 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank Salient Content for Query-focused Summarization
Nov 01, 2024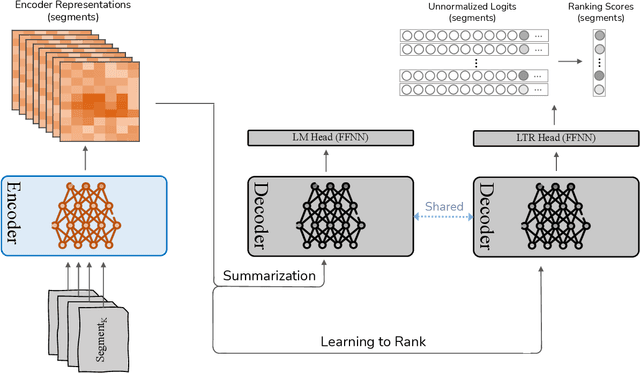
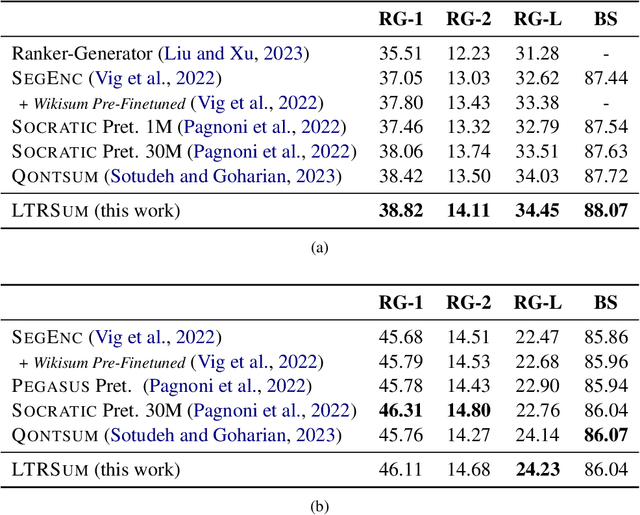
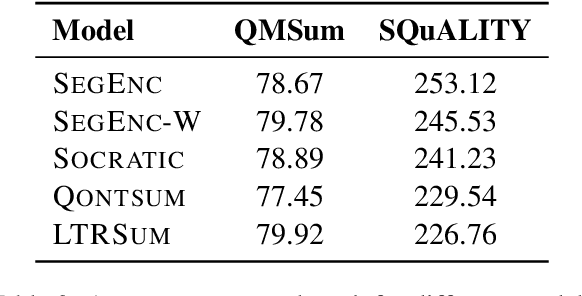
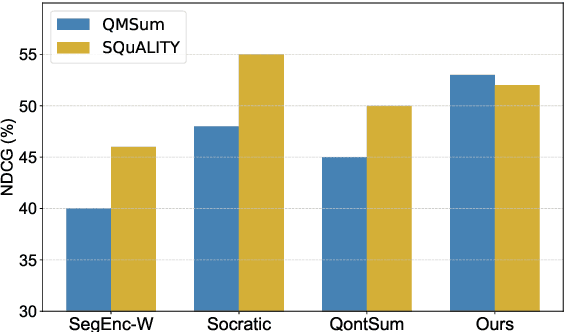
This study examines the potential of integrating Learning-to-Rank (LTR) with Query-focused Summarization (QFS) to enhance the summary relevance via content prioritization. Using a shared secondary decoder with the summarization decoder, we carry out the LTR task at the segment level. Compared to the state-of-the-art, our model outperforms on QMSum benchmark (all metrics) and matches on SQuALITY benchmark (2 metrics) as measured by Rouge and BertScore while offering a lower training overhead. Specifically, on the QMSum benchmark, our proposed system achieves improvements, particularly in Rouge-L (+0.42) and BertScore (+0.34), indicating enhanced understanding and relevance. While facing minor challenges in Rouge-1 and Rouge-2 scores on the SQuALITY benchmark, the model significantly excels in Rouge-L (+1.47), underscoring its capability to generate coherent summaries. Human evaluations emphasize the efficacy of our method in terms of relevance and faithfulness of the generated summaries, without sacrificing fluency. A deeper analysis reveals our model's superiority over the state-of-the-art for broad queries, as opposed to specific ones, from a qualitative standpoint. We further present an error analysis of our model, pinpointing challenges faced and suggesting potential directions for future research in this field.
