised adversarial recognition strategy embedded in inverse procedural modeling. Beginning with textured LOD-2 (Level-of-Details) models, we use the classical convolutional neural networks to recognize the types and estimate the parameters of windows from image patches. The window types and parameters are then assembled into procedural grammar. A simple procedural engine is built inside an existing 3D modeling software, producing fine-grained window geometries. To obtain a useful model from a few labeled samples, we leverage the generative adversarial network to train the feature extractor in a semi-supervised manner. The adversarial training strategy can also exploit unlabeled data to make the training phase more stable. Experiments using publicly available fa\c{c}ade image datasets reveal that the proposed training strategy can obtain about 10% improvement in classification accuracy and 50% improvement in parameter estimation under the same network structure. In addition, performance gains are more pronounced when testing against unseen data featuring different fa\c{c}ade styles.
Depth-Enhanced Feature Pyramid Network for Occlusion-Aware Verification of Buildings from Oblique Images
Nov 26, 2020


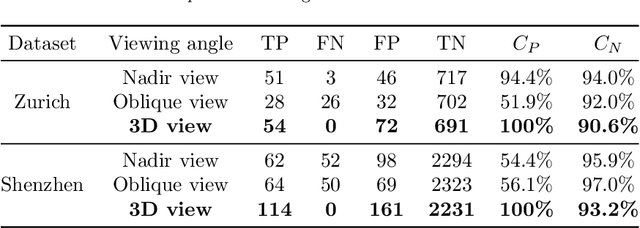
Detecting the changes of buildings in urban environments is essential. Existing methods that use only nadir images suffer from severe problems of ambiguous features and occlusions between buildings and other regions. Furthermore, buildings in urban environments vary significantly in scale, which leads to performance issues when using single-scale features. To solve these issues, this paper proposes a fused feature pyramid network, which utilizes both color and depth data for the 3D verification of existing buildings 2D footprints from oblique images. First, the color data of oblique images are enriched with the depth information rendered from 3D mesh models. Second, multiscale features are fused in the feature pyramid network to convolve both the color and depth data. Finally, multi-view information from both the nadir and oblique images is used in a robust voting procedure to label changes in existing buildings. Experimental evaluations using both the ISPRS benchmark datasets and Shenzhen datasets reveal that the proposed method outperforms the ResNet and EfficientNet networks by 5\% and 2\%, respectively, in terms of recall rate and precision. We demonstrate that the proposed method can successfully detect all changed buildings; therefore, only those marked as changed need to be manually checked during the pipeline updating procedure; this significantly reduces the manual quality control requirements. Moreover, ablation studies indicate that using depth data, feature pyramid modules, and multi-view voting strategies can lead to clear and progressive improvements.
Structure-Aware Completion of Photogrammetric Meshes in Urban Road Environment
Nov 24, 2020

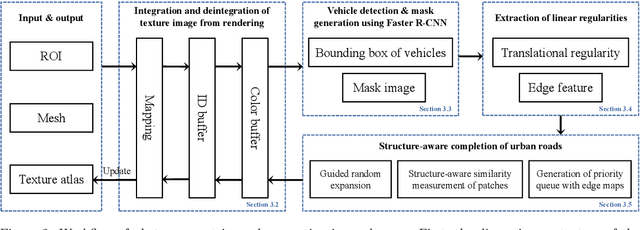

Photogrammetric mesh models obtained from aerial oblique images have been widely used for urban reconstruction. However, the photogrammetric meshes also suffer from severe texture problems, especially on the road areas due to occlusion. This paper proposes a structure-aware completion approach to improve the quality of meshes by removing undesired vehicles on the road seamlessly. Specifically, the discontinuous texture atlas is first integrated to a continuous screen space through rendering by the graphics pipeline; the rendering also records necessary mapping for deintegration to the original texture atlas after editing. Vehicle regions are masked by a standard object detection approach, e.g. Faster RCNN. Then, the masked regions are completed guided by the linear structures and regularities in the road region, which is implemented based on Patch Match. Finally, the completed rendered image is deintegrated to the original texture atlas and the triangles for the vehicles are also flattened for improved meshes. Experimental evaluations and analyses are conducted against three datasets, which are captured with different sensors and ground sample distances. The results reveal that the proposed method can quite realistic meshes after removing the vehicles. The structure-aware completion approach for road regions outperforms popular image completion methods and ablation study further confirms the effectiveness of the linear guidance. It should be noted that the proposed method is also capable to handle tiled mesh models for large-scale scenes. Dataset and code are available at vrlab.org.cn/~hanhu/projects/mesh.