 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning an Intermediate Representation for Few-shot Block-wise Prediction of Landslide Susceptibility
Paper and Code
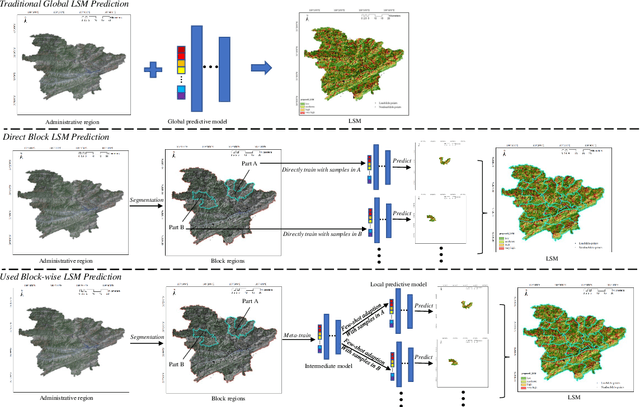
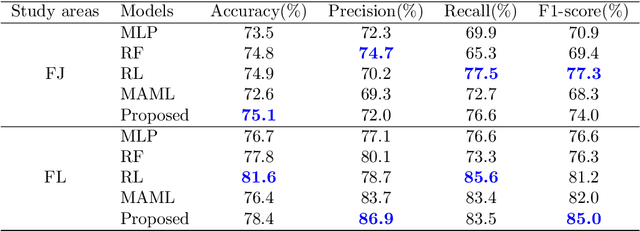
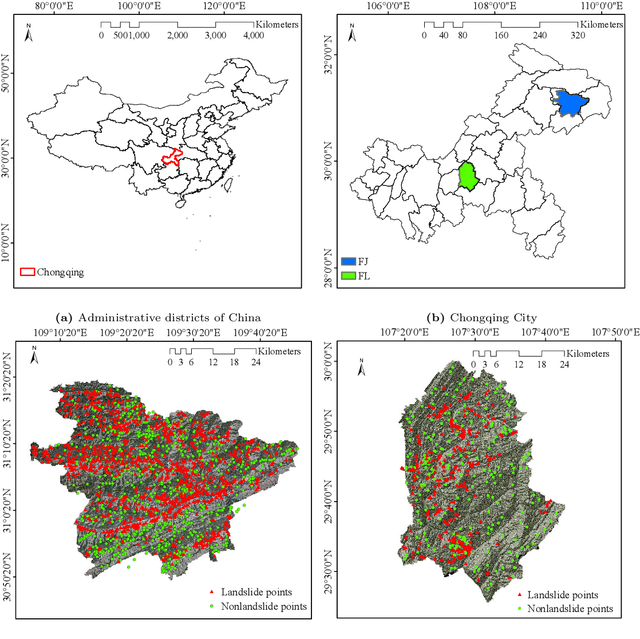
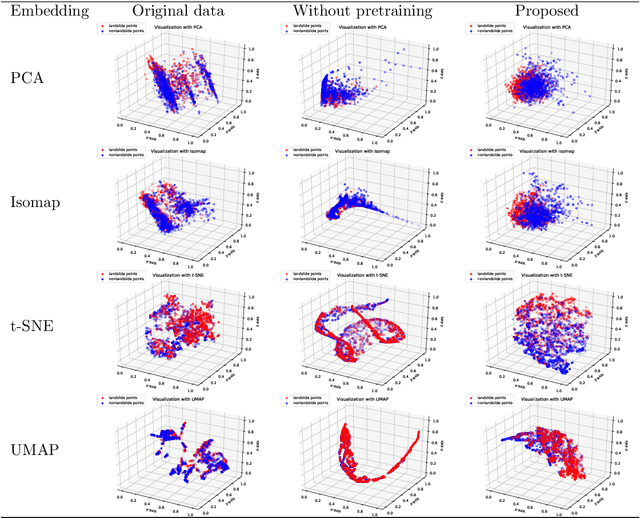
Predicting a landslide susceptibility map (LSM) is essential for risk recognition and disaster prevention. Despite the successful application of data-driven prediction approaches, current data-driven methods generally apply a single global model to predict the LSM for an entire target region. However, we argue that, in complex circumstances, especially in large-scale areas, each part of the region holds different landslide-inducing environments, and therefore, should be predicted individually with respective models. In this study, target scenarios were segmented into blocks for individual analysis using topographical factors. But simply conducting training and testing using limited samples within each block is hardly possible for a satisfactory LSM prediction, due to the adverse effect of \textit{overfitting}. To solve the problems, we train an intermediate representation by the meta-learning paradigm, which is superior for capturing information from LSM tasks in order to generalize proficiently. We chose this based on the hypothesis that there are more general concepts among LSM tasks that are sensitive to variations in input features. Thus, using the intermediate representation, we can easily adapt the model for different blocks or even unseen tasks using few exemplar samples. Experimental results on two study areas demonstrated the validity of our block-wise analysis in large scenarios and revealed the top few-shot adaption performances of the proposed methods.