 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially learning disentangled speech representations for robust multi-factor voice conversion
Paper and Code
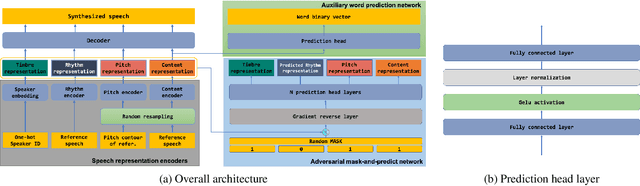


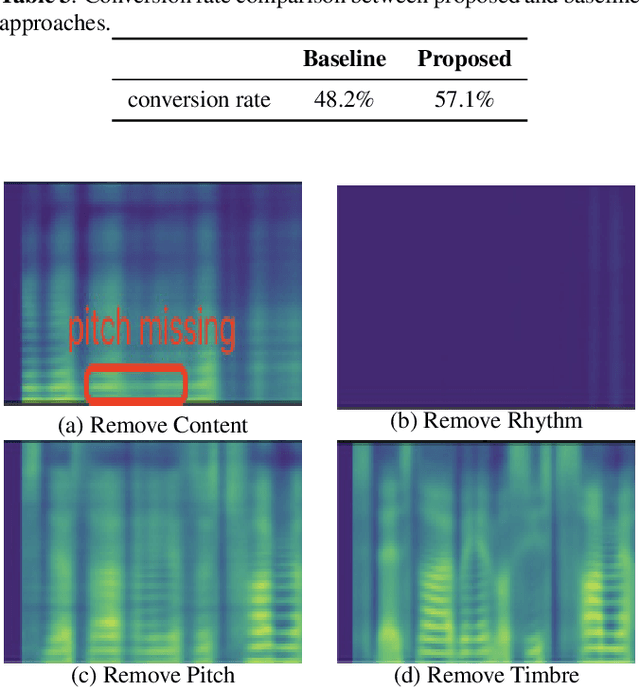
Factorizing speech as disentangled speech representations is vital to achieve highly controllable style transfer in voice conversion (VC). Conventional speech representation learning methods in VC only factorize speech as speaker and content, lacking controllability on other prosody-related factors. State-of-the-art speech representation learning methods for more speech factors are using primary disentangle algorithms such as random resampling and ad-hoc bottleneck layer size adjustment, which however is hard to ensure robust speech representation disentanglement. To increase the robustness of highly controllable style transfer on multiple factors in VC, we propose a disentangled speech representation learning framework based on adversarial learning. Four speech representations characterizing content, timbre, rhythm and pitch are extracted, and further disentangled by an adversarial network inspired by BERT. The adversarial network is used to minimize the correlations between the speech representations, by randomly masking and predicting one of the representations from the others. A word prediction network is also adopted to learn a more informative content representation. Experimental results show that the proposed speech representation learning framework significantly improves the robustness of VC on multiple factors by increasing conversion rate from 48.2% to 57.1% and ABX preference exceeding by 31.2% compared with state-of-the-art method.