 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuredMesh: 3D Structured Optimization of Façade Components on Photogrammetric Mesh Models using Binary Integer Programming
Jun 07, 2023



The lack of fa\c{c}ade structures in photogrammetric mesh models renders them inadequate for meeting the demands of intricate applications. Moreover, these mesh models exhibit irregular surfaces with considerable geometric noise and texture quality imperfections, making the restoration of structures challenging. To address these shortcomings, we present StructuredMesh, a novel approach for reconstructing fa\c{c}ade structures conforming to the regularity of buildings within photogrammetric mesh models. Our method involves capturing multi-view color and depth images of the building model using a virtual camera and employing a deep learning object detection pipeline to semi-automatically extract the bounding boxes of fa\c{c}ade components such as windows, doors, and balconies from the color image. We then utilize the depth image to remap these boxes into 3D space, generating an initial fa\c{c}ade layout. Leveraging architectural knowledge, we apply binary integer programming (BIP) to optimize the 3D layout's structure, encompassing the positions, orientations, and sizes of all components. The refined layout subsequently informs fa\c{c}ade modeling through instance replacement. We conducted experiments utilizing building mesh models from three distinct datasets, demonstrating the adaptability, robustness, and noise resistance of our proposed methodology. Furthermore, our 3D layout evaluation metrics reveal that the optimized layout enhances precision, recall, and F-score by 6.5%, 4.5%, and 5.5%, respectively, in comparison to the initial layout.
SuperpixelGraph: Semi-automatic generation of building footprint through semantic-sensitive superpixel and neural graph networks
Apr 12, 2023



Most urban applications necessitate building footprints in the form of concise vector graphics with sharp boundaries rather than pixel-wise raster images. This need contrasts with the majority of existing methods, which typically generate over-smoothed footprint polygons. Editing these automatically produced polygons can be inefficient, if not more time-consuming than manual digitization. This paper introduces a semi-automatic approach for building footprint extraction through semantically-sensitive superpixels and neural graph networks. Drawing inspiration from object-based classification techniques, we first learn to generate superpixels that are not only boundary-preserving but also semantically-sensitive. The superpixels respond exclusively to building boundaries rather than other natural objects, while simultaneously producing semantic segmentation of the buildings. These intermediate superpixel representations can be naturally