 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Evaluating LLMs for Fine-Grained Automatic Malware Behavior Auditing
Sep 17, 2025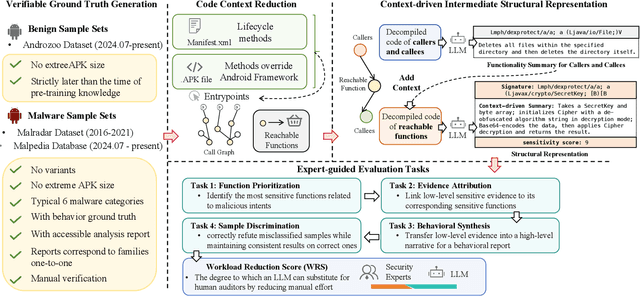
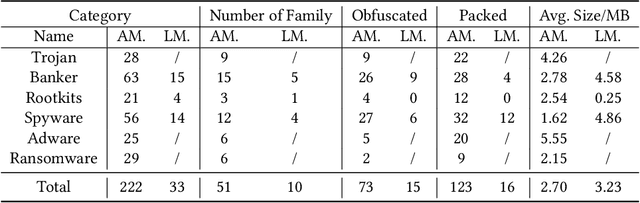
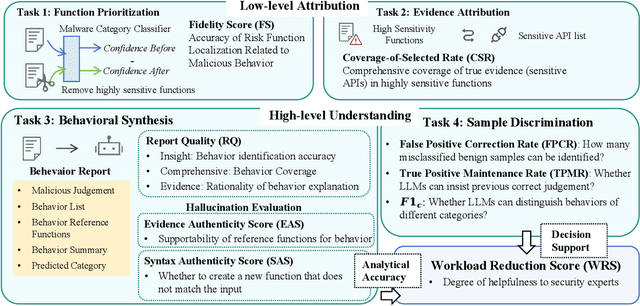
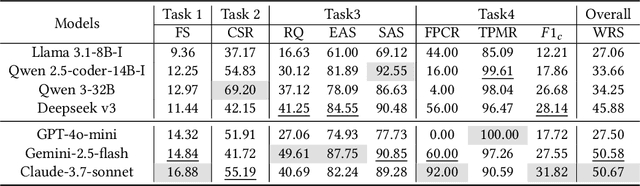
Automated malware classification has achieved strong detection performance. Yet, malware behavior auditing seeks causal and verifiable explanations of malicious activities -- essential not only to reveal what malware does but also to substantiate such claims with evidence. This task is challenging, as adversarial intent is often hidden within complex, framework-heavy applications, making manual auditing slow and costly. Large Language Models (LLMs) could help address this gap, but their auditing potential remains largely unexplored due to three limitations: (1) scarce fine-grained annotations for fair assessment; (2) abundant benign code obscuring malicious signals; and (3) unverifiable, hallucination-prone outputs undermining attribution credibility. To close this gap, we introduce MalEval, a comprehensive framework for fine-grained Android malware auditing, designed to evaluate how effectively LLMs support auditing under real-world constraints. MalEval provides expert-verified reports and an updated sensitive API list to mitigate ground truth scarcity and reduce noise via static reachability analysis. Function-level structural representations serve as intermediate attribution units for verifiable evaluation. Building on this, we define four analyst-aligned tasks -- function prioritization, evidence attribution, behavior synthesis, and sample discrimination -- together with domain-specific metrics and a unified workload-oriented score. We evaluate seven widely used LLMs on a curated dataset of recent malware and misclassified benign apps, offering the first systematic assessment of their auditing capabilities. MalEval reveals both promising potential and critical limitations across audit stages, providing a reproducible benchmark and foundation for future research on LLM-enhanced malware behavior auditing. MalEval is publicly available at https://github.com/ZhengXR930/MalEval.git
On Benchmarking Code LLMs for Android Malware Analysis
Apr 01, 2025Large Language Models (LLMs) have demonstrated strong capabilities in various code intelligence tasks. However, their effectiveness for Android malware analysis remains underexplored. Decompiled Android code poses unique challenges for analysis, primarily due to its large volume of functions and the frequent absence of meaningful function names. This paper presents Cama, a benchmarking framework designed to systematically evaluate the effectiveness of Code LLMs in Android malware analysis tasks. Cama specifies structured model outputs (comprising function summaries, refined function names, and maliciousness scores) to support key malware analysis tasks, including malicious function identification and malware purpose summarization. Built on these, it integrates three domain-specific evaluation metrics, consistency, fidelity, and semantic relevance, enabling rigorous stability and effectiveness assessment and cross-model comparison. We construct a benchmark dataset consisting of 118 Android malware samples, encompassing over 7.5 million distinct functions, and use Cama to evaluate four popular open-source models. Our experiments provide insights into how Code LLMs interpret decompiled code and quantify the sensitivity to function renaming, highlighting both the potential and current limitations of Code LLMs in malware analysis tasks.
