 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRS-QA -- Graph Reasoning-Structured Question Answering Dataset
Paper and Code
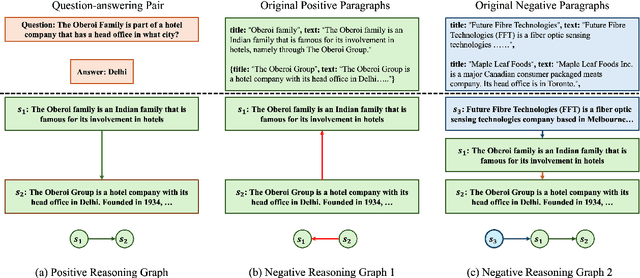
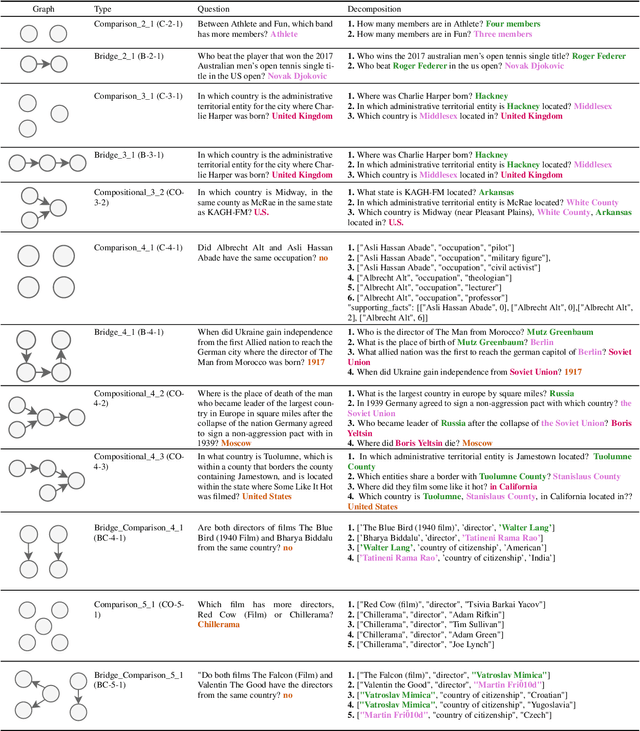
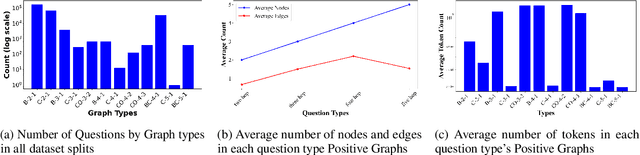

Large Language Models (LLMs) have excelled in multi-hop question-answering (M-QA) due to their advanced reasoning abilities. However, the impact of the inherent reasoning structures on LLM M-QA performance remains unclear, largely due to the absence of QA datasets that provide fine-grained reasoning structures. To address this gap, we introduce the Graph Reasoning-Structured Question Answering Dataset (GRS-QA), which includes both semantic contexts and reasoning structures for QA pairs. Unlike existing M-QA datasets, where different reasoning structures are entangled together, GRS-QA explicitly captures intricate reasoning pathways by constructing reasoning graphs, where nodes represent textual contexts and edges denote logical flows. These reasoning graphs of different structures enable a fine-grained evaluation of LLM reasoning capabilities across various reasoning structures. Our empirical analysis reveals that LLMs perform differently when handling questions with varying reasoning structures. This finding facilitates the exploration of textual structures as compared with semantics.