considered as nodes within a graph. Consequently, graph neural networks are employed to model the global interactions among all superpixels and enhance the representativeness of node features for building segmentation. Classical approaches are utilized to extract and regularize boundaries for the vectorized building footprints. Utilizing minimal clicks and straightforward strokes, we efficiently accomplish accurate segmentation outcomes, eliminating the necessity for editing polygon vertices. Our proposed approach demonstrates superior precision and efficacy, as validated by experimental assessments on various public benchmark datasets. We observe a 10\% enhancement in the metric for superpixel clustering and an 8\% increment in vector graphics evaluation, when compared with established techniques. Additionally, we have devised an optimized and sophisticated pipeline for interactive editing, poised to further augment the overall quality of the results.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Apr 01, 2023The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Semi-Supervised Adversarial Recognition of Refined Window Structures for Inverse Procedural Façade Modeling
Jan 22, 2022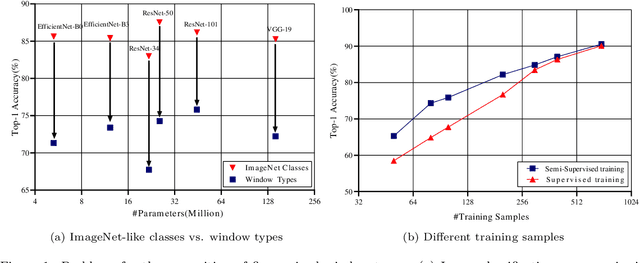

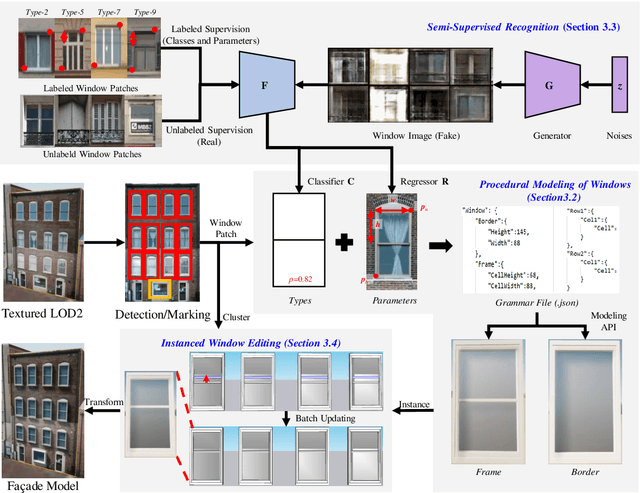
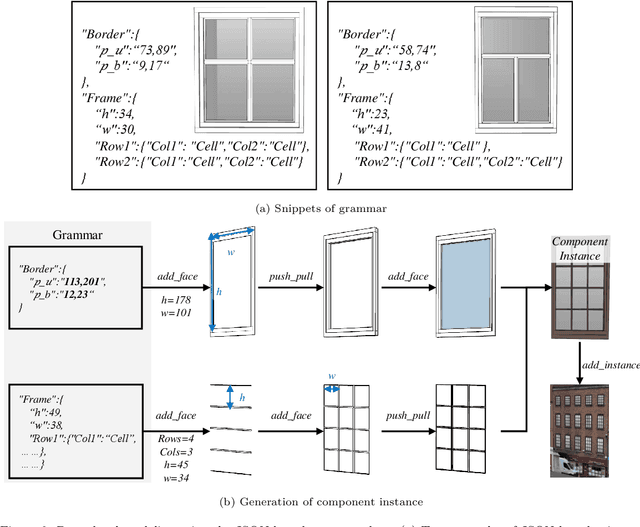
Deep learning methods are notoriously data-hungry, which requires a large number of labeled samples. Unfortunately, the large amount of interactive sample labeling efforts has dramatically hindered the application of deep learning methods, especially for 3D modeling tasks, which require heterogeneous samples. To alleviate the work of data annotation for learned 3D modeling of fa\c{c}ades, this paper proposed a semi-supervised adversarial recognition strategy embedded in inverse procedural modeling. Beginning with textured LOD-2 (Level-of-Details) models, we use the classical convolutional neural networks to recognize the types and estimate the parameters of windows from image patches. The window types and parameters are then assembled into procedural grammar. A simple procedural engine is built inside an existing 3D modeling software, producing fine-grained window geometries. To obtain a useful model from a few labeled samples, we leverage the generative adversarial network to train the feature extractor in a semi-supervised manner. The adversarial training strategy can also exploit unlabeled data to make the training phase more stable. Experiments using publicly available fa\c{c}ade image datasets reveal that the proposed training strategy can obtain about 10% improvement in classification accuracy and 50% improvement in parameter estimation under the same network structure. In addition, performance gains are more pronounced when testing against unseen data featuring different fa\c{c}ade styles.
