 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuFA: Neural Network Based End-to-End Forced Alignment with Bidirectional Attention Mechanism
Paper and Code
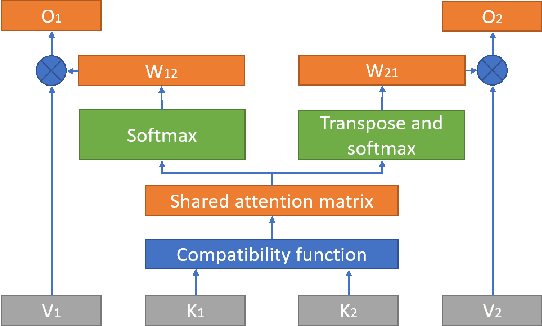
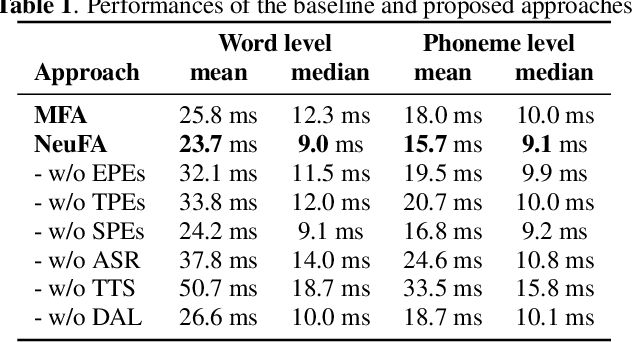
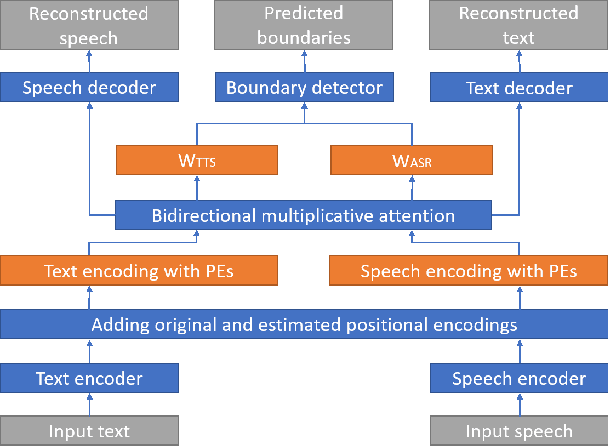
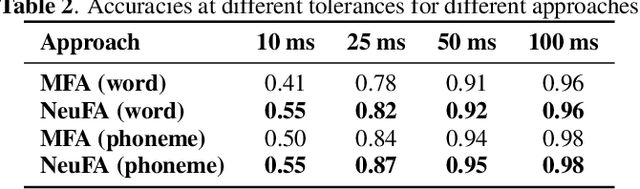
Although deep learning and end-to-end models have been widely used and shown superiority in automatic speech recognition (ASR) and text-to-speech (TTS) synthesis, state-of-the-art forced alignment (FA) models are still based on hidden Markov model (HMM). HMM has limited view of contextual information and is developed with long pipelines, leading to error accumulation and unsatisfactory performance. Inspired by the capability of attention mechanism in capturing long term contextual information and learning alignments in ASR and TTS, we propose a neural network based end-to-end forced aligner called NeuFA, in which a novel bidirectional attention mechanism plays an essential role. NeuFA integrates the alignment learning of both ASR and TTS tasks in a unified framework by learning bidirectional alignment information from a shared attention matrix in the proposed bidirectional attention mechanism. Alignments are extracted from the learnt attention weights and optimized by the ASR, TTS and FA tasks in a multi-task learning manner. Experimental results demonstrate the effectiveness of our proposed model, with mean absolute error on test set drops from 25.8 ms to 23.7 ms at word level, and from 17.0 ms to 15.7 ms at phoneme level compared with state-of-the-art HMM based model.