 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
Mar 16, 2026We present MiroThinker-1.7, a new research agent designed for complex long-horizon reasoning tasks. Building on this foundation, we further introduce MiroThinker-H1, which extends the agent with heavy-duty reasoning capabilities for more reliable multi-step problem solving. In particular, MiroThinker-1.7 improves the reliability of each interaction step through an agentic mid-training stage that emphasizes structured planning, contextual reasoning, and tool interaction. This enables more effective multi-step interaction and sustained reasoning across complex tasks. MiroThinker-H1 further incorporates verification directly into the reasoning process at both local and global levels. Intermediate reasoning decisions can be evaluated and refined during inference, while the overall reasoning trajectory is audited to ensure that final answers are supported by coherent chains of evidence. Across benchmarks covering open-web research, scientific reasoning, and financial analysis, MiroThinker-H1 achieves state-of-the-art performance on deep research tasks while maintaining strong results on specialized domains. We also release MiroThinker-1.7 and MiroThinker-1.7-mini as open-source models, providing competitive research-agent capabilities with significantly improved efficiency.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Dark Energy Survey Year 3 results: Simulation-based $w$CDM inference from weak lensing and galaxy clustering maps with deep learning. I. Analysis design
Nov 06, 2025Data-driven approaches using deep learning are emerging as powerful techniques to extract non-Gaussian information from cosmological large-scale structure. This work presents the first simulation-based inference (SBI) pipeline that combines weak lensing and galaxy clustering maps in a realistic Dark Energy Survey Year 3 (DES Y3) configuration and serves as preparation for a forthcoming analysis of the survey data. We develop a scalable forward model based on the CosmoGridV1 suite of N-body simulations to generate over one million self-consistent mock realizations of DES Y3 at the map level. Leveraging this large dataset, we train deep graph convolutional neural networks on the full survey footprint in spherical geometry to learn low-dimensional features that approximately maximize mutual information with target parameters. These learned compressions enable neural density estimation of the implicit likelihood via normalizing flows in a ten-dimensional parameter space spanning cosmological $w$CDM, intrinsic alignment, and linear galaxy bias parameters, while marginalizing over baryonic, photometric redshift, and shear bias nuisances. To ensure robustness, we extensively validate our inference pipeline using synthetic observations derived from both systematic contaminations in our forward model and independent Buzzard galaxy catalogs. Our forecasts yield significant improvements in cosmological parameter constraints, achieving $2-3\times$ higher figures of merit in the $\Omega_m - S_8$ plane relative to our implementation of baseline two-point statistics and effectively breaking parameter degeneracies through probe combination. These results demonstrate the potential of SBI analyses powered by deep learning for upcoming Stage-IV wide-field imaging surveys.
Highly Efficient and Unsupervised Framework for Moving Object Detection in Satellite Videos
Nov 24, 2024Moving object detection in satellite videos (SVMOD) is a challenging task due to the extremely dim and small target characteristics. Current learning-based methods extract spatio-temporal information from multi-frame dense representation with labor-intensive manual labels to tackle SVMOD, which needs high annotation costs and contains tremendous computational redundancy due to the severe imbalance between foreground and background regions. In this paper, we propose a highly efficient unsupervised framework for SVMOD. Specifically, we propose a generic unsupervised framework for SVMOD, in which pseudo labels generated by a traditional method can evolve with the training process to promote detection performance. Furthermore, we propose a highly efficient and effective sparse convolutional anchor-free detection network by sampling the dense multi-frame image form into a sparse spatio-temporal point cloud representation and skipping the redundant computation on background regions. Coping these two designs, we can achieve both high efficiency (label and computation efficiency) and effectiveness. Extensive experiments demonstrate that our method can not only process 98.8 frames per second on 1024x1024 images but also achieve state-of-the-art performance. The relabeled dataset and code are available at https://github.com/ChaoXiao12/Moving-object-detection-in-satellite-videos-HiEUM.
