 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrofit: Continual Learning with Bounded Forgetting for Security Applications
Nov 14, 2025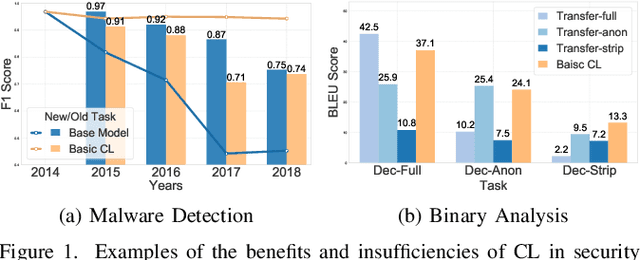
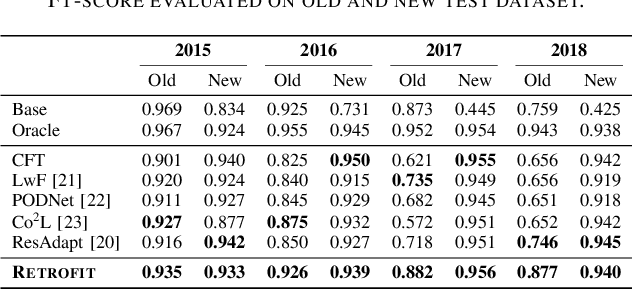

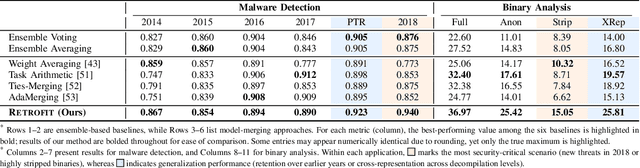
Modern security analytics are increasingly powered by deep learning models, but their performance often degrades as threat landscapes evolve and data representations shift. While continual learning (CL) offers a promising paradigm to maintain model effectiveness, many approaches rely on full retraining or data replay, which are infeasible in data-sensitive environments. Moreover, existing methods remain inadequate for security-critical scenarios, facing two coupled challenges in knowledge transfer: preserving prior knowledge without old data and integrating new knowledge with minimal interference. We propose RETROFIT, a data retrospective-free continual learning method that achieves bounded forgetting for effective knowledge transfer. Our key idea is to consolidate previously trained and newly fine-tuned models, serving as teachers of old and new knowledge, through parameter-level merging that eliminates the need for historical data. To mitigate interference, we apply low-rank and sparse updates that confine parameter changes to independent subspaces, while a knowledge arbitration dynamically balances the teacher contributions guided by model confidence. Our evaluation on two representative applications demonstrates that RETROFIT consistently mitigates forgetting while maintaining adaptability. In malware detection under temporal drift, it substantially improves the retention score, from 20.2% to 38.6% over CL baselines, and exceeds the oracle upper bound on new data. In binary summarization across decompilation levels, where analyzing stripped binaries is especially challenging, RETROFIT achieves around twice the BLEU score of transfer learning used in prior work and surpasses all baselines in cross-representation generalization.