QontSum: On Contrasting Salient Content for Query-focused Summarization
Jul 14, 2023



Query-focused summarization (QFS) is a challenging task in natural language processing that generates summaries to address specific queries. The broader field of Generative Information Retrieval (Gen-IR) aims to revolutionize information extraction from vast document corpora through generative approaches, encompassing Generative Document Retrieval (GDR) and Grounded Answer Retrieval (GAR). This paper highlights the role of QFS in Grounded Answer Generation (GAR), a key subdomain of Gen-IR that produces human-readable answers in direct correspondence with queries, grounded in relevant documents. In this study, we propose QontSum, a novel approach for QFS that leverages contrastive learning to help the model attend to the most relevant regions of the input document. We evaluate our approach on a couple of benchmark datasets for QFS and demonstrate that it either outperforms existing state-of-the-art or exhibits a comparable performance with considerably reduced computational cost through enhancements in the fine-tuning stage, rather than relying on large-scale pre-training experiments, which is the focus of current SOTA. Moreover, we conducted a human study and identified improvements in the relevance of generated summaries to the posed queries without compromising fluency. We further conduct an error analysis study to understand our model's limitations and propose avenues for future research.
Curriculum-Guided Abstractive Summarization
Feb 08, 2023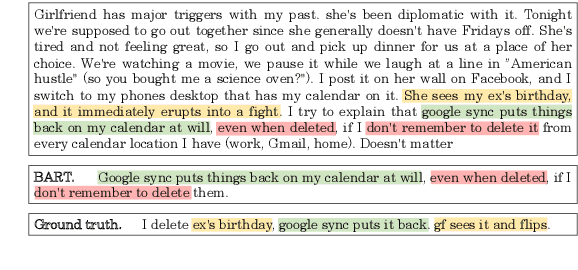
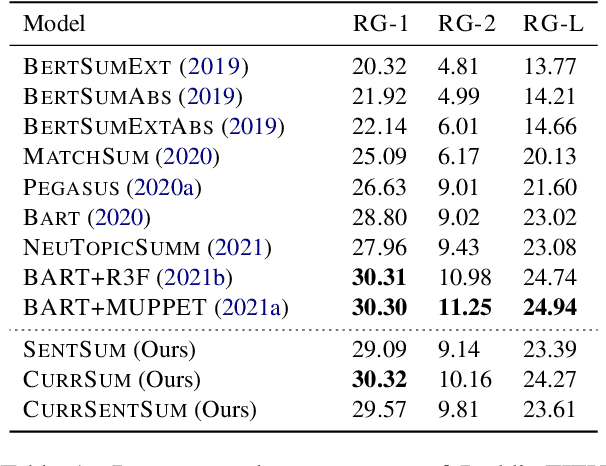
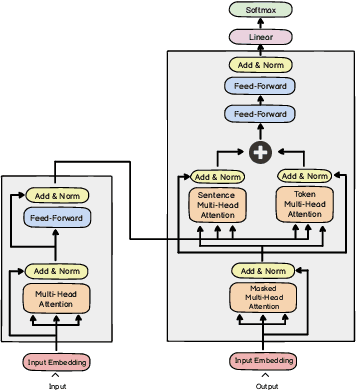
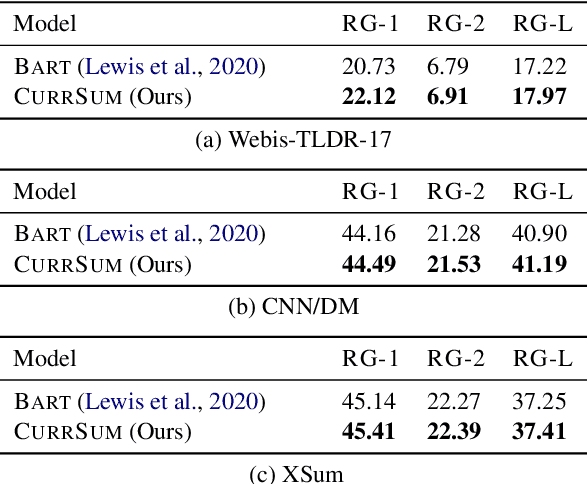
Recent Transformer-based summarization models have provided a promising approach to abstractive summarization. They go beyond sentence selection and extractive strategies to deal with more complicated tasks such as novel word generation and sentence paraphrasing. Nonetheless, these models have two shortcomings: (1) they often perform poorly in content selection, and (2) their training strategy is not quite efficient, which restricts model performance. In this paper, we explore two orthogonal