 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Photogrammetric Mesh Models for Aerial-Ground Feature Point Matching Toward Integrated 3D Reconstruction
Feb 21, 2020


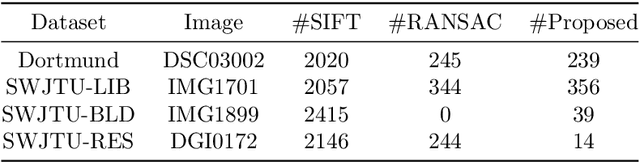
Integration of aerial and ground images has been proved as an efficient approach to enhance the surface reconstruction in urban environments. However, as the first step, the feature point matching between aerial and ground images is remarkably difficult, due to the large differences in viewpoint and illumination conditions. Previous studies based on geometry-aware image rectification have alleviated this problem, but the performance and convenience of this strategy is limited by several flaws, e.g. quadratic image pairs, segregated extraction of descriptors and occlusions. To address these problems, we propose a novel approach: leveraging photogrammetric mesh models for aerial-ground image matching. The methods of this proposed approach have linear time complexity with regard to the number of images, can explicitly handle low overlap using multi-view images and can be directly injected into off-the-shelf structure-from-motion (SfM) and multi-view stereo (MVS) solutions. First, aerial and ground images are reconstructed separately and initially co-registered through weak georeferencing data. Second, aerial models are rendered to the initial ground views, in which the color, depth and normal images are obtained. Then, the synthesized color images and the corresponding ground images are matched by comparing the descriptors, filtered by local geometrical information, and then propagated to the aerial views using depth images and patch-based matching. Experimental evaluations using various datasets confirm the superior performance of the proposed methods in aerial-ground image matching. In addition, incorporation of the existing SfM and MVS solutions into these methods enables more complete and accurate models to be directly obtained.
Deep Fusion of Local and Non-Local Features for Precision Landslide Recognition
Feb 20, 2020



Precision mapping of landslide inventory is crucial for hazard mitigation. Most landslides generally co-exist with other confusing geological features, and the presence of such areas can only be inferred unambiguously at a large scale. In addition, local information is also important for the preservation of object boundaries. Aiming to solve this problem, this paper proposes an effective approach to fuse both local and non-local features to surmount the contextual problem. Built upon the U-Net architecture that is widely adopted in the remote sensing community, we utilize two additional modules. The first one uses dilated convolution and the corresponding atrous spatial pyramid pooling, which enlarged the receptive field without sacrificing spatial resolution or increasing memory usage. The second uses a scale attention mechanism to guide the up-sampling of features from the coarse level by a learned weight map. In implementation, the computational overhead against the original U-Net was only a few convolutional layers. Experimental evaluations revealed that the proposed method outperformed state-of-the-art general-purpose semantic segmentation approaches. Furthermore, ablation studies have shown that the two models afforded extensive enhancements in landslide-recognition performance.