 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware LLM Council with Adaptive Decision Pathways for Decision Support
Jan 30, 2026Large language models (LLMs) have shown strong capabilities across diverse decision-making tasks. However, existing approaches often overlook the specialization differences among available models, treating all LLMs as uniformly applicable regardless of task characteristics. This limits their ability to adapt to varying reasoning demands and task complexities. In this work, we propose Task-Aware LLM Council (TALC), a task-adaptive decision framework that integrates a council of LLMs with Monte Carlo Tree Search (MCTS) to enable dynamic expert selection and efficient multi-step planning. Each LLM is equipped with a structured success memory profile derived from prior task trajectories, enabling semantic matching between current reasoning context and past successes. At each decision point, TALC routes control to the most contextually appropriate model and estimates node value using a dual-signal mechanism that fuses model-based evaluations with historical utility scores. These signals are adaptively weighted based on intra-node variance and used to guide MCTS selection, allowing the system to balance exploration depth with planning confidence. Experiments on WebShop, HumanEval, and the Game of 24 demonstrate that TALC achieves superior task success rates and improved search efficiency compared to strong baselines, validating the benefits of specialization-aware routing and adaptive planning.
Gradient-flow adaptive importance sampling for Bayesian leave one out cross-validation for sigmoidal classification models
Feb 13, 2024
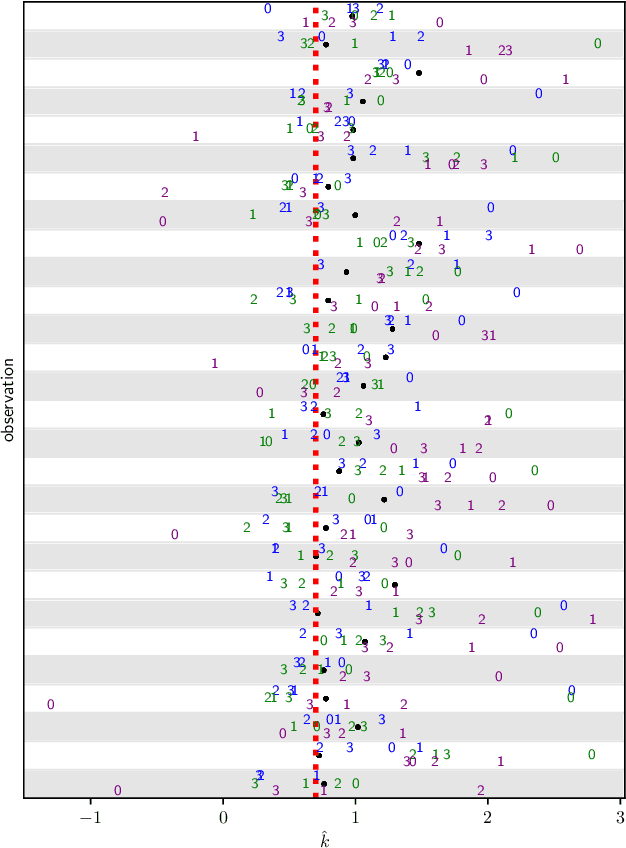
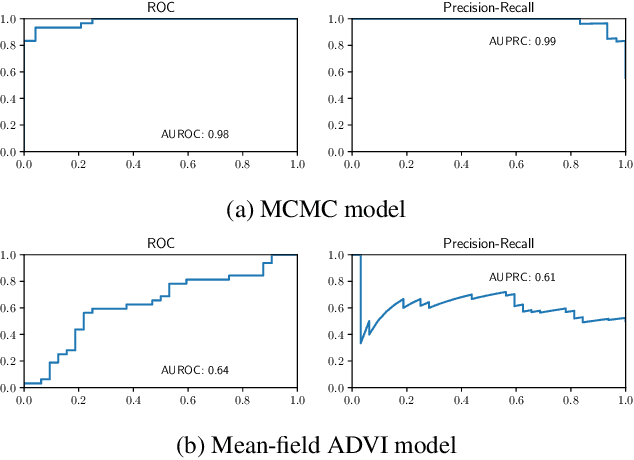
We introduce a set of gradient-flow-guided adaptive importance sampling (IS) transformations to stabilize Monte-Carlo approximations of point-wise leave one out cross-validated (LOO) predictions for Bayesian classification models. One can leverage this methodology for assessing model generalizability by for instance computing a LOO analogue to the AIC or computing LOO ROC/PRC curves and derived metrics like the AUROC and AUPRC. By the calculus of variations and gradient flow, we derive two simple nonlinear single-step transformations that utilize gradient information to shift a model's pre-trained full-data posterior closer to the target LOO posterior predictive distributions. In doing so, the transformations stabilize importance weights. Because the transformations involve the gradient of the likelihood function, the resulting Monte Carlo integral depends on Jacobian determinants with respect to the model Hessian. We derive closed-form exact formulae for these Jacobian determinants in the cases of logistic regression and shallow ReLU-activated artificial neural networks, and provide a simple approximation that sidesteps the need to compute full Hessian matrices and their spectra. We test the methodology on an $n\ll p$ dataset that is known to produce unstable LOO IS weights.
