 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Evaluation to Design: Using Potential Energy Surface Smoothness Metrics to Guide Machine Learning Interatomic Potential Architectures
Feb 04, 2026Machine Learning Interatomic Potentials (MLIPs) sometimes fail to reproduce the physical smoothness of the quantum potential energy surface (PES), leading to erroneous behavior in downstream simulations that standard energy and force regression evaluations can miss. Existing evaluations, such as microcanonical molecular dynamics (MD), are computationally expensive and primarily probe near-equilibrium states. To improve evaluation metrics for MLIPs, we introduce the Bond Smoothness Characterization Test (BSCT). This efficient benchmark probes the PES via controlled bond deformations and detects non-smoothness, including discontinuities, artificial minima, and spurious forces, both near and far from equilibrium. We show that BSCT correlates strongly with MD stability while requiring a fraction of the cost of MD. To demonstrate how BSCT can guide iterative model design, we utilize an unconstrained Transformer backbone as a testbed, illustrating how refinements such as a new differentiable $k$-nearest neighbors algorithm and temperature-controlled attention reduce artifacts identified by our metric. By optimizing model design systematically based on BSCT, the resulting MLIP simultaneously achieves a low conventional E/F regression error, stable MD simulations, and robust atomistic property predictions. Our results establish BSCT as both a validation metric and as an "in-the-loop" model design proxy that alerts MLIP developers to physical challenges that cannot be efficiently evaluated by current MLIP benchmarks.
Transformers Discover Molecular Structure Without Graph Priors
Oct 02, 2025



Graph Neural Networks (GNNs) are the dominant architecture for molecular machine learning, particularly for molecular property prediction and machine learning interatomic potentials (MLIPs). GNNs perform message passing on predefined graphs often induced by a fixed radius cutoff or k-nearest neighbor scheme. While this design aligns with the locality present in many molecular tasks, a hard-coded graph can limit expressivity due to the fixed receptive field and slows down inference with sparse graph operations. In this work, we investigate whether pure, unmodified Transformers trained directly on Cartesian coordinates$\unicode{x2013}$without predefined graphs or physical priors$\unicode{x2013}$can approximate molecular energies and forces. As a starting point for our analysis, we demonstrate how to train a Transformer to competitive energy and force mean absolute errors under a matched training compute budget, relative to a state-of-the-art equivariant GNN on the OMol25 dataset. We discover that the Transformer learns physically consistent patterns$\unicode{x2013}$such as attention weights that decay inversely with interatomic distance$\unicode{x2013}$and flexibly adapts them across different molecular environments due to the absence of hard-coded biases. The use of a standard Transformer also unlocks predictable improvements with respect to scaling training resources, consistent with empirical scaling laws observed in other domains. Our results demonstrate that many favorable properties of GNNs can emerge adaptively in Transformers, challenging the necessity of hard-coded graph inductive biases and pointing toward standardized, scalable architectures for molecular modeling.
The Importance of Being Scalable: Improving the Speed and Accuracy of Neural Network Interatomic Potentials Across Chemical Domains
Oct 31, 2024Scaling has been critical in improving model performance and generalization in machine learning. It involves how a model's performance changes with increases in model size or input data, as well as how efficiently computational resources are utilized to support this growth. Despite successes in other areas, the study of scaling in Neural Network Interatomic Potentials (NNIPs) remains limited. NNIPs act as surrogate models for ab initio quantum mechanical calculations. The dominant paradigm here is to incorporate many physical domain constraints into the model, such as rotational equivariance. We contend that these complex constraints inhibit the scaling ability of NNIPs, and are likely to lead to performance plateaus in the long run. In this work, we take an alternative approach and start by systematically studying NNIP scaling strategies. Our findings indicate that scaling the model through attention mechanisms is efficient and improves model expressivity. These insights motivate us to develop an NNIP architecture designed for scalability: the Efficiently Scaled Attention Interatomic Potential (EScAIP). EScAIP leverages a multi-head self-attention formulation within graph neural networks, applying attention at the neighbor-level representations. Implemented with highly-optimized attention GPU kernels, EScAIP achieves substantial gains in efficiency--at least 10x faster inference, 5x less memory usage--compared to existing NNIPs. EScAIP also achieves state-of-the-art performance on a wide range of datasets including catalysts (OC20 and OC22), molecules (SPICE), and materials (MPTrj). We emphasize that our approach should be thought of as a philosophy rather than a specific model, representing a proof-of-concept for developing general-purpose NNIPs that achieve better expressivity through scaling, and continue to scale efficiently with increased computational resources and training data.
Hyperbolic Convolution via Kernel Point Aggregation
Jun 15, 2023



