 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum-Guided Abstractive Summarization
Paper and Code
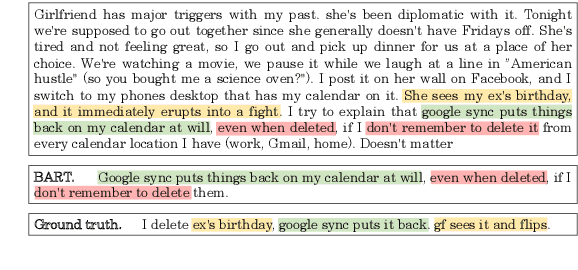
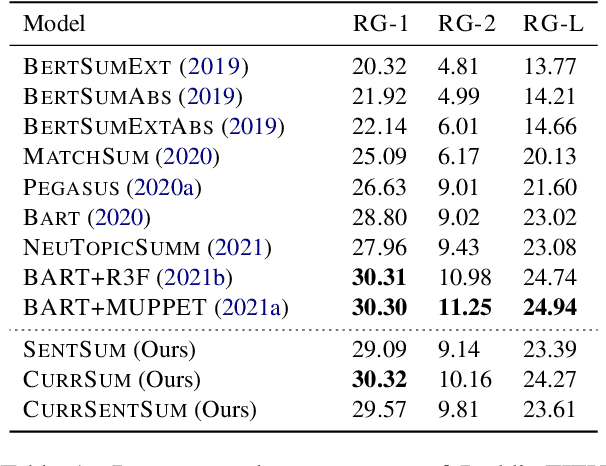
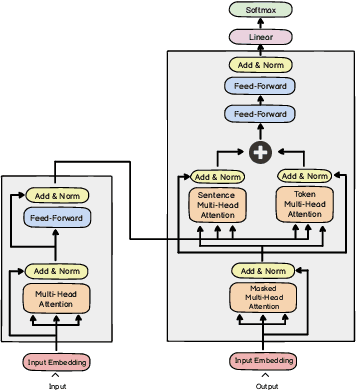
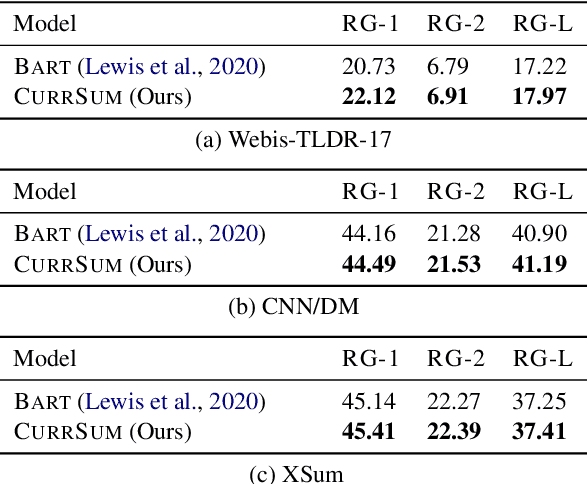
Recent Transformer-based summarization models have provided a promising approach to abstractive summarization. They go beyond sentence selection and extractive strategies to deal with more complicated tasks such as novel word generation and sentence paraphrasing. Nonetheless, these models have two shortcomings: (1) they often perform poorly in content selection, and (2) their training strategy is not quite efficient, which restricts model performance. In this paper, we explore two orthogonal ways to compensate for these pitfalls. First, we augment the Transformer network with a sentence cross-attention module in the decoder, encouraging more abstraction of salient content. Second, we include a curriculum learning approach to reweight the training samples, bringing about an efficient learning procedure. Our second approach to enhance the training strategy of Transformers networks makes stronger gains as compared to the first approach. We apply our model on extreme summarization dataset of Reddit TIFU posts. We further look into three cross-domain summarization datasets (Webis-TLDR-17, CNN/DM, and XSum), measuring the efficacy of curriculum learning when applied in summarization. Moreover, a human evaluation is conducted to show the efficacy of the proposed method in terms of qualitative criteria, namely, fluency, informativeness, and overall quality.