Beyond Classification: Evaluating LLMs for Fine-Grained Automatic Malware Behavior Auditing
Sep 17, 2025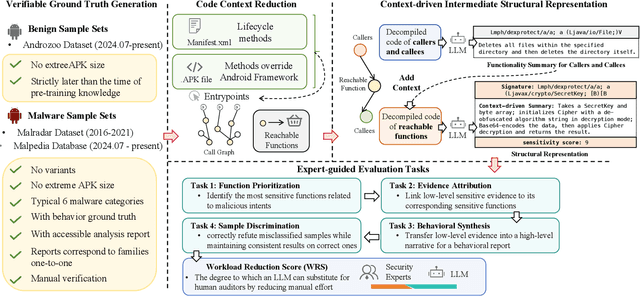
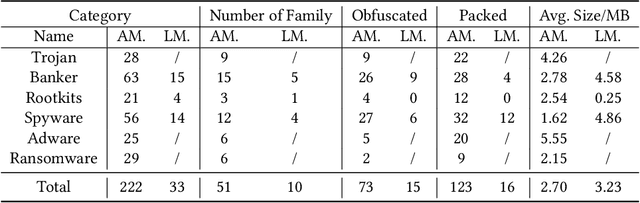
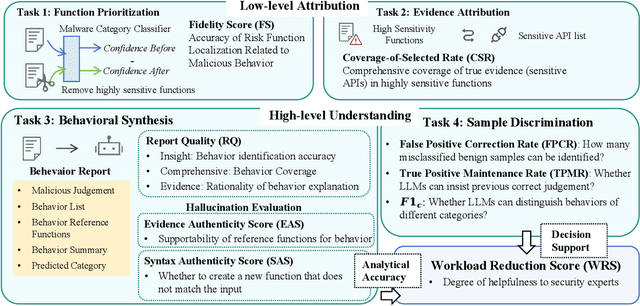
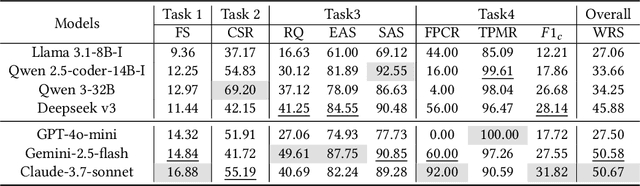
Automated malware classification has achieved strong detection performance. Yet, malware behavior auditing seeks causal and verifiable explanations of malicious activities -- essential not only to reveal what malware does but also to substantiate such claims with evidence. This task is challenging, as adversarial intent is often hidden within complex, framework-heavy applications, making manual auditing slow and costly. Large Language Models (LLMs) could help address this gap, but their auditing potential remains largely unexplored due to three limitations: (1) scarce fine-grained annotations for fair assessment; (2) abundant benign code obscuring malicious signals; and (3) unverifiable, hallucination-prone outputs undermining attribution credibility. To close this gap, we introduce MalEval, a comprehensive framework for fine-grained Android malware auditing, designed to evaluate how effectively LLMs support auditing under real-world constraints. MalEval provides expert-verified reports and an updated sensitive API list to mitigate ground truth scarcity and reduce noise via static reachability analysis. Function-level structural representations serve as intermediate attribution units for verifiable evaluation. Building on this, we define four analyst-aligned tasks -- function prioritization, evidence attribution, behavior synthesis, and sample discrimination -- together with domain-specific metrics and a unified workload-oriented score. We evaluate seven widely used LLMs on a curated dataset of recent malware and misclassified benign apps, offering the first systematic assessment of their auditing capabilities. MalEval reveals both promising potential and critical limitations across audit stages, providing a reproducible benchmark and foundation for future research on LLM-enhanced malware behavior auditing. MalEval is publicly available at https://github.com/ZhengXR930/MalEval.git
RealFactBench: A Benchmark for Evaluating Large Language Models in Real-World Fact-Checking
Jun 14, 2025Large Language Models (LLMs) hold significant potential for advancing fact-checking by leveraging their capabilities in reasoning, evidence retrieval, and explanation generation. However, existing benchmarks fail to comprehensively evaluate LLMs and Multimodal Large Language Models (MLLMs) in realistic misinformation scenarios. To bridge this gap, we introduce RealFactBench, a comprehensive benchmark designed to assess the fact-checking capabilities of LLMs and MLLMs across diverse real-world tasks, including Knowledge Validation, Rumor Detection, and Event Verification. RealFactBench consists of 6K high-quality claims drawn from authoritative sources, encompassing multimodal content and diverse domains. Our evaluation framework further introduces the Unknown Rate (UnR) metric, enabling a more nuanced assessment of models' ability to handle uncertainty and balance between over-conservatism and over-confidence. Extensive experiments on 7 representative LLMs and 4 MLLMs reveal their limitations in real-world fact-checking and offer valuable insights for further research. RealFactBench is publicly available at https://github.com/kalendsyang/RealFactBench.git.
