 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependency Parsing based Semantic Representation Learning with Graph Neural Network for Enhancing Expressiveness of Text-to-Speech
Paper and Code
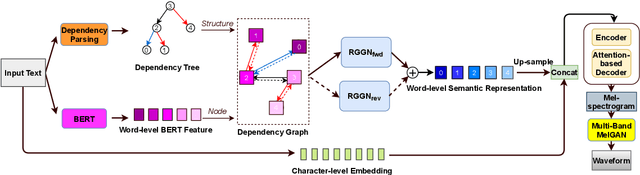



Semantic information of a sentence is crucial for improving the expressiveness of a text-to-speech (TTS) system, but can not be well learned from the limited training TTS dataset just by virtue of the nowadays encoder structures. As large scale pre-trained text representation develops, bidirectional encoder representations from transformers (BERT) has been proven to embody text-context semantic information and applied to TTS as additional input. However BERT can not explicitly associate semantic tokens from point of dependency relations in a sentence. In this paper, to enhance expressiveness, we propose a semantic representation learning method based on graph neural network, considering dependency relations of a sentence. Dependency graph of input text is composed of edges from dependency tree structure considering both the forward and the reverse directions. Semantic representations are then extracted at word level by the relational gated graph network (RGGN) fed with features from BERT as nodes input. Upsampled semantic representations and character-level embeddings are concatenated to serve as the encoder input of Tacotron-2. Experimental results show that our proposed method outperforms the baseline using vanilla BERT features both in LJSpeech and Blizzard Challenge 2013 datasets, and semantic representations learned from the reverse direction are more effective for enhancing expressiveness.