* 8 pages, 8 figures
On Propagation Characteristics of Reconfigurable Surface-Wave Platform: Simulation and Experimental Verification
Apr 27, 2023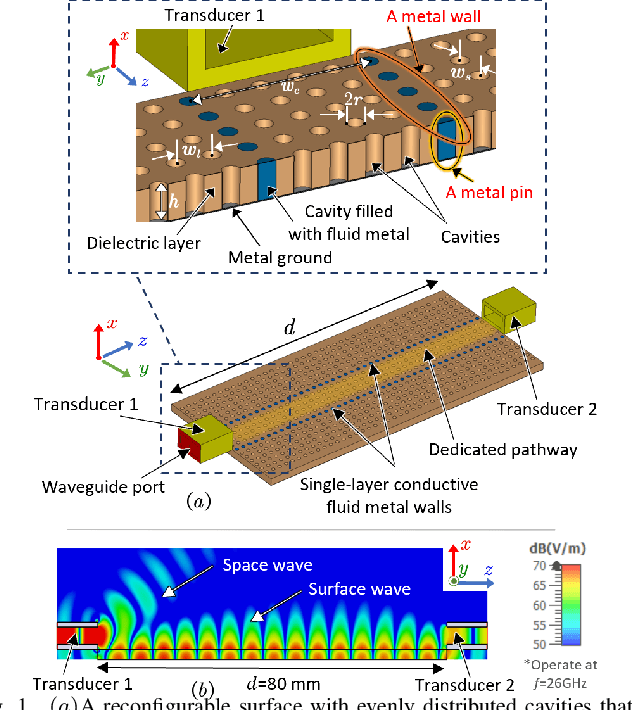
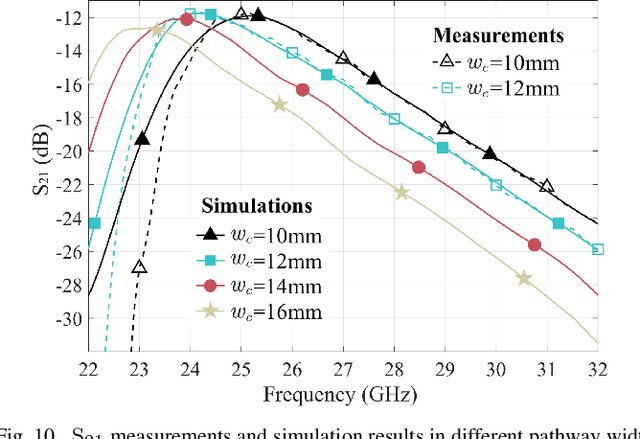
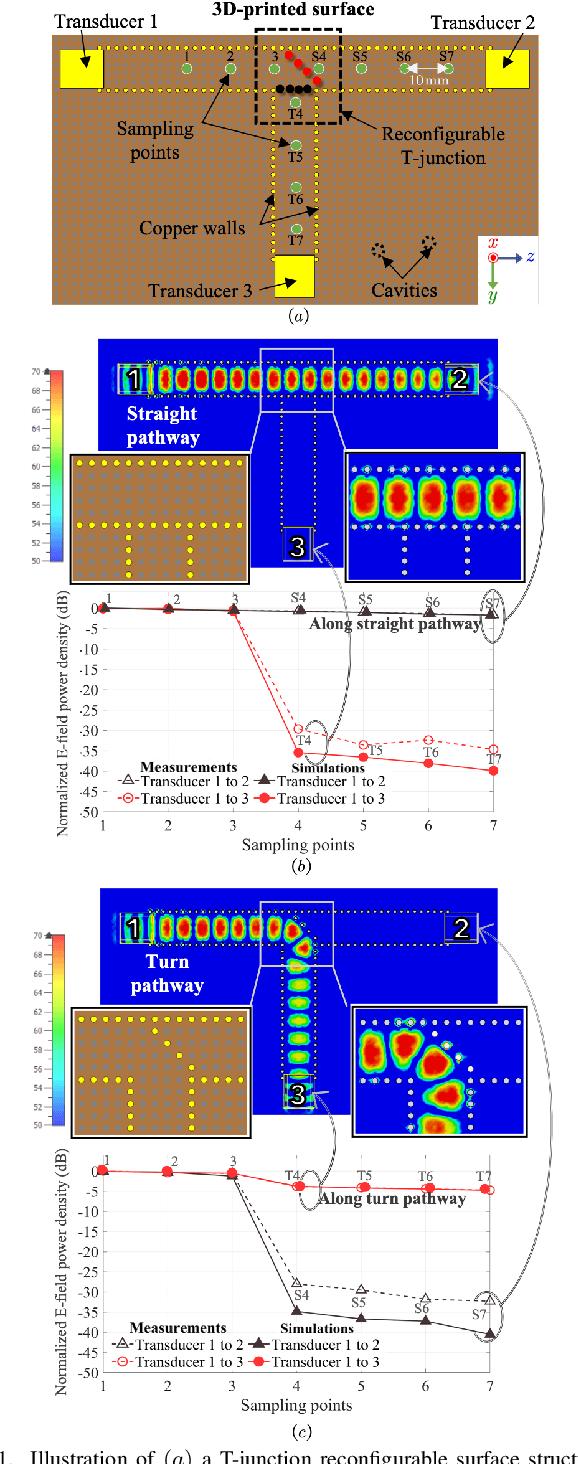

Reconfigurable intelligent surface (RIS) as a smart reflector is revolutionizing research for next-generation wireless communications. Complementing this is a concept of using RIS as an efficient propagation medium for potentially superior path loss characteristics. Motivated by a recent porous surface architecture that facilitates reconfigurable pathways with cavities filled with fluid metal, this paper studies the propagation characteristics of different pathway configurations and evaluates the reconfigurable surface-wave platform by using a commercial full electromagnetic simulation software and experiments. This paper also looks into the best scheme to switch between a straight pathway and a $90^\circ$-turned pathway and attempts to quantify the additional path loss when making a turned pathway. Our experimental results verify the simulation results, showing the effectiveness of the proposed reconfigurable surface-wave platform for a wide-band, low path loss and highly controllable communication.
Tac2Structure: Object Surface Reconstruction Only through Multi Times Touch
Sep 14, 2022


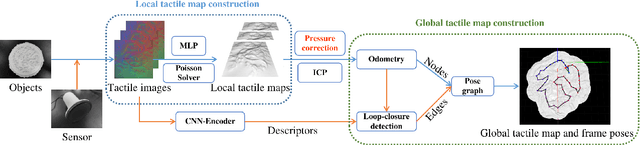
Inspired by the ability of humans to perceive the surface texture of unfamiliar objects without relying on vision, the sense of tactile can play a crucial role in the process of robots exploring the environment, especially in some scenes where vision is difficult to apply or occlusion is inevitable to exist. Existing tactile surface reconstruction methods rely on external sensors or have strong prior assumptions, which will limit their application scenarios and make the operation more complex. This paper presents a surface reconstruction algorithm that uses only a new vision-based tactile sensor where the surface structure of an unfamiliar object is reconstructed by multiple tactile measurements. Compared with existing algorithms, the proposed algorithm doesn't rely on external devices and focuses on improving the reconstruction accuracy of the large-scale object surface. Aiming at the difficulty that the reconstruction accuracy is easily affected by the pressure of sampling, we propose a correction algorithm to adapt it. Multi-frame tactile imprints generated from many times contact can accurately reconstruct global object surface by jointly using the point cloud registration algorithm, loop-closure detection algorithm based on deep learning, and pose graph optimization algorithm. Experiments verify the proposed algorithm can achieve millimeter-level accuracy in reconstructing the surface of interactive objects and provide accurate tactile information for the robot to perceive the surrounding environment.