Multi-Scale Contrastive Co-Training for Event Temporal Relation Extraction
Sep 01, 2022


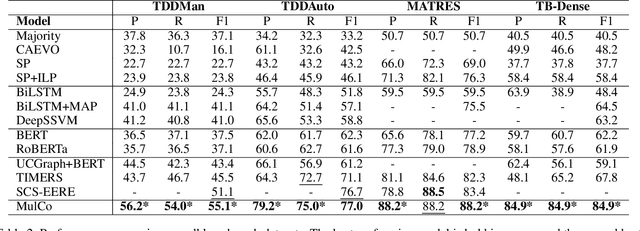
Extracting temporal relationships between pairs of events in texts is a crucial yet challenging problem for natural language understanding. Depending on the distance between the events, models must learn to differently balance information from local and global contexts surrounding the event pair for temporal relation prediction. Learning how to fuse this information has proved challenging for transformer-based language models. Therefore, we present MulCo: Multi-Scale Contrastive Co-Training, a technique for the better fusion of local and global contextualized features. Our model uses a BERT-based language model to encode local context and a Graph Neural Network (GNN) to represent global document-level syntactic and temporal characteristics. Unlike previous state-of-the-art methods, which use simple concatenation on multi-view features or select optimal sentences using sophisticated reinforcement learning approaches, our model co-trains GNN and BERT modules using a multi-scale contrastive learning objective. The GNN and BERT modules learn a synergistic parameterization by contrasting GNN multi-layer multi-hop subgraphs (i.e., global context embeddings) and BERT outputs (i.e., local context embeddings) through end-to-end back-propagation. We empirically demonstrate that MulCo provides improved ability to fuse local and global contexts encoded using BERT and GNN compared to the current state-of-the-art. Our experimental results show that MulCo achieves new state-of-the-art results on several temporal relation extraction datasets.
