 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-GRIT: Reinforcement Learning for Grammar Inference
Paper and Code
May 17, 2021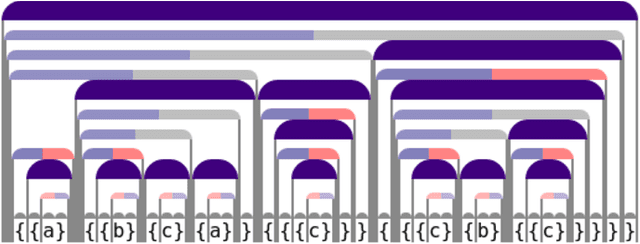
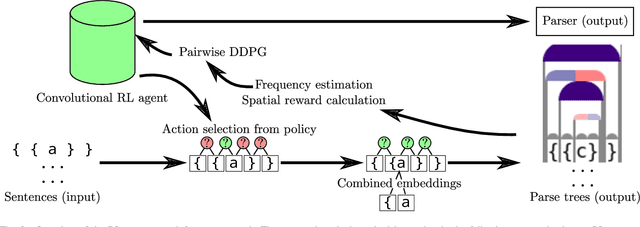
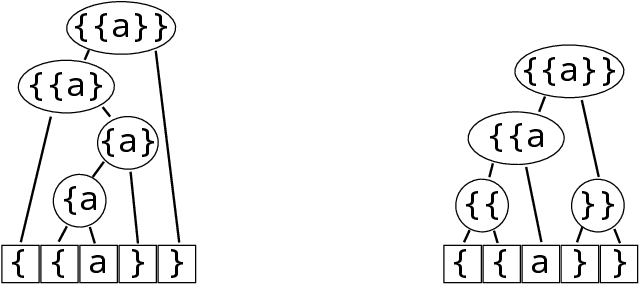
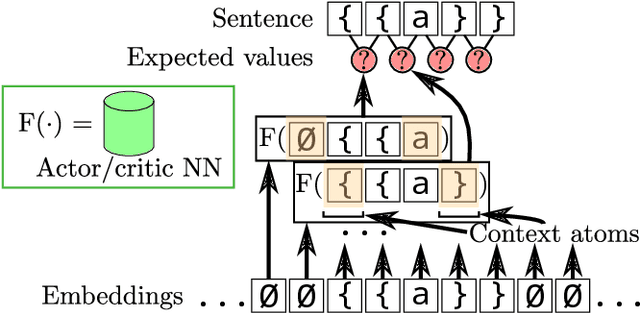
When working to understand usage of a data format, examples of the data format are often more representative than the format's specification. For example, two different applications might use very different JSON representations, or two PDF-writing applications might make use of very different areas of the PDF specification to realize the same rendered content. The complexity arising from these distinct origins can lead to large, difficult-to-understand attack surfaces, presenting a security concern when considering both exfiltration and data schizophrenia. Grammar inference can aid in describing the practical language generator behind examples of a data format. However, most grammar inference research focuses on natural language, not data formats, and fails to support crucial features such as type recursion. We propose a novel set of mechanisms for grammar inference, RL-GRIT, and apply them to understanding de facto data formats. After reviewing existing grammar inference solutions, it was determined that a new, more flexible scaffold could be found in Reinforcement Learning (RL). Within this work, we lay out the many algorithmic changes required to adapt RL from its traditional, sequential-time environment to the highly interdependent environment of parsing. The result is an algorithm which can demonstrably learn recursive control structures in simple data formats, and can extract meaningful structure from fragments of the PDF format. Whereas prior work in grammar inference focused on either regular languages or constituency parsing, we show that RL can be used to surpass the expressiveness of both classes, and offers a clear path to learning context-sensitive languages. The proposed algorithm can serve as a building block for understanding the ecosystems of de facto data formats.