AI-assisted Optimization of the ECCE Tracking System at the Electron Ion Collider
May 20, 2022The Electron-Ion Collider (EIC) is a cutting-edge accelerator facility that will study the nature of the "glue" that binds the building blocks of the visible matter in the universe. The proposed experiment will be realized at Brookhaven National Laboratory in approximately 10 years from now, with detector design and R&D currently ongoing. Notably, EIC is one of the first large-scale facilities to leverage Artificial Intelligence (AI) already starting from the design and R&D phases. The EIC Comprehensive Chromodynamics Experiment (ECCE) is a consortium that proposed a detector design based on a 1.5T solenoid. The EIC detector proposal review concluded that the ECCE design will serve as the reference design for an EIC detector. Herein we describe a comprehensive optimization of the ECCE tracker using AI. The work required a complex parametrization of the simulated detector system. Our approach dealt with an optimization problem in a multidimensional design space driven by multiple objectives that encode the detector performance, while satisfying several mechanical constraints. We describe our strategy and show results obtained for the ECCE tracking system. The AI-assisted design is agnostic to the simulation framework and can be extended to other sub-detectors or to a system of sub-detectors to further optimize the performance of the EIC detector.
Joint User Scheduling and Beamforming Design for Multiuser MISO Downlink Systems
Dec 03, 2021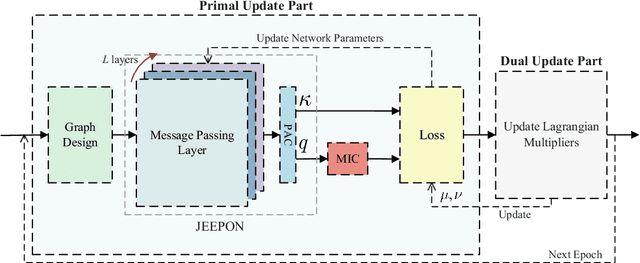
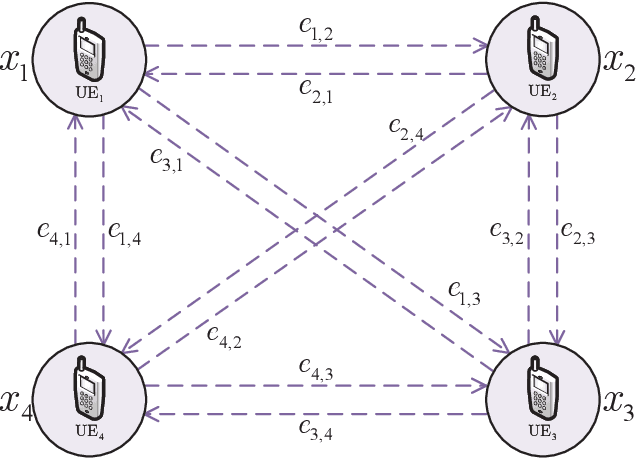
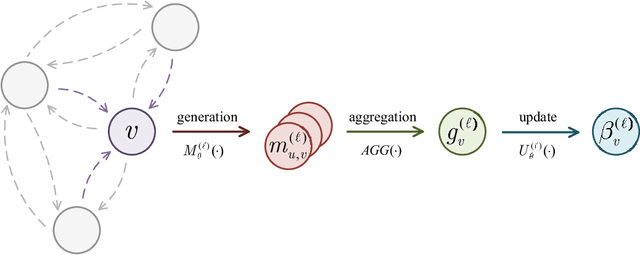
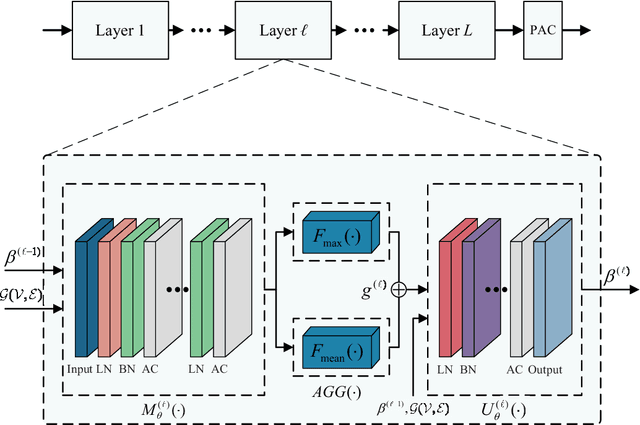
In multiuser communication systems, user scheduling and beamforming design are two fundamental problems, which are usually investigated separately in the existing literature. In this work, we focus on the joint optimization of user scheduling and beamforming design with the goal of maximizing the set cardinality of scheduled users. Observing that this problem is computationally challenging due to the non-convex objective function and coupled constraints in continuous and binary variables. To tackle these difficulties, we first propose an iterative optimization algorithm (IOA) relying on the successive convex approximation and uplink-downlink duality theory. Then, motivated by IOA and graph neural networks, a joint user scheduling and power allocation network (JEEPON) is developed to address the investigated problem in an unsupervised manner. The effectiveness of IOA and JEEPON is verified by various numerical results, and the latter achieves a close performance but lower complexity compared with IOA and the greedy-based algorithm. Remarkably, the proposed JEEPON is also competitive in terms of the generalization ability in dynamic wireless network scenarios.
