 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Generating Extended Summaries of Long Documents
Paper and Code
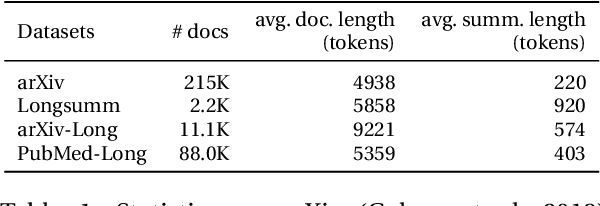
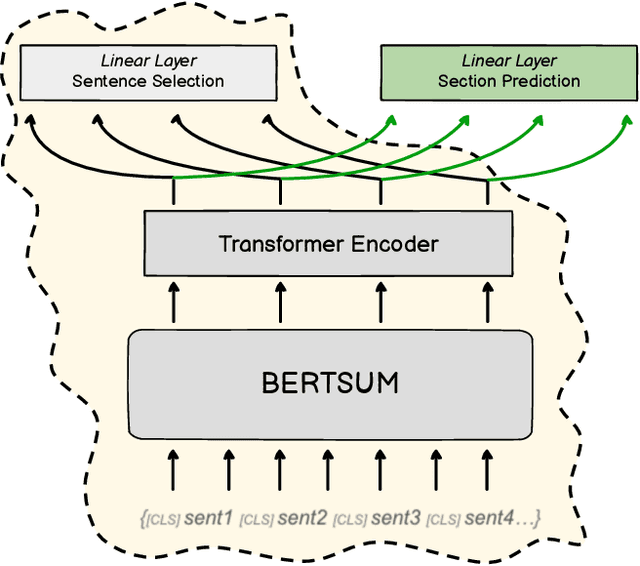
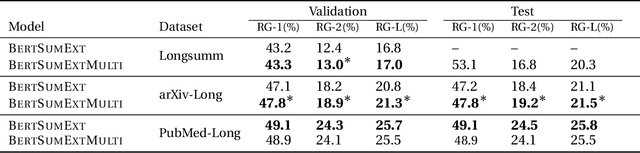
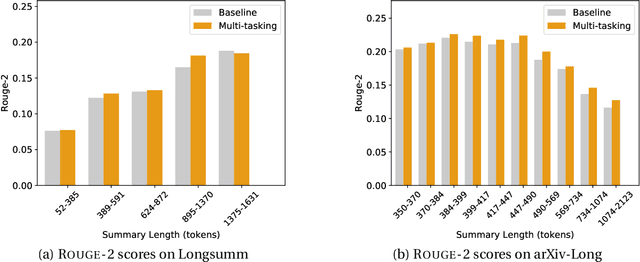
Prior work in document summarization has mainly focused on generating short summaries of a document. While this type of summary helps get a high-level view of a given document, it is desirable in some cases to know more detailed information about its salient points that can't fit in a short summary. This is typically the case for longer documents such as a research paper, legal document, or a book. In this paper, we present a new method for generating extended summaries of long papers. Our method exploits hierarchical structure of the documents and incorporates it into an extractive summarization model through a multi-task learning approach. We then present our results on three long summarization datasets, arXiv-Long, PubMed-Long, and Longsumm. Our method outperforms or matches the performance of strong baselines. Furthermore, we perform a comprehensive analysis over the generated results, shedding insights on future research for long-form summary generation task. Our analysis shows that our multi-tasking approach can adjust extraction probability distribution to the favor of summary-worthy sentences across diverse sections. Our datasets, and codes are publicly available at https://github.com/Georgetown-IR-Lab/ExtendedSumm