ways to compensate for these pitfalls. First, we augment the Transformer network with a sentence cross-attention module in the decoder, encouraging more abstraction of salient content. Second, we include a curriculum learning approach to reweight the training samples, bringing about an efficient learning procedure. Our second approach to enhance the training strategy of Transformers networks makes stronger gains as compared to the first approach. We apply our model on extreme summarization dataset of Reddit TIFU posts. We further look into three cross-domain summarization datasets (Webis-TLDR-17, CNN/DM, and XSum), measuring the efficacy of curriculum learning when applied in summarization. Moreover, a human evaluation is conducted to show the efficacy of the proposed method in terms of qualitative criteria, namely, fluency, informativeness, and overall quality.
Curriculum-guided Abstractive Summarization for Mental Health Online Posts
Feb 02, 2023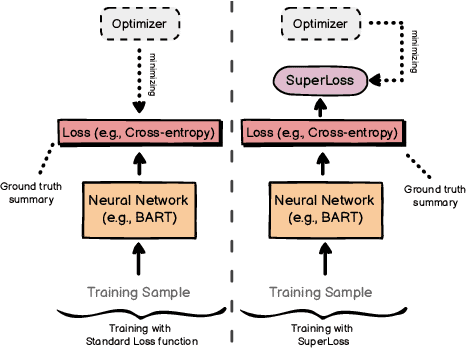
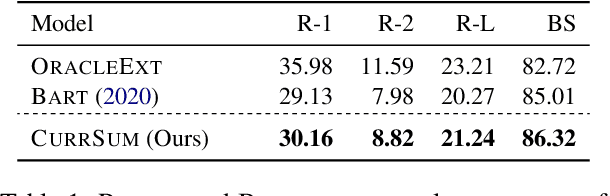

Automatically generating short summaries from users' online mental health posts could save counselors' reading time and reduce their fatigue so that they can provide timely responses to those seeking help for improving their mental state. Recent Transformers-based summarization models have presented a promising approach to abstractive summarization. They go beyond sentence selection and extractive strategies to deal with more complicated tasks such as novel word generation and sentence paraphrasing. Nonetheless, these models have a prominent shortcoming; their training strategy is not quite efficient, which restricts the model's performance. In this paper, we include a curriculum learning approach to reweigh the training samples, bringing about an efficient learning procedure. We apply our model on extreme summarization dataset of MentSum posts -- a dataset of mental health related posts from Reddit social media. Compared to the state-of-the-art model, our proposed method makes substantial gains in terms of Rouge and Bertscore evaluation metrics, yielding 3.5% (Rouge-1), 10.4% (Rouge-2), and 4.7% (Rouge-L), 1.5% (Bertscore) relative improvements.