Meta-learning an Intermediate Representation for Few-shot Block-wise Prediction of Landslide Susceptibility
Oct 03, 2021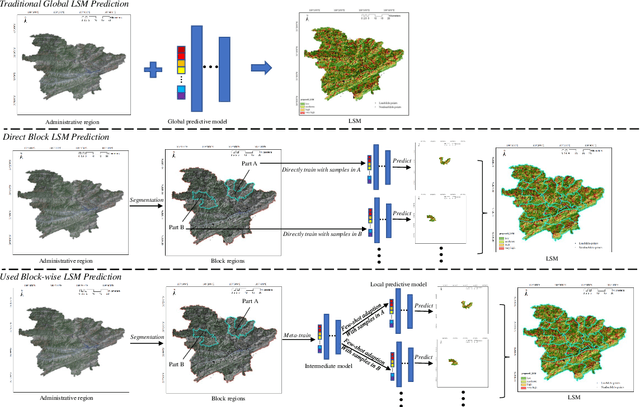
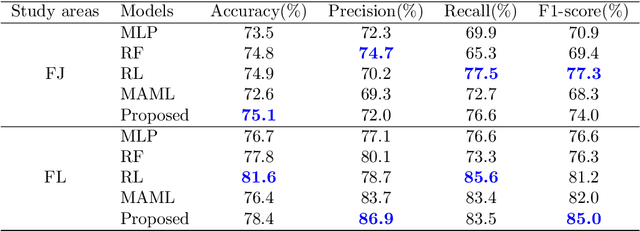
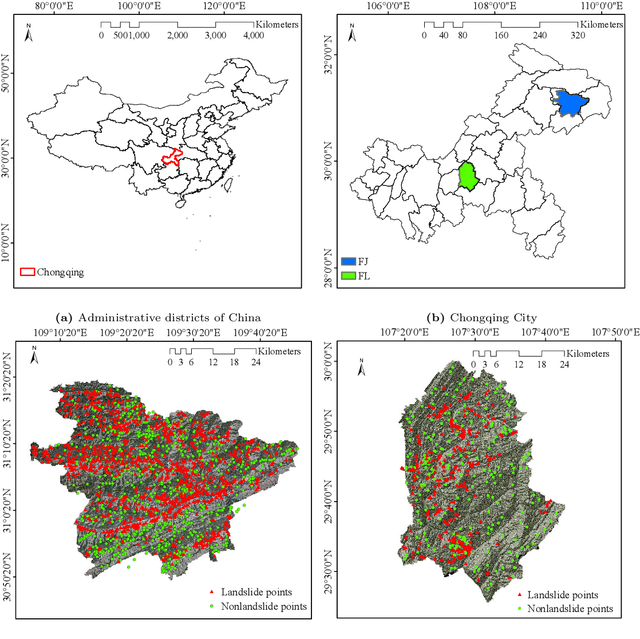
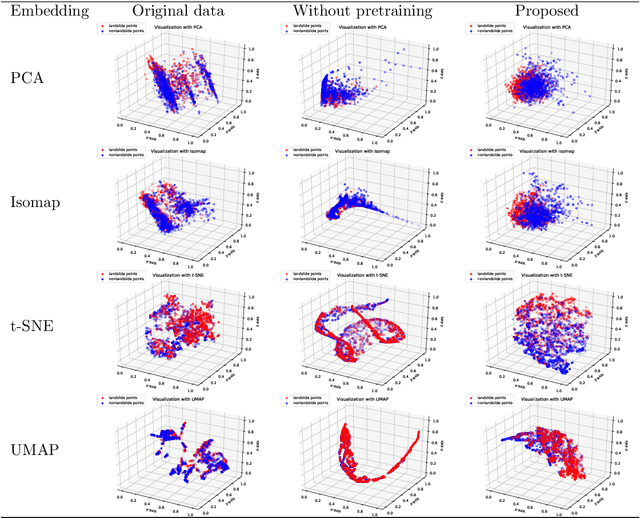
Predicting a landslide susceptibility map (LSM) is essential for risk recognition and disaster prevention. Despite the successful application of data-driven prediction approaches, current data-driven methods generally apply a single global model to predict the LSM for an entire target region. However, we argue that, in complex circumstances, especially in large-scale areas, each part of the region holds different landslide-inducing environments, and therefore, should be predicted individually with respective models. In this study, target scenarios were segmented into blocks for individual analysis using topographical factors. But simply conducting training and testing using limited samples within each block is hardly possible for a satisfactory LSM prediction, due to the adverse effect of \textit{overfitting}. To solve the problems, we train an intermediate representation by the meta-learning paradigm, which is superior for capturing information from LSM tasks in order to generalize proficiently. We chose this based on the hypothesis that there are more general concepts among LSM tasks that are sensitive to variations in input features. Thus, using the intermediate representation, we can easily adapt the model for different blocks or even unseen tasks using few exemplar samples. Experimental results on two study areas demonstrated the validity of our block-wise analysis in large scenarios and revealed the top few-shot adaption performances of the proposed methods.