LAMD: Context-driven Android Malware Detection and Classification with LLMs
Feb 18, 2025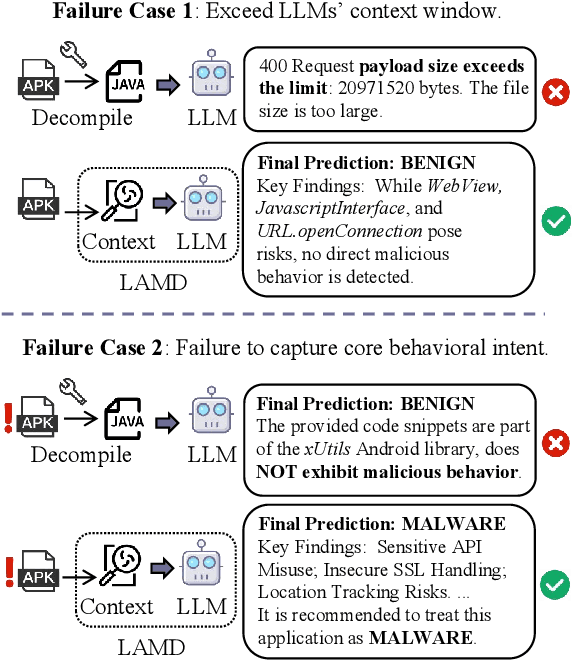
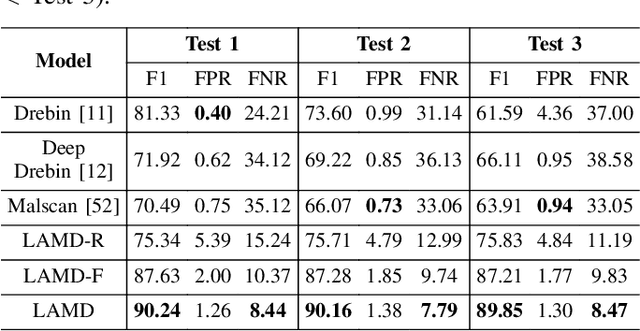
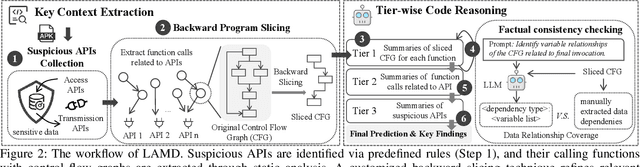
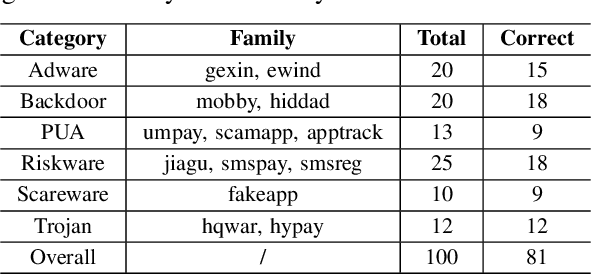
The rapid growth of mobile applications has escalated Android malware threats. Although there are numerous detection methods, they often struggle with evolving attacks, dataset biases, and limited explainability. Large Language Models (LLMs) offer a promising alternative with their zero-shot inference and reasoning capabilities. However, applying LLMs to Android malware detection presents two key challenges: (1)the extensive support code in Android applications, often spanning thousands of classes, exceeds LLMs' context limits and obscures malicious behavior within benign functionality; (2)the structural complexity and interdependencies of Android applications surpass LLMs' sequence-based reasoning, fragmenting code analysis and hindering malicious intent inference. To address these challenges, we propose LAMD, a practical context-driven framework to enable LLM-based Android malware detection. LAMD integrates key context extraction to isolate security-critical code regions and construct program structures, then applies tier-wise code reasoning to analyze application behavior progressively, from low-level instructions to high-level semantics, providing final prediction and explanation. A well-designed factual consistency verification mechanism is equipped to mitigate LLM hallucinations from the first tier. Evaluation in real-world settings demonstrates LAMD's effectiveness over conventional detectors, establishing a feasible basis for LLM-driven malware analysis in dynamic threat landscapes.