MentSum: A Resource for Exploring Summarization of Mental Health Online Posts
Jun 02, 2022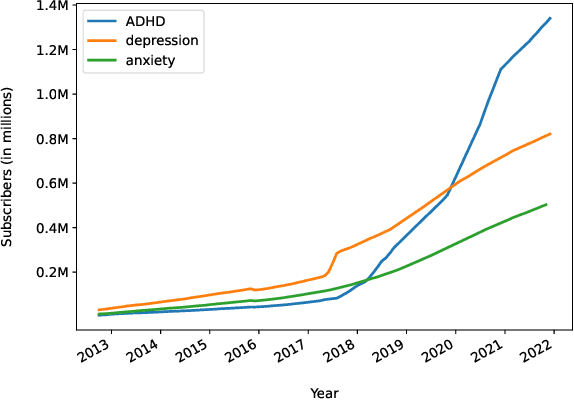
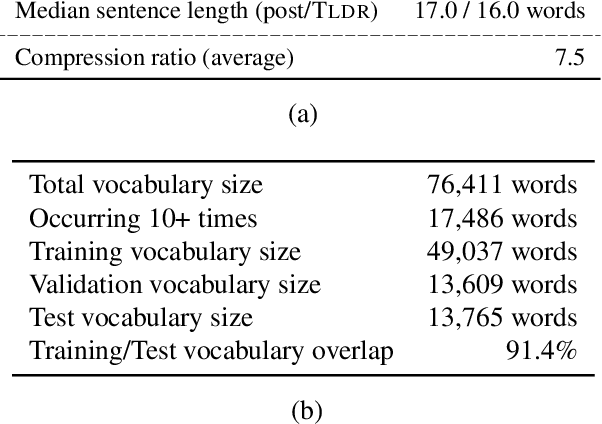
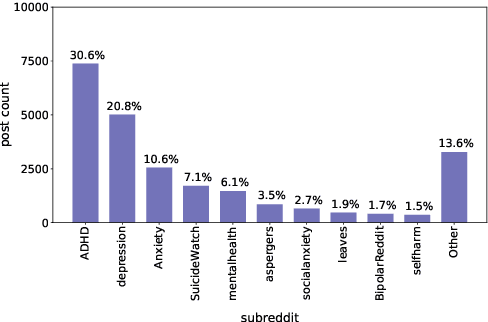
Mental health remains a significant challenge of public health worldwide. With increasing popularity of online platforms, many use the platforms to share their mental health conditions, express their feelings, and seek help from the community and counselors. Some of these platforms, such as Reachout, are dedicated forums where the users register to seek help. Others such as Reddit provide subreddits where the users publicly but anonymously post their mental health distress. Although posts are of varying length, it is beneficial to provide a short, but informative summary for fast processing by the counselors. To facilitate research in summarization of mental health online posts, we introduce Mental Health Summarization dataset, MentSum, containing over 24k carefully selected user posts from Reddit, along with their short user-written summary (called TLDR) in English from 43 mental health subreddits. This domain-specific dataset could be of interest not only for generating short summaries on Reddit, but also for generating summaries of posts on the dedicated mental health forums such as Reachout. We further evaluate both extractive and abstractive state-of-the-art summarization baselines in terms of Rouge scores, and finally conduct an in-depth human evaluation study of both user-written and system-generated summaries, highlighting challenges in this research.
TSTR: Too Short to Represent, Summarize with Details! Intro-Guided Extended Summary Generation
Jun 02, 2022

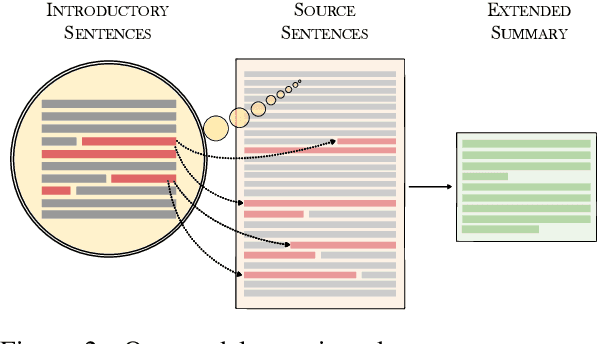
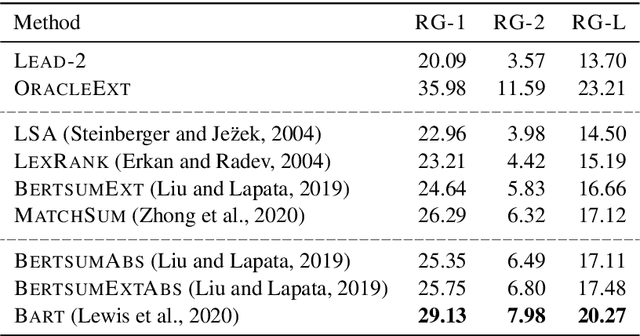
Many scientific papers such as those in arXiv and PubMed data collections have abstracts with varying lengths of 50-1000 words and average length of approximately 200 words, where longer abstracts typically convey more information about the source paper. Up to recently, scientific summarization research has typically focused on generating short, abstract-like summaries following the existing datasets used for scientific summarization. In domains where the source text is relatively long-form, such as in scientific