 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Delay QKV Compression for Mitigating KV Cache and Network Bottlenecks in LLM Inference
Paper and Code
Aug 07, 2024
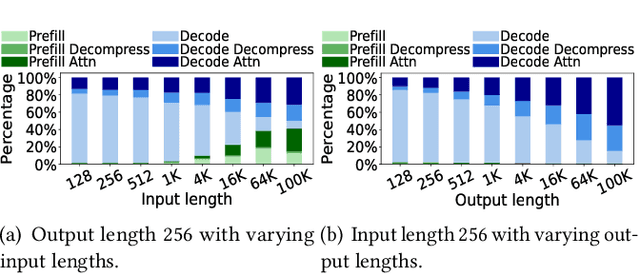
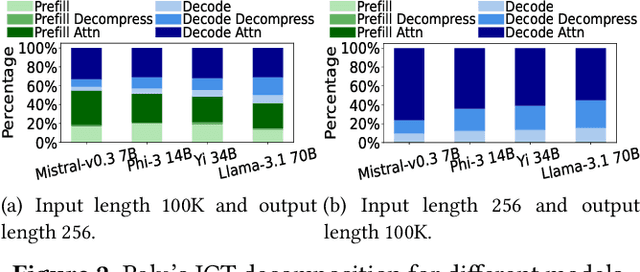
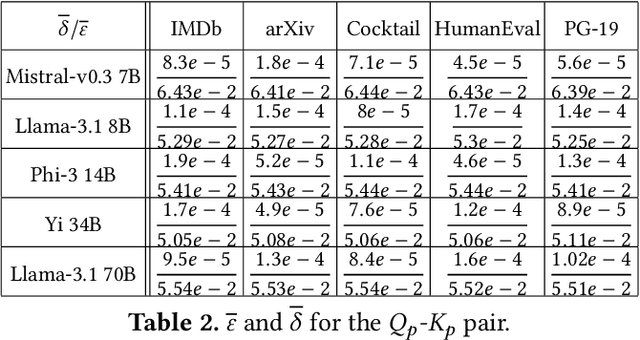
In large-language models, memory constraints in the key-value cache (KVC) pose a challenge during inference, especially with long prompts. In this work, we observed that compressing KV values is more effective than compressing the model regarding accuracy and job completion time (JCT). However, quantizing KV values and dropping less-important tokens incur significant runtime computational time overhead, delaying JCT. These methods also cannot reduce computation time or high network communication time overhead in sequence-parallelism (SP) frameworks for long prompts. To tackle these issues, based on our insightful observations from experimental analysis, we propose ZeroC, a Zero-delay QKV Compression system that eliminates time overhead and even reduces computation and communication time of the model operations. ZeroC innovatively embeds compression and decompression operations within model operations and adaptively determines compression ratios at a hybrid layer-token level. Further, it enables a communication-efficient SP inference framework. Trace-driven experiments demonstrate that ZeroC achieves up to 80% lower average JCT, 35% lower average perplexity, and 2.8x higher throughput with the same latency compared to state-of-the-art compression methods. ZeroC also reduces the average JCT of current LLM serving systems by up to 91% with the constraint of 0.1 perplexity increase. We open-sourced the code.