On Benchmarking Code LLMs for Android Malware Analysis
Apr 01, 2025Large Language Models (LLMs) have demonstrated strong capabilities in various code intelligence tasks. However, their effectiveness for Android malware analysis remains underexplored. Decompiled Android code poses unique challenges for analysis, primarily due to its large volume of functions and the frequent absence of meaningful function names. This paper presents Cama, a benchmarking framework designed to systematically evaluate the effectiveness of Code LLMs in Android malware analysis tasks. Cama specifies structured model outputs (comprising function summaries, refined function names, and maliciousness scores) to support key malware analysis tasks, including malicious function identification and malware purpose summarization. Built on these, it integrates three domain-specific evaluation metrics, consistency, fidelity, and semantic relevance, enabling rigorous stability and effectiveness assessment and cross-model comparison. We construct a benchmark dataset consisting of 118 Android malware samples, encompassing over 7.5 million distinct functions, and use Cama to evaluate four popular open-source models. Our experiments provide insights into how Code LLMs interpret decompiled code and quantify the sensitivity to function renaming, highlighting both the potential and current limitations of Code LLMs in malware analysis tasks.
LAMD: Context-driven Android Malware Detection and Classification with LLMs
Feb 18, 2025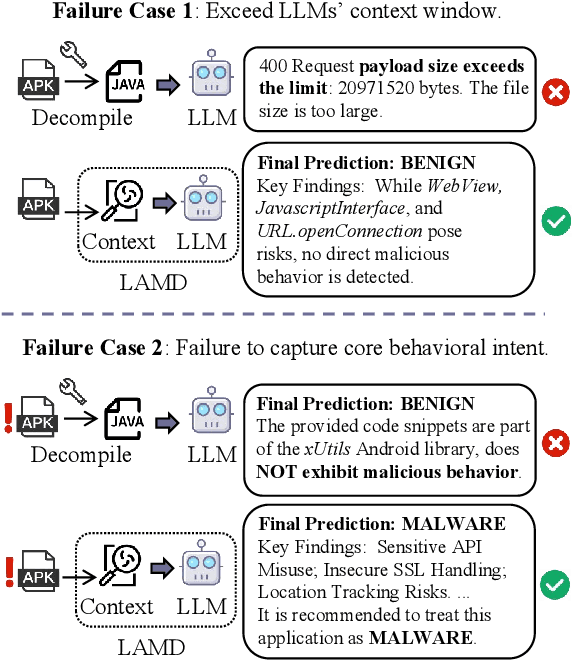
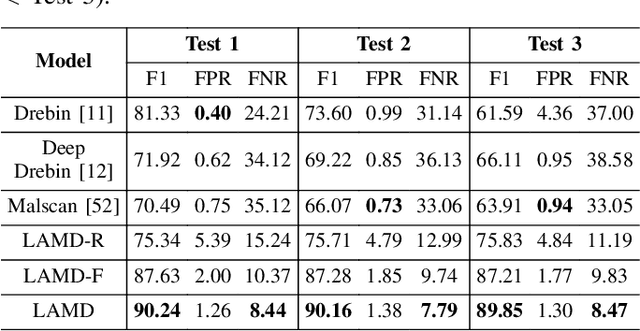
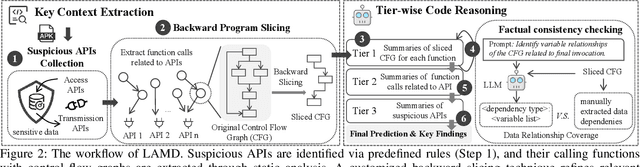
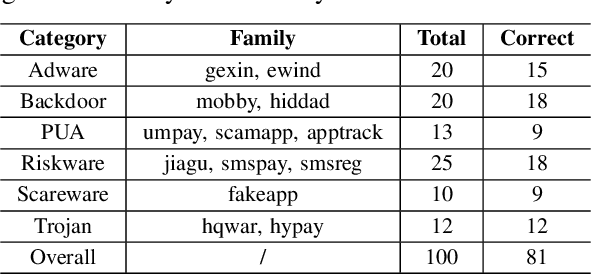
The rapid growth of mobile applications has escalated Android malware threats. Although there are numerous detection methods, they often struggle with evolving attacks, dataset biases, and limited explainability. Large Language Models (LLMs) offer a promising alternative with their zero-shot inference and reasoning capabilities. However, applying LLMs to Android malware detection presents two key challenges: (1)the extensive support code in Android applications, often spanning thousands of classes, exceeds LLMs' context limits and obscures malicious behavior within benign functionality; (2)the structural complexity and interdependencies of Android applications surpass LLMs' sequence-based reasoning, fragmenting code analysis and hindering malicious intent inference. To address these challenges, we propose LAMD, a practical context-driven framework to enable LLM-based Android malware detection. LAMD integrates key context extraction to isolate security-critical code regions and construct program structures, then applies tier-wise code reasoning to analyze application behavior progressively, from low-level instructions to high-level semantics, providing final prediction and explanation. A well-designed factual consistency verification mechanism is equipped to mitigate LLM hallucinations from the first tier. Evaluation in real-world settings demonstrates LAMD's effectiveness over conventional detectors, establishing a feasible basis for LLM-driven malware analysis in dynamic threat landscapes.
