 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Vector Quantized-Variational Autoencoder
Paper and Code
Feb 04, 2022

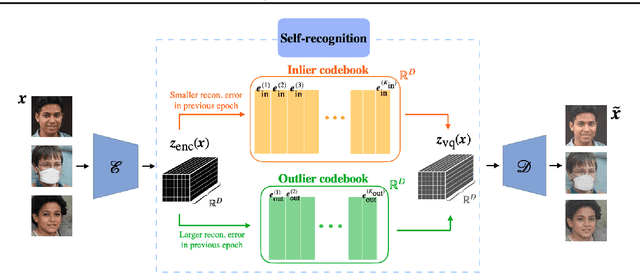

Image generative models can learn the distributions of the training data and consequently generate examples by sampling from these distributions. However, when the training dataset is corrupted with outliers, generative models will likely produce examples that are also similar to the outliers. In fact, a small portion of outliers may induce state-of-the-art generative models, such as Vector Quantized-Variational AutoEncoder (VQ-VAE), to learn a significant mode from the outliers. To mitigate this problem, we propose a robust generative model based on VQ-VAE, which we name Robust VQ-VAE (RVQ-VAE). In order to achieve robustness, RVQ-VAE uses two separate codebooks for the inliers and outliers. To ensure the codebooks embed the correct components, we iteratively update the sets of inliers and outliers during each training epoch. To ensure that the encoded data points are matched to the correct codebooks, we quantize using a weighted Euclidean distance, whose weights are determined by directional variances of the codebooks. Both codebooks, together with the encoder and decoder, are trained jointly according to the reconstruction loss and the quantization loss. We experimentally demonstrate that RVQ-VAE is able to generate examples from inliers even if a large portion of the training data points are corrupted.