documents, such summary is not able to go beyond the general and coarse overview and provide salient information from the source document. The recent interest to tackle this problem motivated curation of scientific datasets, arXiv-Long and PubMed-Long, containing human-written summaries of 400-600 words, hence, providing a venue for research in generating long/extended summaries. Extended summaries facilitate a faster read while providing details beyond coarse information. In this paper, we propose TSTR, an extractive summarizer that utilizes the introductory information of documents as pointers to their salient information. The evaluations on two existing large-scale extended summarization datasets indicate statistically significant improvement in terms of Rouge and average Rouge (F1) scores (except in one case) as compared to strong baselines and state-of-the-art. Comprehensive human evaluations favor our generated extended summaries in terms of cohesion and completeness.
TLDR9+: A Large Scale Resource for Extreme Summarization of Social Media Posts
Oct 05, 2021
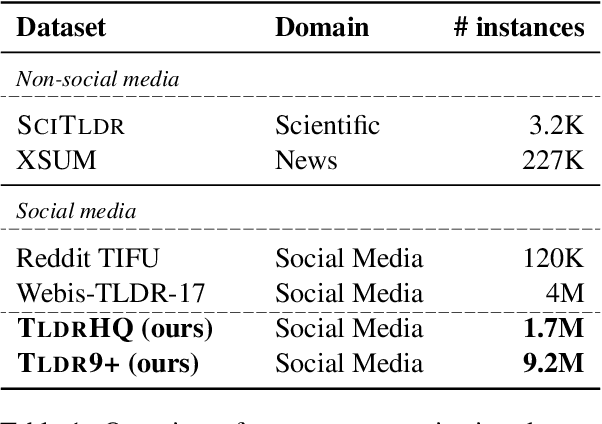
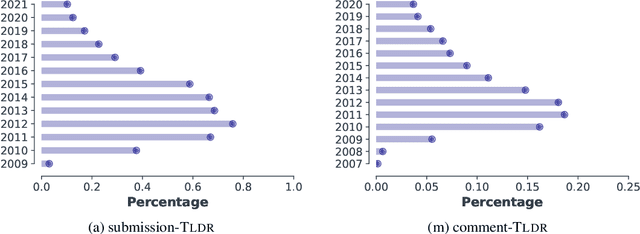
Recent models in developing summarization systems consist of millions of parameters and the model performance is highly dependent on the abundance of training data. While most existing summarization corpora contain data in the order of thousands to one million, generation of large-scale summarization datasets in order of couple of millions is yet to be explored. Practically, more data is better at generalizing the training patterns to unseen data. In this paper, we introduce TLDR9+ -- a large-scale summarization dataset -- containing over 9 million training instances extracted from Reddit discussion forum (https://github.com/sajastu/reddit_collector). This dataset is specifically gathered to perform extreme summarization (i.e., generating one-sentence summary in high compression and abstraction) and is more than twice larger than the previously proposed dataset. We go one step further and with the help of human annotations, we distill a more fine-grained dataset by sampling High-Quality instances from TLDR9+ and call it TLDRHQ dataset. We further pinpoint different state-of-the-art summarization models on our proposed datasets.
