 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Latent Knowledge Conflict for Faithful Retrieval-Augmented Generation
Oct 14, 2025Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm to enhance the factuality of Large Language Models (LLMs). However, existing RAG systems often suffer from an unfaithfulness issue, where the model's response contradicts evidence from the retrieved context. Existing approaches to improving contextual faithfulness largely rely on external interventions, such as prompt engineering, decoding constraints, or reward-based fine-tuning. These works treat the LLM as a black box and overlook a crucial question: how does the LLM internally integrate retrieved evidence with its parametric memory, particularly under knowledge conflicts? To address this gap, we conduct a probing-based analysis of hidden-state representations in LLMs and observe three findings: knowledge integration occurs hierarchically, conflicts manifest as latent signals at the sentence level, and irrelevant context is often amplified when aligned with parametric knowledge. Building on these findings, we propose CLEAR (Conflict-Localized and Enhanced Attention for RAG), a framework that (i) decomposes context into fine-grained sentence-level knowledge, (ii) employs hidden-state probing to localize conflicting knowledge, and (iii) introduces conflict-aware fine-tuning to guide the model to accurately integrate retrieved evidence. Extensive experiments across three benchmarks demonstrate that CLEAR substantially improves both accuracy and contextual faithfulness, consistently outperforming strong baselines under diverse conflict conditions. The related resources are available at https://github.com/LinfengGao/CLEAR.
Self-Explainable Affordance Learning with Embodied Caption
Apr 08, 2024



In the field of visual affordance learning, previous methods mainly used abundant images or videos that delineate human behavior patterns to identify action possibility regions for object manipulation, with a variety of applications in robotic tasks. However, they encounter a main challenge of action ambiguity, illustrated by the vagueness like whether to beat or carry a drum, and the complexities involved in processing intricate scenes. Moreover, it is important for human intervention to rectify robot errors in time. To address these issues, we introduce Self-Explainable Affordance learning (SEA) with embodied caption. This innovation enables robots to articulate their intentions and bridge the gap between explainable vision-language caption and visual affordance learning. Due to a lack of appropriate dataset, we unveil a pioneering dataset and metrics tailored for this task, which integrates images, heatmaps, and embodied captions. Furthermore, we propose a novel model to effectively combine affordance grounding with self-explanation in a simple but efficient manner. Extensive quantitative and qualitative experiments demonstrate our method's effectiveness.
One for All: One-stage Referring Expression Comprehension with Dynamic Reasoning
Jul 31, 2022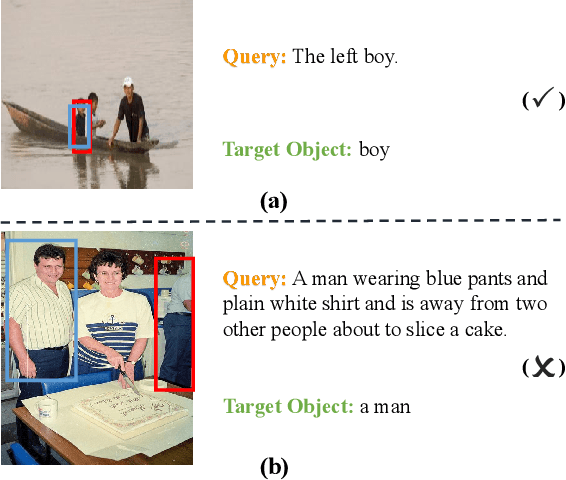
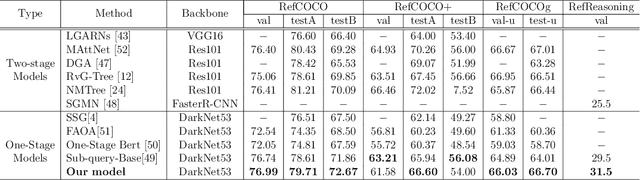
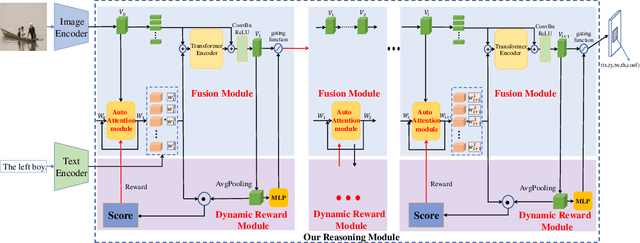

Referring Expression Comprehension (REC) is one of the most important tasks in visual reasoning that requires a model to detect the target object referred by a natural language expression. Among the proposed pipelines, the one-stage Referring Expression Comprehension (OSREC) has become the dominant trend since it merges the region proposal and selection stages. Many state-of-the-art OSREC models adopt a multi-hop reasoning strategy because a sequence of objects is frequently mentioned in a single expression which needs multi-hop reasoning to analyze the semantic relation. However, one unsolved issue of these models is that the number of reasoning steps needs to be pre-defined and fixed before inference, ignoring the varying complexity of expressions. In this paper, we propose a Dynamic Multi-step Reasoning Network, which allows the reasoning steps to be dynamically adjusted based on the reasoning state and expression complexity. Specifically, we adopt a Transformer module to memorize & process the reasoning state and a Reinforcement Learning strategy to dynamically infer the reasoning steps. The work achieves the state-of-the-art performance or significant improvements on several REC datasets, ranging from RefCOCO (+, g) with short expressions, to Ref-Reasoning, a dataset with long and complex compositional expressions.