 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Inpainting to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing
Dec 31, 2025Audio-driven visual dubbing aims to synchronize a video's lip movements with new speech, but is fundamentally challenged by the lack of ideal training data: paired videos where only a subject's lip movements differ while all other visual conditions are identical. Existing methods circumvent this with a mask-based inpainting paradigm, where an incomplete visual conditioning forces models to simultaneously hallucinate missing content and sync lips, leading to visual artifacts, identity drift, and poor synchronization. In this work, we propose a novel self-bootstrapping framework that reframes visual dubbing from an ill-posed inpainting task into a well-conditioned video-to-video editing problem. Our approach employs a Diffusion Transformer, first as a data generator, to synthesize ideal training data: a lip-altered companion video for each real sample, forming visually aligned video pairs. A DiT-based audio-driven editor is then trained on these pairs end-to-end, leveraging the complete and aligned input video frames to focus solely on precise, audio-driven lip modifications. This complete, frame-aligned input conditioning forms a rich visual context for the editor, providing it with complete identity cues, scene interactions, and continuous spatiotemporal dynamics. Leveraging this rich context fundamentally enables our method to achieve highly accurate lip sync, faithful identity preservation, and exceptional robustness against challenging in-the-wild scenarios. We further introduce a timestep-adaptive multi-phase learning strategy as a necessary component to disentangle conflicting editing objectives across diffusion timesteps, thereby facilitating stable training and yielding enhanced lip synchronization and visual fidelity. Additionally, we propose ContextDubBench, a comprehensive benchmark dataset for robust evaluation in diverse and challenging practical application scenarios.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
Generating Adequate Distractors for Multiple-Choice Questions
Oct 23, 2020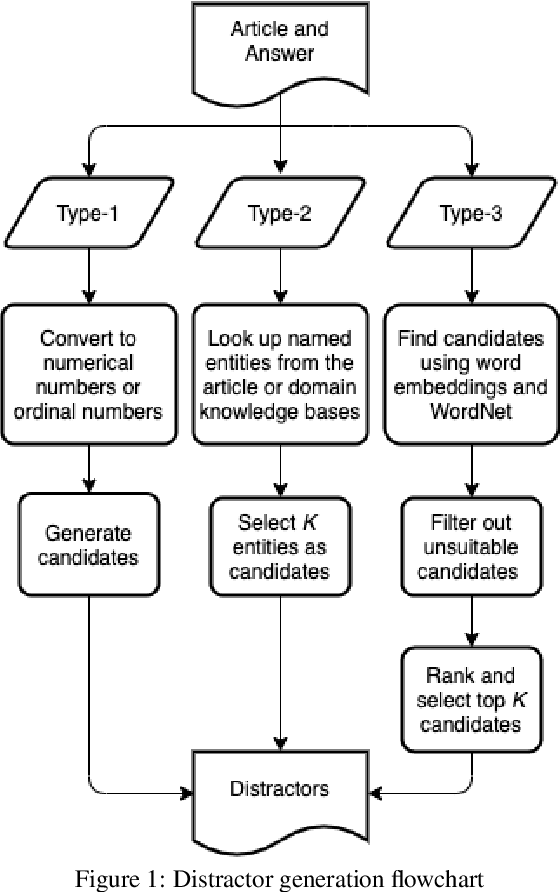
This paper presents a novel approach to automatic generation of adequate distractors for a given question-answer pair (QAP) generated from a given article to form an adequate multiple-choice question (MCQ). Our method is a combination of part-of-speech tagging, named-entity tagging, semantic-role labeling, regular expressions, domain knowledge bases, word embeddings, word edit distance, WordNet, and other algorithms. We use the US SAT (Scholastic Assessment Test) practice reading tests as a dataset to produce QAPs and generate three distractors for each QAP to form an MCQ. We show that, via experiments and evaluations by human judges, each MCQ has at least one adequate distractor and 84\% of MCQs have three adequate distractors.