Detecting intracranial aneurysm rupture from 3D surfaces using a novel GraphNet approach
Oct 17, 2019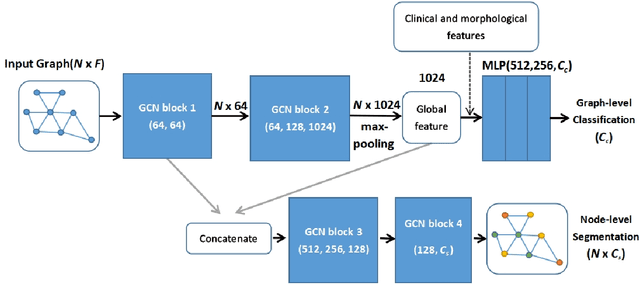
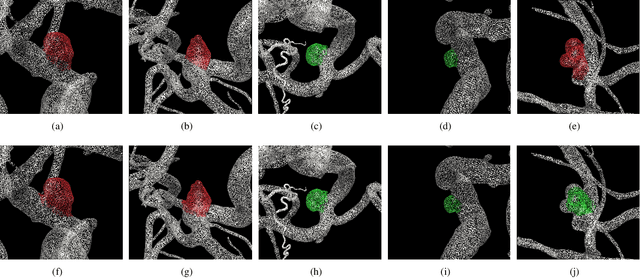
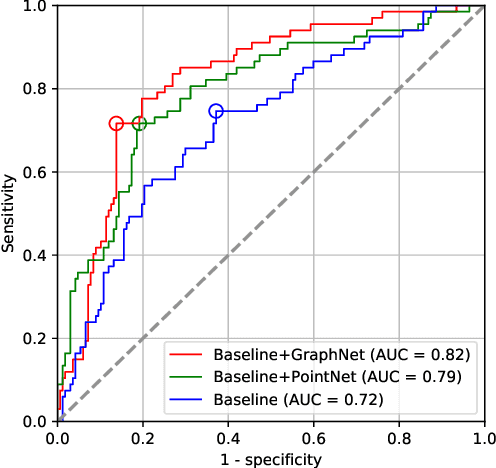
Intracranial aneurysm (IA) is a life-threatening blood spot in human's brain if it ruptures and causes cerebral hemorrhage. It is challenging to detect whether an IA has ruptured from medical images. In this paper, we propose a novel graph based neural network named GraphNet to detect IA rupture from 3D surface data. GraphNet is based on graph convolution network (GCN) and is designed for graph-level classification and node-level segmentation. The network uses GCN blocks to extract surface local features and pools to global features. 1250 patient data including 385 ruptured and 865 unruptured IAs were collected from clinic for experiments. The performance on randomly selected 234 test patient data was reported. The experiment with the proposed GraphNet achieved accuracy of 0.82, area-under-curve (AUC) of receiver operating characteristic (ROC) curve 0.82 in the classification task, significantly outperforming the baseline approach without using graph based networks. The segmentation output of the model achieved mean graph-node-based dice coefficient (DSC) score 0.88.