Learning Temporal Invariance in Android Malware Detectors
Feb 07, 2025



Learning-based Android malware detectors degrade over time due to natural distribution drift caused by malware variants and new families. This paper systematically investigates the challenges classifiers trained with empirical risk minimization (ERM) face against such distribution shifts and attributes their shortcomings to their inability to learn stable discriminative features. Invariant learning theory offers a promising solution by encouraging models to generate stable representations crossing environments that expose the instability of the training set. However, the lack of prior environment labels, the diversity of drift factors, and low-quality representations caused by diverse families make this task challenging. To address these issues, we propose TIF, the first temporal invariant training framework for malware detection, which aims to enhance the ability of detectors to learn stable representations across time. TIF organizes environments based on application observation dates to reveal temporal drift, integrating specialized multi-proxy contrastive learning and invariant gradient alignment to generate and align environments with high-quality, stable representations. TIF can be seamlessly integrated into any learning-based detector. Experiments on a decade-long dataset show that TIF excels, particularly in early deployment stages, addressing real-world needs and outperforming state-of-the-art methods.
Benchmarking Multimodal Retrieval Augmented Generation with Dynamic VQA Dataset and Self-adaptive Planning Agent
Nov 05, 2024



Multimodal Retrieval Augmented Generation (mRAG) plays an important role in mitigating the "hallucination" issue inherent in multimodal large language models (MLLMs). Although promising, existing heuristic mRAGs typically predefined fixed retrieval processes, which causes two issues: (1) Non-adaptive Retrieval Queries. (2) Overloaded Retrieval Queries. However, these flaws cannot be adequately reflected by current knowledge-seeking visual question answering (VQA) datasets, since the most required knowledge can be readily obtained with a standard two-step retrieval. To bridge the dataset gap, we first construct Dyn-VQA dataset, consisting of three types of "dynamic" questions, which require complex knowledge retrieval strategies variable in query, tool, and time: (1) Questions with rapidly changing answers. (2) Questions requiring multi-modal knowledge. (3) Multi-hop questions. Experiments on Dyn-VQA reveal that existing heuristic mRAGs struggle to provide sufficient and precisely relevant knowledge for dynamic questions due to their rigid retrieval processes. Hence, we further propose the first self-adaptive planning agent for multimodal retrieval, OmniSearch. The underlying idea is to emulate the human behavior in question solution which dynamically decomposes complex multimodal questions into sub-question chains with retrieval action. Extensive experiments prove the effectiveness of our OmniSearch, also provide direction for advancing mRAG. The code and dataset will be open-sourced at https://github.com/Alibaba-NLP/OmniSearch.