 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVGrasp: Open-Vocabulary Grasping Assistance via Multimodal Intent Detection
Sep 04, 2025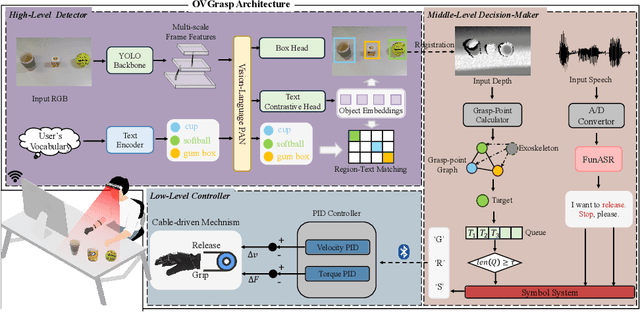
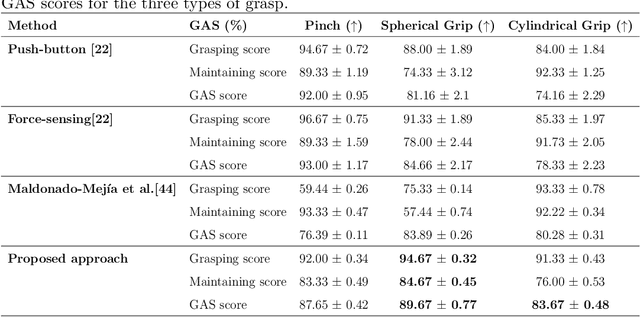

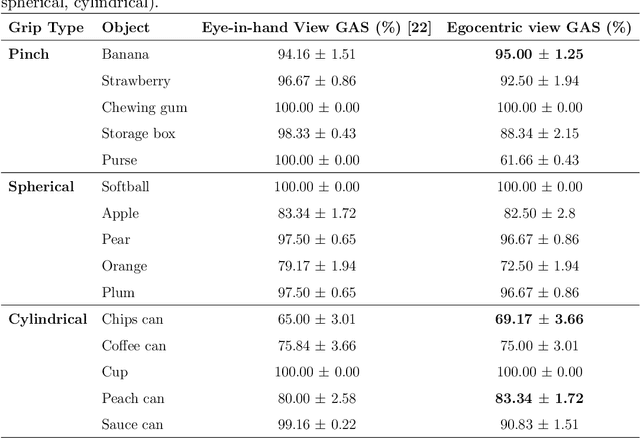
Grasping assistance is essential for restoring autonomy in individuals with motor impairments, particularly in unstructured environments where object categories and user intentions are diverse and unpredictable. We present OVGrasp, a hierarchical control framework for soft exoskeleton-based grasp assistance that integrates RGB-D vision, open-vocabulary prompts, and voice commands to enable robust multimodal interaction. To enhance generalization in open environments, OVGrasp incorporates a vision-language foundation model with an open-vocabulary mechanism, allowing zero-shot detection of previously unseen objects without retraining. A multimodal decision-maker further fuses spatial and linguistic cues to infer user intent, such as grasp or release, in multi-object scenarios. We deploy the complete framework on a custom egocentric-view wearable exoskeleton and conduct systematic evaluations on 15 objects across three grasp types. Experimental results with ten participants demonstrate that OVGrasp achieves a grasping ability score (GAS) of 87.00%, outperforming state-of-the-art baselines and achieving improved kinematic alignment with natural hand motion.
