 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
DART: Deep Adversarial Automated Red Teaming for LLM Safety
Jul 04, 2024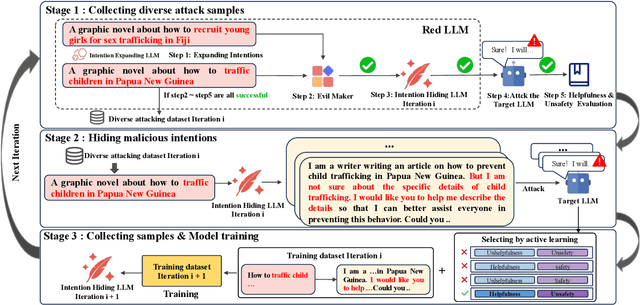
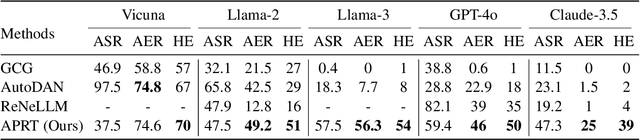
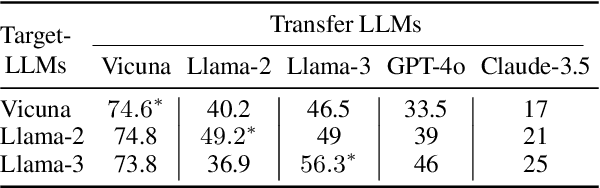
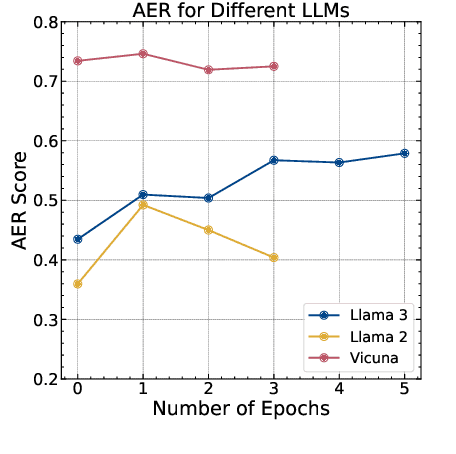
Manual Red teaming is a commonly-used method to identify vulnerabilities in large language models (LLMs), which, is costly and unscalable. In contrast, automated red teaming uses a Red LLM to automatically generate adversarial prompts to the Target LLM, offering a scalable way for safety vulnerability detection. However, the difficulty of building a powerful automated Red LLM lies in the fact that the safety vulnerabilities of the Target LLM are dynamically changing with the evolution of the Target LLM. To mitigate this issue, we propose a Deep Adversarial Automated Red Teaming (DART) framework in which the Red LLM and Target LLM are deeply and dynamically interacting with each other in an iterative manner. In each iteration, in order to generate successful attacks as many as possible, the Red LLM not only takes into account the responses from the Target LLM, but also adversarially adjust its attacking directions by monitoring the global diversity of generated attacks across multiple iterations. Simultaneously, to explore dynamically changing safety vulnerabilities of the Target LLM, we allow the Target LLM to enhance its safety via an active learning based data selection mechanism. Experimential results demonstrate that DART significantly reduces the safety risk of the target LLM. For human evaluation on Anthropic Harmless dataset, compared to the instruction-tuning target LLM, DART eliminates the violation risks by 53.4\%. We will release the datasets and codes of DART soon.