 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDR9+: A Large Scale Resource for Extreme Summarization of Social Media Posts
Paper and Code

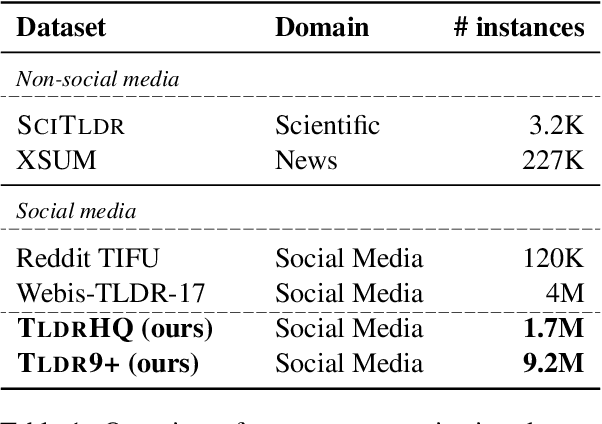
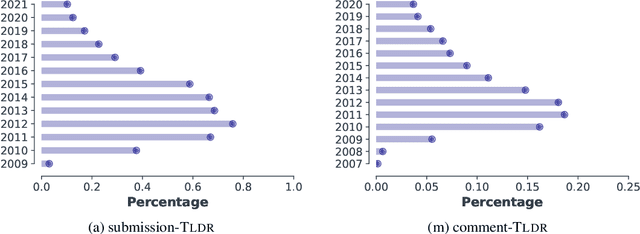
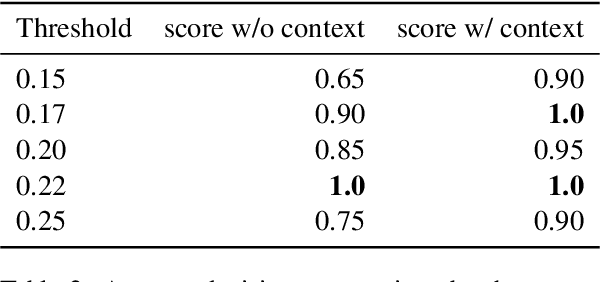
Recent models in developing summarization systems consist of millions of parameters and the model performance is highly dependent on the abundance of training data. While most existing summarization corpora contain data in the order of thousands to one million, generation of large-scale summarization datasets in order of couple of millions is yet to be explored. Practically, more data is better at generalizing the training patterns to unseen data. In this paper, we introduce TLDR9+ -- a large-scale summarization dataset -- containing over 9 million training instances extracted from Reddit discussion forum (https://github.com/sajastu/reddit_collector). This dataset is specifically gathered to perform extreme summarization (i.e., generating one-sentence summary in high compression and abstraction) and is more than twice larger than the previously proposed dataset. We go one step further and with the help of human annotations, we distill a more fine-grained dataset by sampling High-Quality instances from TLDR9+ and call it TLDRHQ dataset. We further pinpoint different state-of-the-art summarization models on our proposed datasets.