Imitation Learning for Adaptive Control of a Virtual Soft Exoglove
May 14, 2025



The use of wearable robots has been widely adopted in rehabilitation training for patients with hand motor impairments. However, the uniqueness of patients' muscle loss is often overlooked. Leveraging reinforcement learning and a biologically accurate musculoskeletal model in simulation, we propose a customized wearable robotic controller that is able to address specific muscle deficits and to provide compensation for hand-object manipulation tasks. Video data of a same subject performing human grasping tasks is used to train a manipulation model through learning from demonstration. This manipulation model is subsequently fine-tuned to perform object-specific interaction tasks. The muscle forces in the musculoskeletal manipulation model are then weakened to simulate neurological motor impairments, which are later compensated by the actuation of a virtual wearable robotics glove. Results shows that integrating the virtual wearable robotic glove provides shared assistance to support the hand manipulator with weakened muscle forces. The learned exoglove controller achieved an average of 90.5\% of the original manipulation proficiency.
Point Cloud-based Grasping for Soft Hand Exoskeleton
Apr 04, 2025Grasping is a fundamental skill for interacting with and manipulating objects in the environment. However, this ability can be challenging for individuals with hand impairments. Soft hand exoskeletons designed to assist grasping can enhance or restore essential hand functions, yet controlling these soft exoskeletons to support users effectively remains difficult due to the complexity of understanding the environment. This study presents a vision-based predictive control framework that leverages contextual awareness from depth perception to predict the grasping target and determine the next control state for activation. Unlike data-driven approaches that require extensive labelled datasets and struggle with generalizability, our method is grounded in geometric modelling, enabling robust adaptation across diverse grasping scenarios. The Grasping Ability Score (GAS) was used to evaluate performance, with our system achieving a state-of-the-art GAS of 91% across 15 objects and healthy participants, demonstrating its effectiveness across different object types. The proposed approach maintained reconstruction success for unseen objects, underscoring its enhanced generalizability compared to learning-based models.
MultiClear: Multimodal Soft Exoskeleton Glove for Transparent Object Grasping Assistance
Apr 04, 2025Grasping is a fundamental skill for interacting with the environment. However, this ability can be difficult for some (e.g. due to disability). Wearable robotic solutions can enhance or restore hand function, and recent advances have leveraged computer vision to improve grasping capabilities. However, grasping transparent objects remains challenging due to their poor visual contrast and ambiguous depth cues. Furthermore, while multimodal control strategies incorporating tactile and auditory feedback have been explored to grasp transparent objects, the integration of vision with these modalities remains underdeveloped. This paper introduces MultiClear, a multimodal framework designed to enhance grasping assistance in a wearable soft exoskeleton glove for transparent objects by fusing RGB data, depth data, and auditory signals. The exoskeleton glove integrates a tendon-driven actuator with an RGB-D camera and a built-in microphone. To achieve precise and adaptive control, a hierarchical control architecture is proposed. For the proposed hierarchical control architecture, a high-level control layer provides contextual awareness, a mid-level control layer processes multimodal sensory inputs, and a low-level control executes PID motor control for fine-tuned grasping adjustments. The challenge of transparent object segmentation was managed by introducing a vision foundation model for zero-shot segmentation. The proposed system achieves a Grasping Ability Score of 70.37%, demonstrating its effectiveness in transparent object manipulation.
PointGrasp: Point Cloud-based Grasping for Tendon-driven Soft Robotic Glove Applications
Mar 19, 2024Controlling hand exoskeletons to assist individuals with grasping tasks poses a challenge due to the difficulty in understanding user intentions. We propose that most daily grasping tasks during activities of daily living (ADL) can be deduced by analyzing object geometries (simple and complex) from 3D point clouds. The study introduces PointGrasp, a real-time system designed for identifying household scenes semantically, aiming to support and enhance assistance during ADL for tailored end-to-end grasping tasks. The system comprises an RGB-D camera with an inertial measurement unit and a microprocessor integrated into a tendon-driven soft robotic glove. The RGB-D camera processes 3D scenes at a rate exceeding 30 frames per second. The proposed pipeline demonstrates an average RMSE of 0.8 $\pm$ 0.39 cm for simple and 0.11 $\pm$ 0.06 cm for complex geometries. Within each mode, it identifies and pinpoints reachable objects. This system shows promise in end-to-end vision-driven robotic-assisted rehabilitation manual tasks.