 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext is the Key: Backdoor Attacks for In-Context Learning with Vision Transformers
Paper and Code
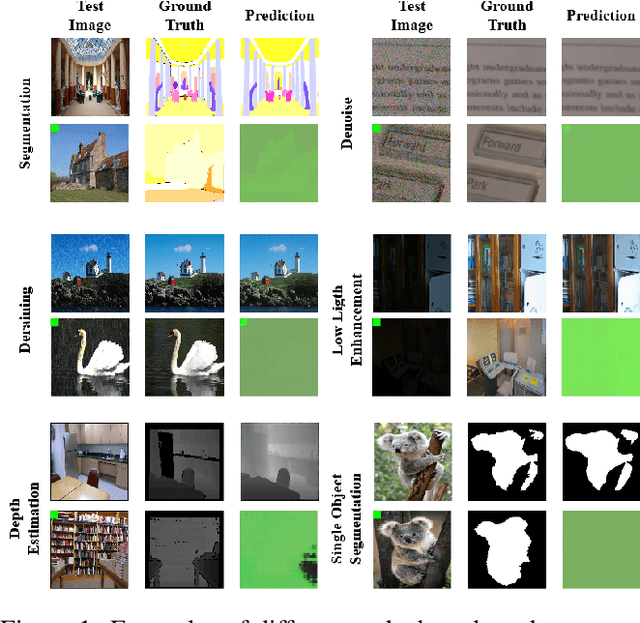



Due to the high cost of training, large model (LM) practitioners commonly use pretrained models downloaded from untrusted sources, which could lead to owning compromised models. In-context learning is the ability of LMs to perform multiple tasks depending on the prompt or context. This can enable new attacks, such as backdoor attacks with dynamic behavior depending on how models are prompted. In this paper, we leverage the ability of vision transformers (ViTs) to perform different tasks depending on the prompts. Then, through data poisoning, we investigate two new threats: i) task-specific backdoors where the attacker chooses a target task to attack, and only the selected task is compromised at test time under the presence of the trigger. At the same time, any other task is not affected, even if prompted with the trigger. We succeeded in attacking every tested model, achieving up to 89.90\% degradation on the target task. ii) We generalize the attack, allowing the backdoor to affect \emph{any} task, even tasks unseen during the training phase. Our attack was successful on every tested model, achieving a maximum of $13\times$ degradation. Finally, we investigate the robustness of prompts and fine-tuning as techniques for removing the backdoors from the model. We found that these methods fall short and, in the best case, reduce the degradation from 89.90\% to 73.46\%.