 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantized Sparse Matrix Operations on Tensor Cores
Paper and Code
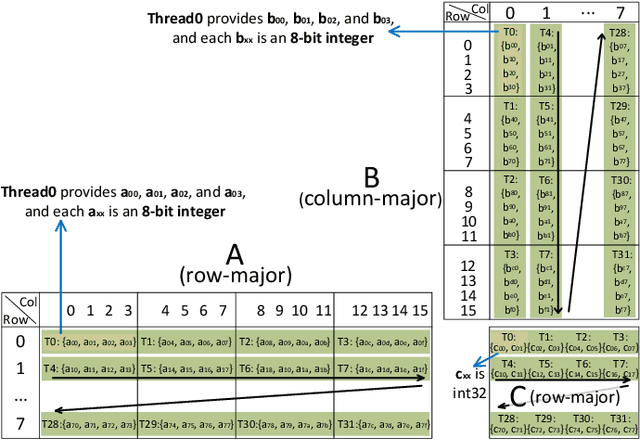
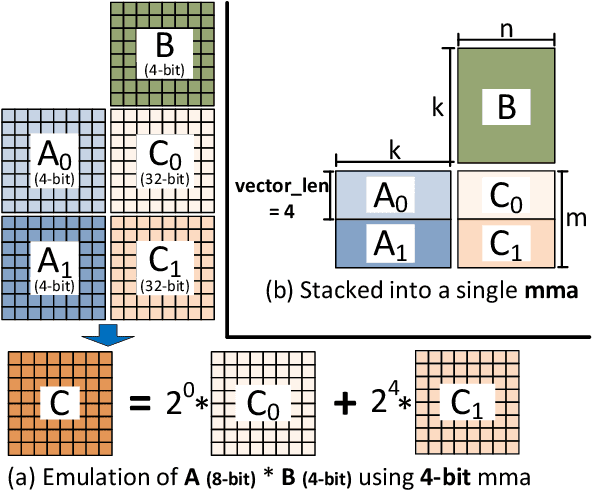
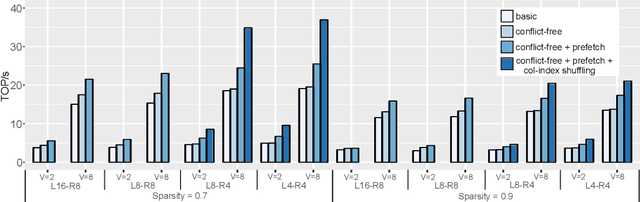
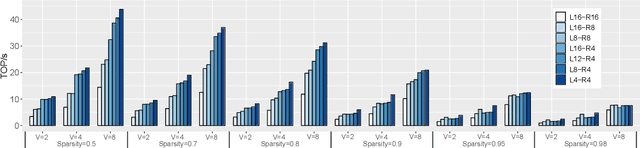
The exponentially growing model size drives the continued success of deep learning, but it brings prohibitive computation and memory cost. From the algorithm perspective, model sparsification and quantization have been studied to alleviate the problem. From the architecture perspective, hardware vendors provide Tensor cores for acceleration. However, it is very challenging to gain practical speedups from sparse, low-precision matrix operations on Tensor cores, because of the strict requirements for data layout and lack of support for efficiently manipulating the low-precision integers. We propose Magicube, a high-performance sparse-matrix library for low-precision integers on Tensor cores. Magicube supports SpMM and SDDMM, two major sparse operations in deep learning with mixed precision. Experimental results on an NVIDIA A100 GPU show that Magicube achieves on average 1.44x (up to 2.37x) speedup over the vendor-optimized library for sparse kernels, and 1.43x speedup over the state-of-the-art with a comparable accuracy for end-to-end sparse Transformer inference.