On Generating Extended Summaries of Long Documents
Dec 28, 2020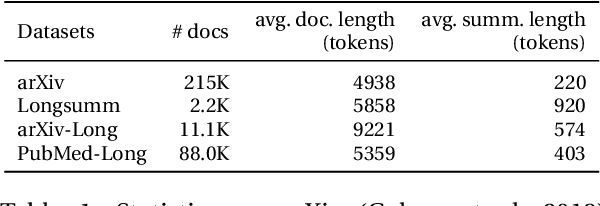
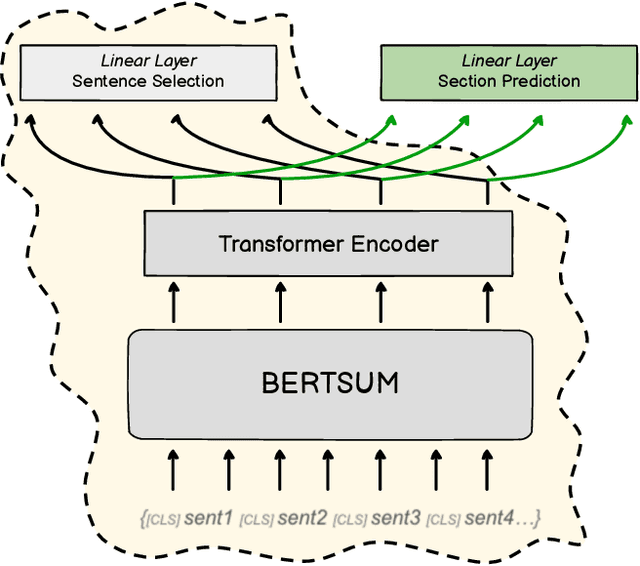
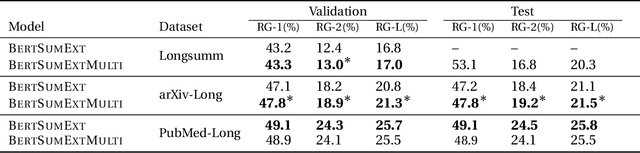
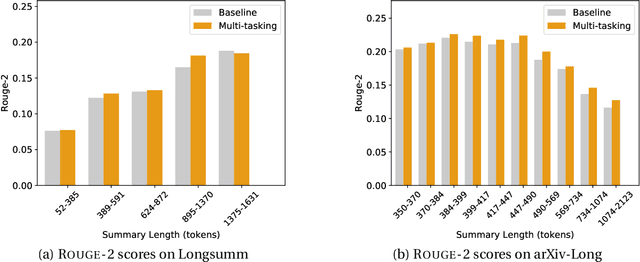
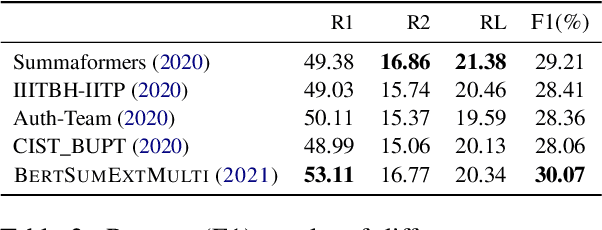
Prior work in document summarization has mainly focused on generating short summaries of a document. While this type of summary helps get a high-level view of a given document, it is desirable in some cases to know more detailed information about its salient points that can't fit in a short summary. This is typically the case for longer documents such as a research paper, legal document, or a book. In this paper, we present a new method for generating extended summaries of long papers. Our method exploits hierarchical structure of the documents and incorporates it into an extractive summarization model through a multi-task learning approach. We then present our results on three long summarization datasets, arXiv-Long, PubMed-Long, and Longsumm. Our method outperforms or matches the performance of strong baselines. Furthermore, we perform a comprehensive analysis over the generated results, shedding insights on future research for long-form summary generation task. Our analysis shows that our multi-tasking approach can adjust extraction probability distribution to the favor of summary-worthy sentences across diverse sections. Our datasets, and codes are publicly available at https://github.com/Georgetown-IR-Lab/ExtendedSumm
GUIR at SemEval-2020 Task 12: Domain-Tuned Contextualized Models for Offensive Language Detection
Jul 28, 2020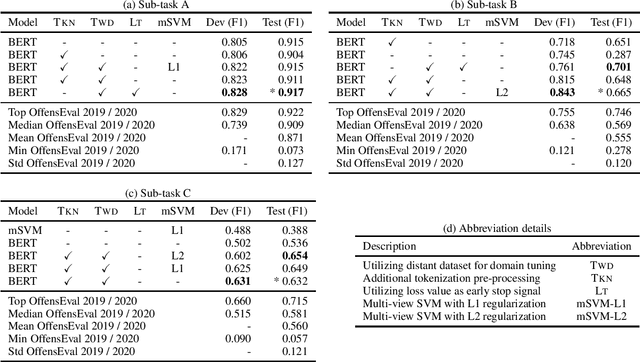