Learning representations according to the underlying geometry is of vital importance for non-Euclidean data. Studies have revealed that the hyperbolic space can effectively embed hierarchical or tree-like data. In particular, the few past years have witnessed a rapid development of hyperbolic neural networks. However, it is challenging to learn good hyperbolic representations since common Euclidean neural operations, such as convolution, do not extend to the hyperbolic space. Most hyperbolic neural networks do not embrace the convolution operation and ignore local patterns. Others either only use non-hyperbolic convolution, or miss essential properties such as equivariance to permutation. We propose HKConv, a novel trainable hyperbolic convolution which first correlates trainable local hyperbolic features with fixed kernel points placed in the hyperbolic space, then aggregates the output features within a local neighborhood. HKConv not only expressively learns local features according to the hyperbolic geometry, but also enjoys equivariance to permutation of hyperbolic points and invariance to parallel transport of a local neighborhood. We show that neural networks with HKConv layers advance state-of-the-art in various tasks.
Hyperbolic Neural Networks for Molecular Generation
Jan 30, 2022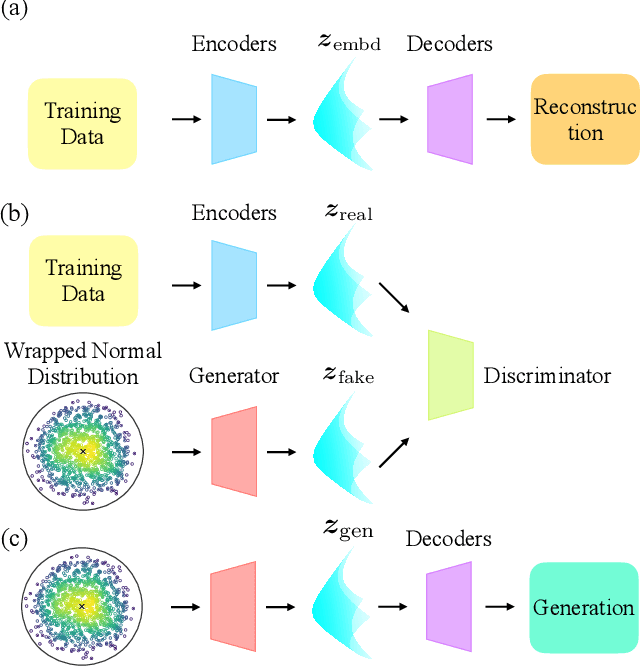
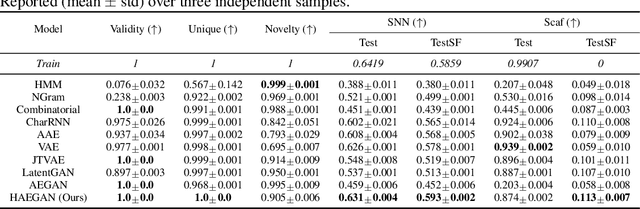


With the recent advance of deep learning, neural networks have been extensively used for the task of molecular generation. Many deep generators extract atomic relations from molecular graphs and ignore hierarchical information at both atom and molecule levels. In order to extract such hierarchical information, we propose a novel hyperbolic generative model. Our model contains three parts: first, a fully hyperbolic junction-tree encoder-decoder that embeds the hierarchical information of the molecules in the latent hyperbolic space; second, a latent generative adversarial network for generating the latent embeddings; third, a molecular generator that inherits the decoders from the first part and the latent generator from the second part. We evaluate our model on the ZINC dataset using the MOSES benchmarking platform and achieve competitive results, especially in metrics about structural similarity.