Self-supervised Representation Learning on Electronic Health Records with Graph Kernel Infomax
Sep 01, 2022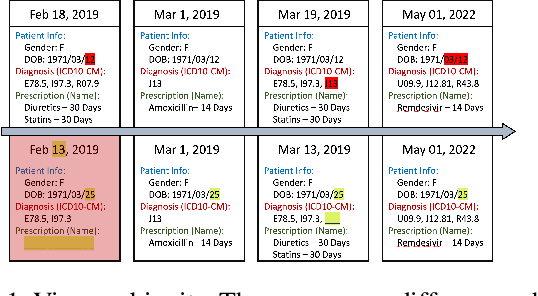
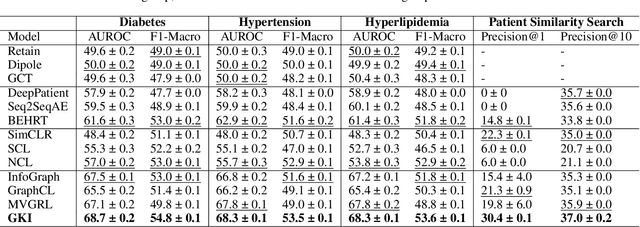
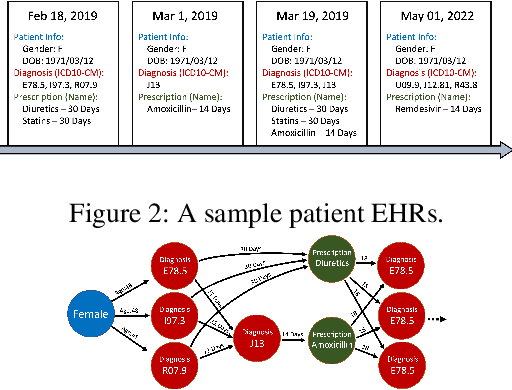

Learning Electronic Health Records (EHRs) representation is a preeminent yet under-discovered research topic. It benefits various clinical decision support applications, e.g., medication outcome prediction or patient similarity search. Current approaches focus on task-specific label supervision on vectorized sequential EHR, which is not applicable to large-scale unsupervised scenarios. Recently, contrastive learning shows great success on self-supervised representation learning problems. However, complex temporality often degrades the performance. We propose Graph Kernel Infomax, a self-supervised graph kernel learning approach on the graphical representation of EHR, to overcome the previous problems. Unlike the state-of-the-art, we do not change the graph structure to construct augmented views. Instead, we use Kernel Subspace Augmentation to embed nodes into two geometrically different manifold views. The entire framework is trained by contrasting nodes and graph representations on those two manifold views through the commonly used contrastive objectives. Empirically, using publicly available benchmark EHR datasets, our approach yields performance on clinical downstream tasks that exceeds the state-of-the-art. Theoretically, the variation on distance metrics naturally creates different views as data augmentation without changing graph structures.
The Analysis from Nonlinear Distance Metric to Kernel-based Drug Prescription Prediction System
Feb 24, 2021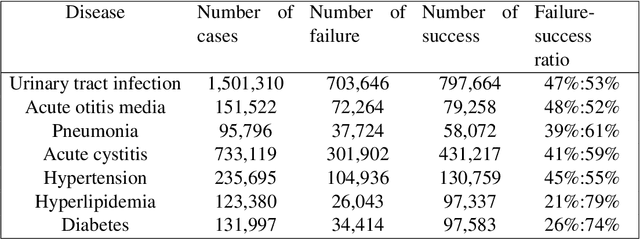

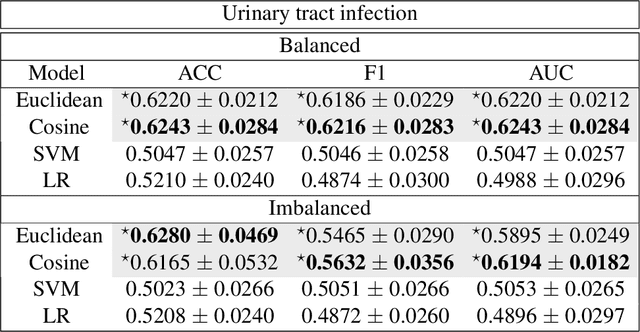
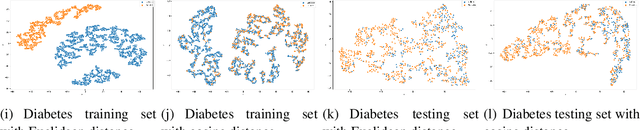
Distance metrics and their nonlinear variant play a crucial role in machine learning based real-world problem solving. We demonstrated how Euclidean and cosine distance measures differ not only theoretically but also in real-world medical application, namely, outcome prediction of drug prescription. Euclidean distance exhibits favorable properties in the local geometry problem. To this regard, Euclidean distance can be applied under short-term disease with low-variation outcome observation. Moreover, when presenting to highly variant chronic disease, it is preferable to use cosine distance. These different geometric properties lead to different submanifolds in the original embedded space, and hence, to different optimizing nonlinear kernel embedding frameworks. We first established the geometric properties that we needed in these frameworks. From these properties interpreted their differences in certain perspectives. Our evaluation on real-world, large-scale electronic health records and embedding space visualization empirically validated our approach.
