 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRS-QA -- Graph Reasoning-Structured Question Answering Dataset
Nov 01, 2024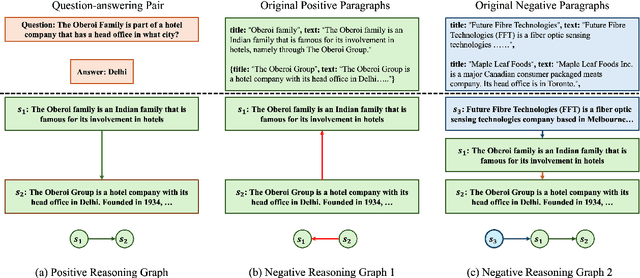
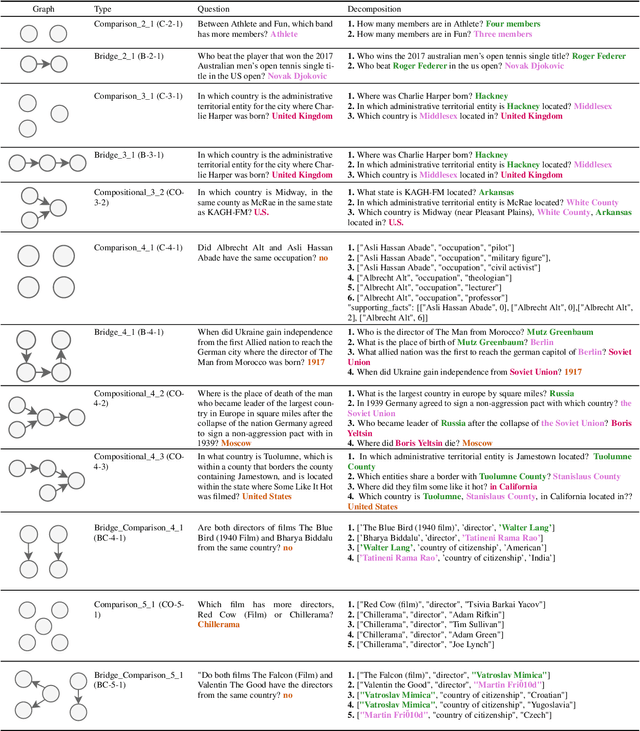
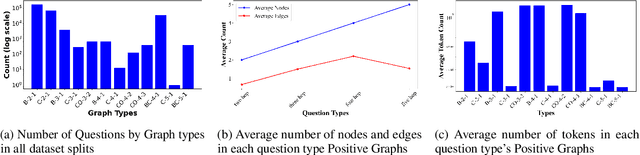

Large Language Models (LLMs) have excelled in multi-hop question-answering (M-QA) due to their advanced reasoning abilities. However, the impact of the inherent reasoning structures on LLM M-QA performance remains unclear, largely due to the absence of QA datasets that provide fine-grained reasoning structures. To address this gap, we introduce the Graph Reasoning-Structured Question Answering Dataset (GRS-QA), which includes both semantic contexts and reasoning structures for QA pairs. Unlike existing M-QA datasets, where different reasoning structures are entangled together, GRS-QA explicitly captures intricate reasoning pathways by constructing reasoning graphs, where nodes represent textual contexts and edges denote logical flows. These reasoning graphs of different structures enable a fine-grained evaluation of LLM reasoning capabilities across various reasoning structures. Our empirical analysis reveals that LLMs perform differently when handling questions with varying reasoning structures. This finding facilitates the exploration of textual structures as compared with semantics.
NLP at UC Santa Cruz at SemEval-2024 Task 5: Legal Answer Validation using Few-Shot Multi-Choice QA
Apr 04, 2024This paper presents our submission to the SemEval 2024 Task 5: The Legal Argument Reasoning Task in Civil Procedure. We present two approaches to solving the task of legal answer validation, given an introduction to the case, a question and an answer candidate. Firstly, we fine-tuned pre-trained BERT-based models and found that models trained on domain knowledge perform better. Secondly, we performed few-shot prompting on GPT models and found that reformulating the answer validation task to be a multiple-choice QA task remarkably improves the performance of the model. Our best submission is a BERT-based model that achieved the 7th place out of 20.