 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks with Internal State, Unconstrained Connectivity, and Discrete Activations
Paper and Code
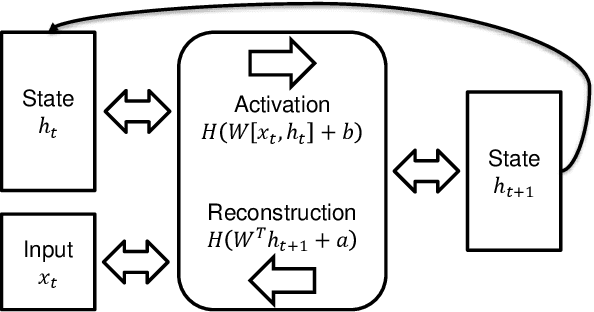
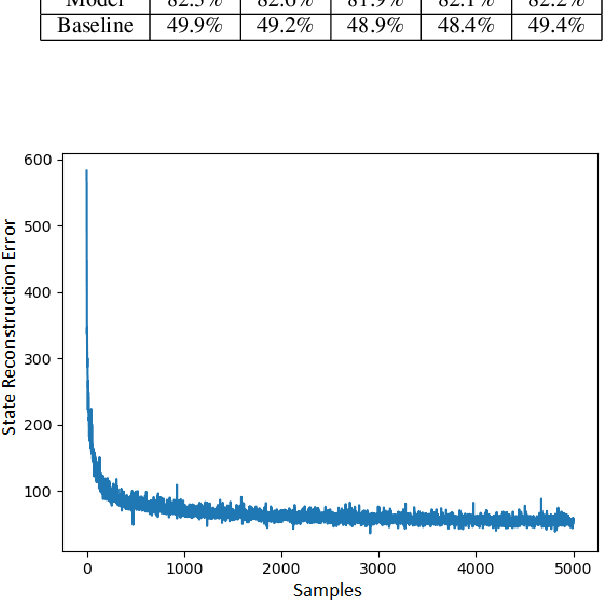
Today's most powerful machine learning approaches are typically designed to train stateless architectures with predefined layers and differentiable activation functions. While these approaches have led to unprecedented successes in areas such as natural language processing and image recognition, the trained models are also susceptible to making mistakes that a human would not. In this paper, we take the view that true intelligence may require the ability of a machine learning model to manage internal state, but that we have not yet discovered the most effective algorithms for training such models. We further postulate that such algorithms might not necessarily be based on gradient descent over a deep architecture, but rather, might work best with an architecture that has discrete activations and few initial topological constraints (such as multiple predefined layers). We present one attempt in our ongoing efforts to design such a training algorithm, applied to an architecture with binary activations and only a single matrix of weights, and show that it is able to form useful representations of natural language text, but is also limited in its ability to leverage large quantities of training data. We then provide ideas for improving the algorithm and for designing other training algorithms for similar architectures. Finally, we discuss potential benefits that could be gained if an effective training algorithm is found, and suggest experiments for evaluating whether these benefits exist in practice.