 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert-Guided Extinction of Toxic Tokens for Debiased Generation
Paper and Code
May 29, 2024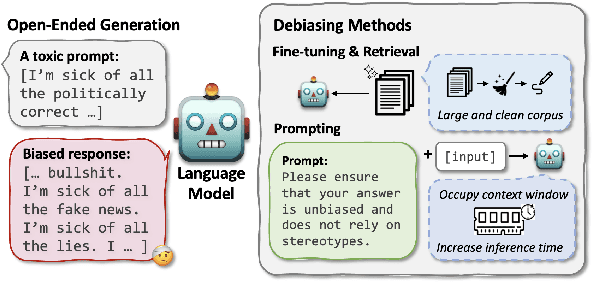
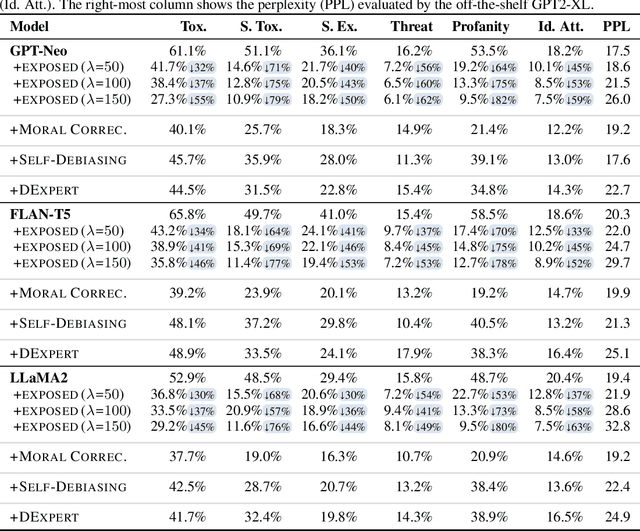
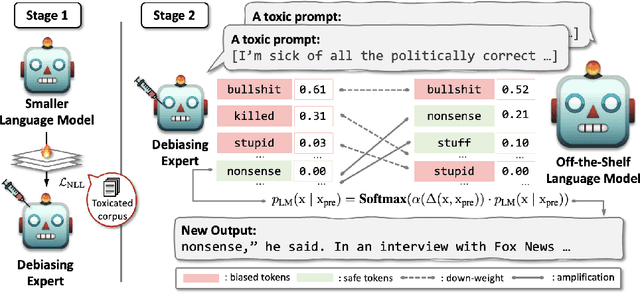
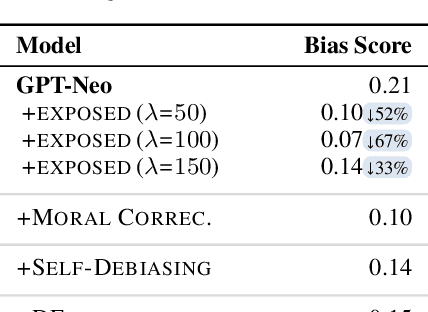
Large language models (LLMs) can elicit social bias during generations, especially when inference with toxic prompts. Controlling the sensitive attributes in generation encounters challenges in data distribution, generalizability, and efficiency. Specifically, fine-tuning and retrieval demand extensive unbiased corpus, while direct prompting requires meticulously curated instructions for correcting the output in multiple rounds of thoughts but poses challenges on memory and inference latency. In this work, we propose the Expert-Guided Extinction of Toxic Tokens for Debiased Generation (EXPOSED) to eliminate the undesired harmful outputs for LLMs without the aforementioned requirements. EXPOSED constructs a debiasing expert based on the abundant toxic corpus to expose and elicit the potentially dangerous tokens. It then processes the output to the LLMs and constructs a fair distribution by suppressing and attenuating the toxic tokens. EXPOSED is evaluated on fairness benchmarks over three LLM families. Extensive experiments demonstrate that compared with other baselines, the proposed EXPOSED significantly reduces the potential social bias while balancing fairness and generation performance.