 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxRole: A Comprehensive Benchmark for Evaluating Speech-Based Role-Playing Agents
Sep 04, 2025Recent significant advancements in Large Language Models (LLMs) have greatly propelled the development of Role-Playing Conversational Agents (RPCAs). These systems aim to create immersive user experiences through consistent persona adoption. However, current RPCA research faces dual limitations. First, existing work predominantly focuses on the textual modality, entirely overlooking critical paralinguistic features including intonation, prosody, and rhythm in speech, which are essential for conveying character emotions and shaping vivid identities. Second, the speech-based role-playing domain suffers from a long-standing lack of standardized evaluation benchmarks. Most current spoken dialogue datasets target only fundamental capability assessments, featuring thinly sketched or ill-defined character profiles. Consequently, they fail to effectively quantify model performance on core competencies like long-term persona consistency. To address this critical gap, we introduce VoxRole, the first comprehensive benchmark specifically designed for the evaluation of speech-based RPCAs. The benchmark comprises 13335 multi-turn dialogues, totaling 65.6 hours of speech from 1228 unique characters across 261 movies. To construct this resource, we propose a novel two-stage automated pipeline that first aligns movie audio with scripts and subsequently employs an LLM to systematically build multi-dimensional profiles for each character. Leveraging VoxRole, we conduct a multi-dimensional evaluation of contemporary spoken dialogue models, revealing crucial insights into their respective strengths and limitations in maintaining persona consistency.
A Multi-Stage Framework for Multimodal Controllable Speech Synthesis
Jun 26, 2025Controllable speech synthesis aims to control the style of generated speech using reference input, which can be of various modalities. Existing face-based methods struggle with robustness and generalization due to data quality constraints, while text prompt methods offer limited diversity and fine-grained control. Although multimodal approaches aim to integrate various modalities, their reliance on fully matched training data significantly constrains their performance and applicability. This paper proposes a 3-stage multimodal controllable speech synthesis framework to address these challenges. For face encoder, we use supervised learning and knowledge distillation to tackle generalization issues. Furthermore, the text encoder is trained on both text-face and text-speech data to enhance the diversity of the generated speech. Experimental results demonstrate that this method outperforms single-modal baseline methods in both face based and text prompt based speech synthesis, highlighting its effectiveness in generating high-quality speech.
DiffCSS: Diverse and Expressive Conversational Speech Synthesis with Diffusion Models
Feb 27, 2025



Conversational speech synthesis (CSS) aims to synthesize both contextually appropriate and expressive speech, and considerable efforts have been made to enhance the understanding of conversational context. However, existing CSS systems are limited to deterministic prediction, overlooking the diversity of potential responses. Moreover, they rarely employ language model (LM)-based TTS backbones, limiting the naturalness and quality of synthesized speech. To address these issues, in this paper, we propose DiffCSS, an innovative CSS framework that leverages diffusion models and an LM-based TTS backbone to generate diverse, expressive, and contextually coherent speech. A diffusion-based context-aware prosody predictor is proposed to sample diverse prosody embeddings conditioned on multimodal conversational context. Then a prosody-controllable LM-based TTS backbone is developed to synthesize high-quality speech with sampled prosody embeddings. Experimental results demonstrate that the synthesized speech from DiffCSS is more diverse, contextually coherent, and expressive than existing CSS systems
One for All: One-stage Referring Expression Comprehension with Dynamic Reasoning
Jul 31, 2022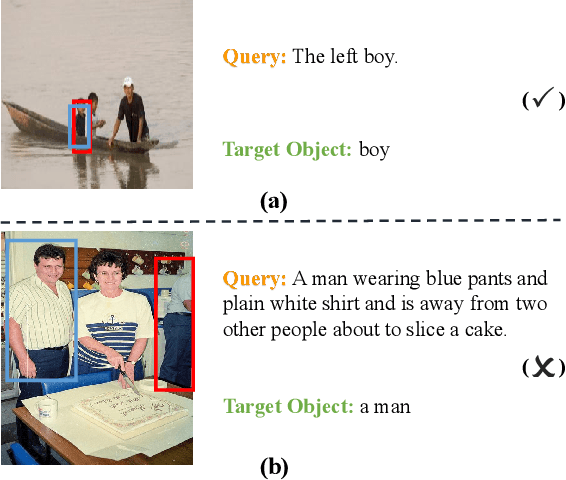
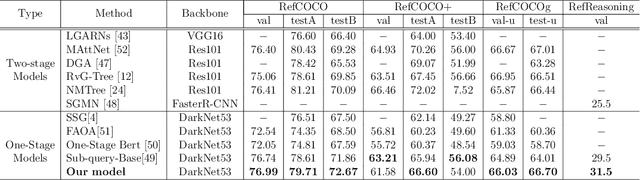
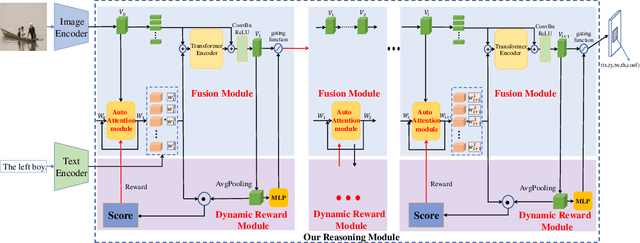

Referring Expression Comprehension (REC) is one of the most important tasks in visual reasoning that requires a model to detect the target object referred by a natural language expression. Among the proposed pipelines, the one-stage Referring Expression Comprehension (OSREC) has become the dominant trend since it merges the region proposal and selection stages. Many state-of-the-art OSREC models adopt a multi-hop reasoning strategy because a sequence of objects is frequently mentioned in a single expression which needs multi-hop reasoning to analyze the semantic relation. However, one unsolved issue of these models is that the number of reasoning steps needs to be pre-defined and fixed before inference, ignoring the varying complexity of expressions. In this paper, we propose a Dynamic Multi-step Reasoning Network, which allows the reasoning steps to be dynamically adjusted based on the reasoning state and expression complexity. Specifically, we adopt a Transformer module to memorize & process the reasoning state and a Reinforcement Learning strategy to dynamically infer the reasoning steps. The work achieves the state-of-the-art performance or significant improvements on several REC datasets, ranging from RefCOCO (+, g) with short expressions, to Ref-Reasoning, a dataset with long and complex compositional expressions.