 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
TRANSOM: An Efficient Fault-Tolerant System for Training LLMs
Oct 18, 2023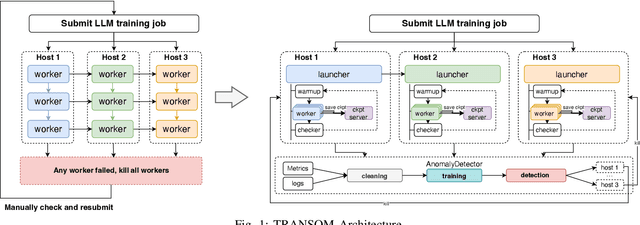
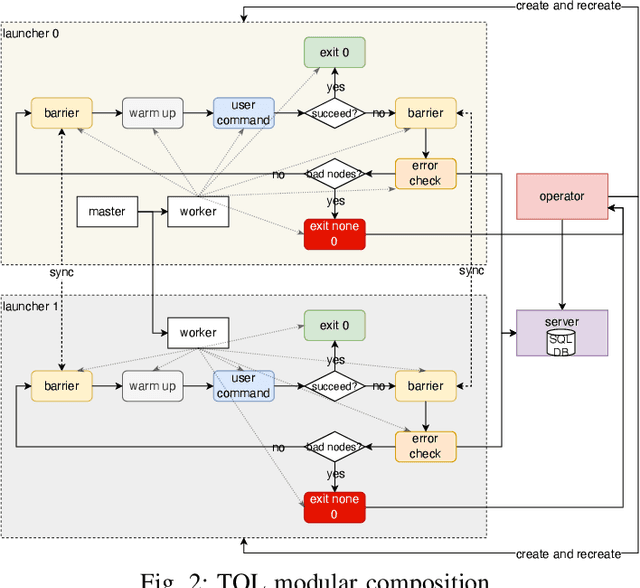
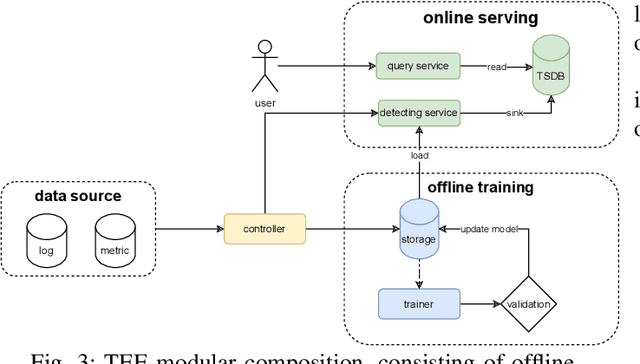
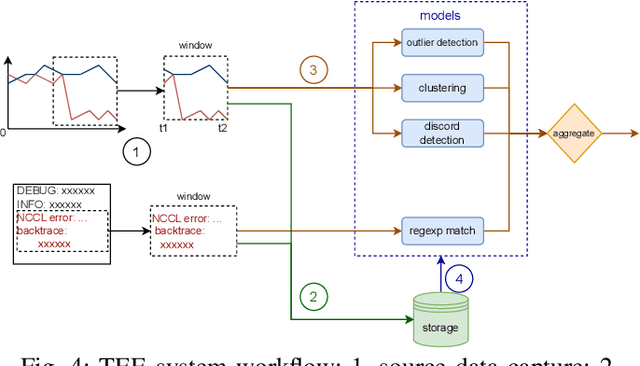
Large language models (LLMs) with hundreds of billions or trillions of parameters, represented by chatGPT, have achieved profound impact on various fields. However, training LLMs with super-large-scale parameters requires large high-performance GPU clusters and long training periods lasting for months. Due to the inevitable hardware and software failures in large-scale clusters, maintaining uninterrupted and long-duration training is extremely challenging. As a result, A substantial amount of training time is devoted to task checkpoint saving and loading, task rescheduling and restart, and task manual anomaly checks, which greatly harms the overall training efficiency. To address these issues, we propose TRANSOM, a novel fault-tolerant LLM training system. In this work, we design three key subsystems: the training pipeline automatic fault tolerance and recovery mechanism named Transom Operator and Launcher (TOL), the training task multi-dimensional metric automatic anomaly detection system named Transom Eagle Eye (TEE), and the training checkpoint asynchronous access automatic fault tolerance and recovery technology named Transom Checkpoint Engine (TCE). Here, TOL manages the lifecycle of training tasks, while TEE is responsible for task monitoring and anomaly reporting. TEE detects training anomalies and reports them to TOL, who automatically enters the fault tolerance strategy to eliminate abnormal nodes and restart the training task. And the asynchronous checkpoint saving and loading functionality provided by TCE greatly shorten the fault tolerance overhead. The experimental results indicate that TRANSOM significantly enhances the efficiency of large-scale LLM training on clusters. Specifically, the pre-training time for GPT3-175B has been reduced by 28%, while checkpoint saving and loading performance have improved by a factor of 20.