 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Language Model as Data Prospector for Large Language Model
Paper and Code
Dec 13, 2024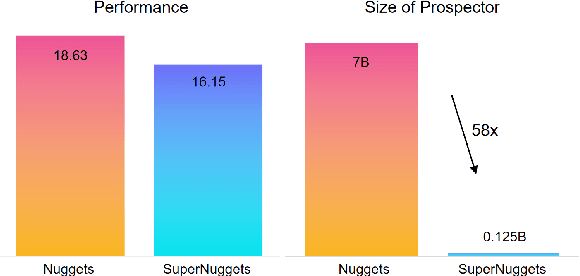
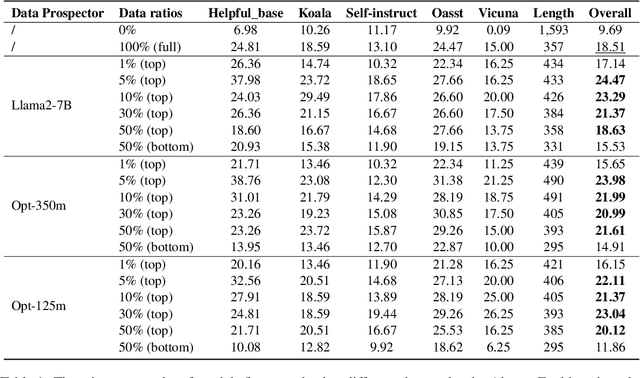
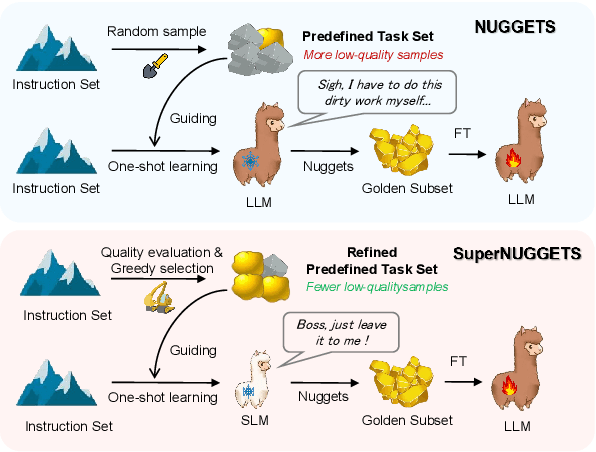
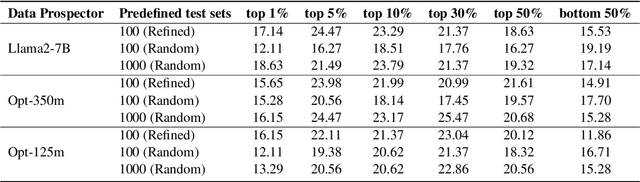
The quality of instruction data directly affects the performance of fine-tuned Large Language Models (LLMs). Previously, \cite{li2023one} proposed \texttt{NUGGETS}, which identifies and selects high-quality quality data from a large dataset by identifying those individual instruction examples that can significantly improve the performance of different tasks after being learnt as one-shot instances. In this work, we propose \texttt{SuperNUGGETS}, an improved variant of \texttt{NUGGETS} optimised for efficiency and performance. Our \texttt{SuperNUGGETS} uses a small language model (SLM) instead of a large language model (LLM) to filter the data for outstanding one-shot instances and refines the predefined set of tests. The experimental results show that the performance of \texttt{SuperNUGGETS} only decreases by 1-2% compared to \texttt{NUGGETS}, but the efficiency can be increased by a factor of 58. Compared to the original \texttt{NUGGETS}, our \texttt{SuperNUGGETS} has a higher utility value due to the significantly lower resource consumption.