 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Adversarial Recognition of Refined Window Structures for Inverse Procedural Façade Modeling
Jan 22, 2022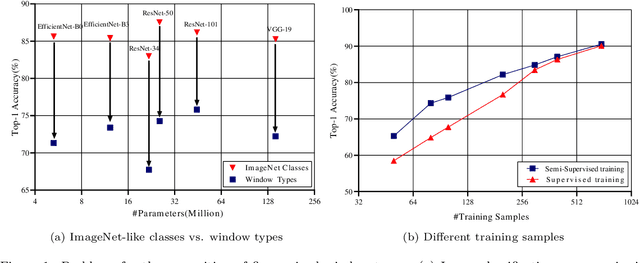

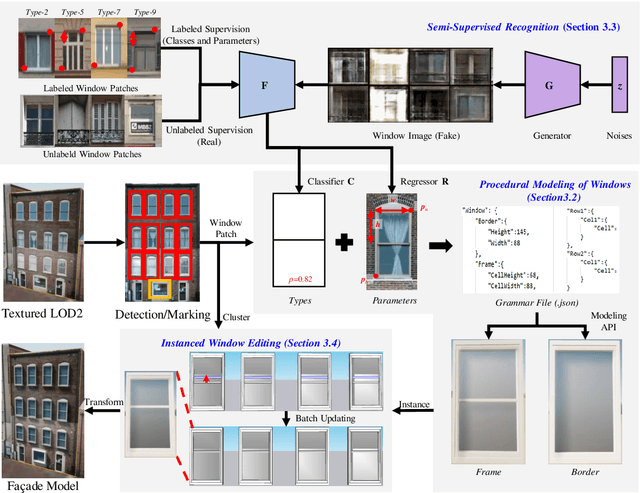
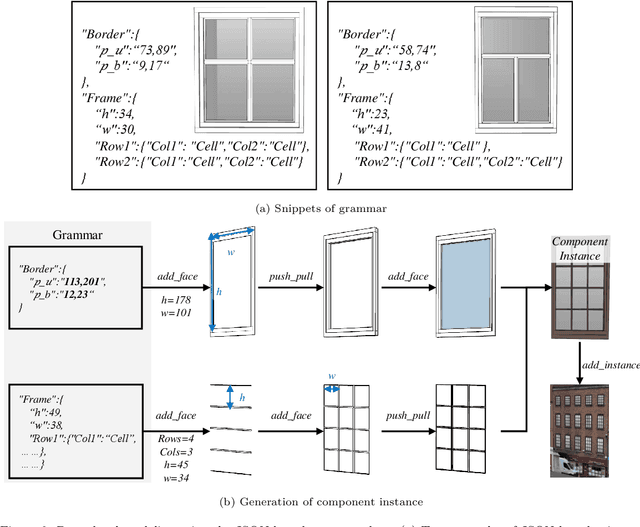
Deep learning methods are notoriously data-hungry, which requires a large number of labeled samples. Unfortunately, the large amount of interactive sample labeling efforts has dramatically hindered the application of deep learning methods, especially for 3D modeling tasks, which require heterogeneous samples. To alleviate the work of data annotation for learned 3D modeling of fa\c{c}ades, this paper proposed a semi-supervised adversarial recognition strategy embedded in inverse procedural modeling. Beginning with textured LOD-2 (Level-of-Details) models, we use the classical convolutional neural networks to recognize the types and estimate the parameters of windows from image patches. The window types and parameters are then assembled into procedural grammar. A simple procedural engine is built inside an existing 3D modeling software, producing fine-grained window geometries. To obtain a useful model from a few labeled samples, we leverage the generative adversarial network to train the feature extractor in a semi-supervised manner. The adversarial training strategy can also exploit unlabeled data to make the training phase more stable. Experiments using publicly available fa\c{c}ade image datasets reveal that the proposed training strategy can obtain about 10% improvement in classification accuracy and 50% improvement in parameter estimation under the same network structure. In addition, performance gains are more pronounced when testing against unseen data featuring different fa\c{c}ade styles.
Leveraging Photogrammetric Mesh Models for Aerial-Ground Feature Point Matching Toward Integrated 3D Reconstruction
Feb 21, 2020


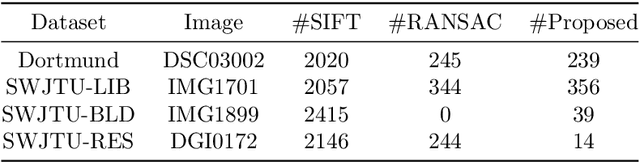
Integration of aerial and ground images has been proved as an efficient approach to enhance the surface reconstruction in urban environments. However, as the first step, the feature point matching between aerial and ground images is remarkably difficult, due to the large differences in viewpoint and illumination conditions. Previous studies based on geometry-aware image rectification have alleviated this problem, but the performance and convenience of this strategy is limited by several flaws, e.g. quadratic image pairs, segregated extraction of descriptors and occlusions. To address these problems, we propose a novel approach: leveraging photogrammetric mesh models for aerial-ground image matching. The methods of this proposed approach have linear time complexity with regard to the number of images, can explicitly handle low overlap using multi-view images and can be directly injected into off-the-shelf structure-from-motion (SfM) and multi-view stereo (MVS) solutions. First, aerial and ground images are reconstructed separately and initially co-registered through weak georeferencing data. Second, aerial models are rendered to the initial ground views, in which the color, depth and normal images are obtained. Then, the synthesized color images and the corresponding ground images are matched by comparing the descriptors, filtered by local geometrical information, and then propagated to the aerial views using depth images and patch-based matching. Experimental evaluations using various datasets confirm the superior performance of the proposed methods in aerial-ground image matching. In addition, incorporation of the existing SfM and MVS solutions into these methods enables more complete and accurate models to be directly obtained.