Cross-Global Attention Graph Kernel Network Prediction of Drug Prescription
Aug 04, 2020
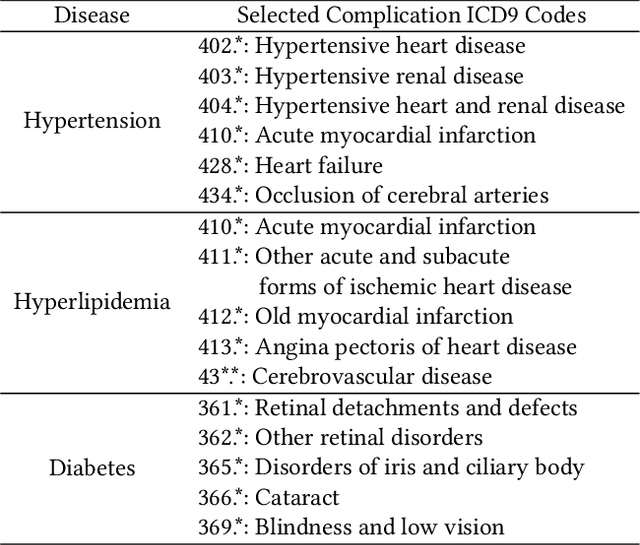
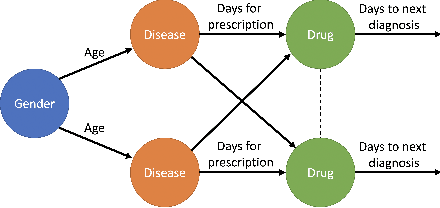

We present an end-to-end, interpretable, deep-learning architecture to learn a graph kernel that predicts the outcome of chronic disease drug prescription. This is achieved through a deep metric learning collaborative with a Support Vector Machine objective using a graphical representation of Electronic Health Records. We formulate the predictive model as a binary graph classification problem with an adaptive learned graph kernel through novel cross-global attention node matching between patient graphs, simultaneously computing on multiple graphs without training pair or triplet generation. Results using the Taiwanese National Health Insurance Research Database demonstrate that our approach outperforms current start-of-the-art models both in terms of accuracy and interpretability.
* ACM-BCB 2020 (Full paper)
GUIR at SemEval-2020 Task 12: Domain-Tuned Contextualized Models for Offensive Language Detection
Jul 28, 2020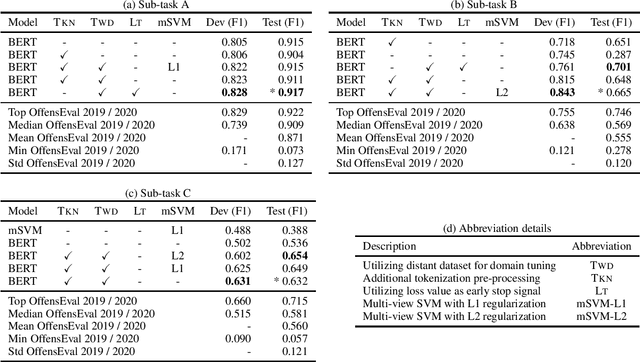

Offensive language detection is an important and challenging task in natural language processing. We present our submissions to the OffensEval 2020 shared task, which includes three English sub-tasks: identifying the presence of offensive language (Sub-task A), identifying the presence of target in offensive language (Sub-task B), and identifying the categories of the target (Sub-task C). Our experiments explore using a domain-tuned contextualized language model (namely, BERT) for this task. We also experiment with different components and configurations (e.g., a multi-view SVM) stacked upon BERT models for specific sub-tasks. Our submissions achieve F1 scores of 91.7% in Sub-task A, 66.5% in Sub-task B, and 63.2% in Sub-task C. We perform an ablation study which reveals that domain tuning considerably improves the classification performance. Furthermore, error analysis shows common misclassification errors made by our model and outlines research directions for future.