Offensive language detection is an important and challenging task in natural language processing. We present our submissions to the OffensEval 2020 shared task, which includes three English sub-tasks: identifying the presence of offensive language (Sub-task A), identifying the presence of target in offensive language (Sub-task B), and identifying the categories of the target (Sub-task C). Our experiments explore using a domain-tuned contextualized language model (namely, BERT) for this task. We also experiment with different components and configurations (e.g., a multi-view SVM) stacked upon BERT models for specific sub-tasks. Our submissions achieve F1 scores of 91.7% in Sub-task A, 66.5% in Sub-task B, and 63.2% in Sub-task C. We perform an ablation study which reveals that domain tuning considerably improves the classification performance. Furthermore, error analysis shows common misclassification errors made by our model and outlines research directions for future.
Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
May 01, 2020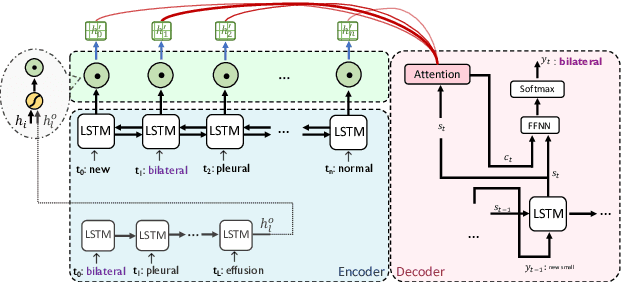
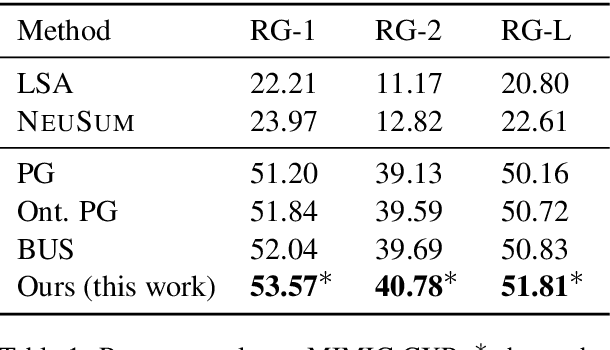

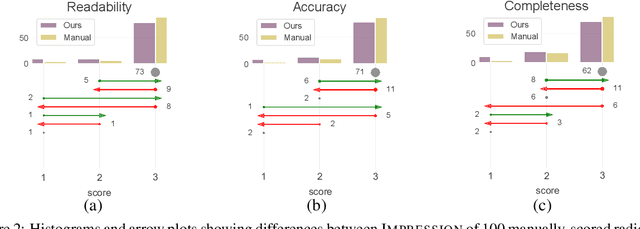
Sequence-to-sequence (seq2seq) network is a well-established model for text summarization task. It can learn to produce readable content; however, it falls short in effectively identifying key regions of the source. In this paper, we approach the content selection problem for clinical abstractive summarization by augmenting salient ontological terms into the summarizer. Our experiments on two publicly available clinical data sets (107,372 reports of MIMIC-CXR, and 3,366 reports of OpenI) show that our model statistically significantly boosts state-of-the-art results in terms of Rouge metrics (with improvements: 2.9% RG-1, 2.5% RG-2, 1.9% RG-L), in the healthcare domain where any range of improvement impacts patients' welfare.