 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVC: Self-Supervised Zero-Shot Voice Conversion
Paper and Code
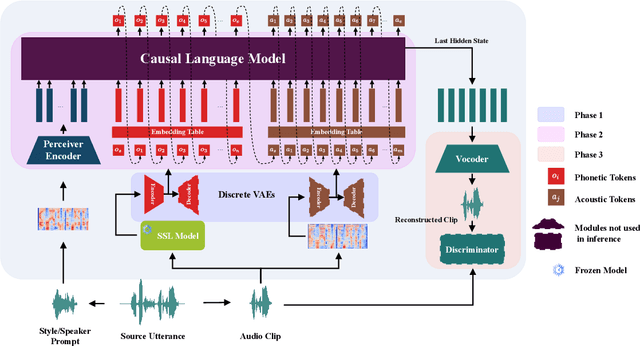
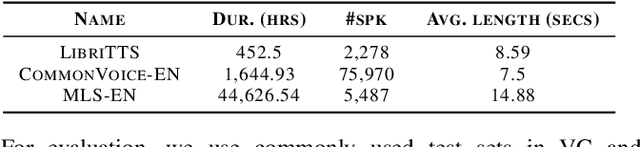
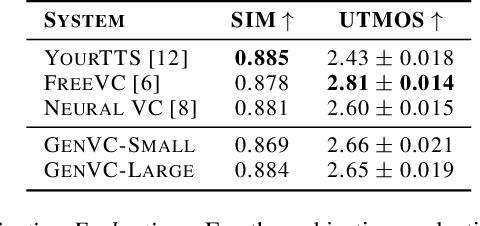
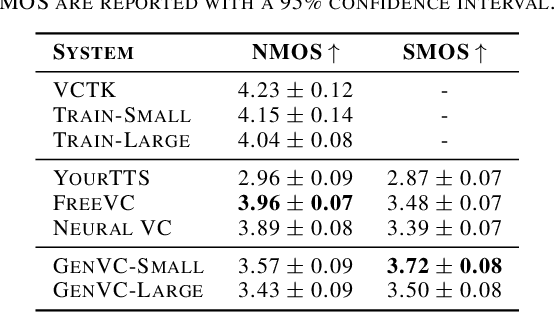
Zero-shot voice conversion has recently made substantial progress, but many models still depend on external supervised systems to disentangle speaker identity and linguistic content. Furthermore, current methods often use parallel conversion, where the converted speech inherits the source utterance's temporal structure, restricting speaker similarity and privacy. To overcome these limitations, we introduce GenVC, a generative zero-shot voice conversion model. GenVC learns to disentangle linguistic content and speaker style in a self-supervised manner, eliminating the need for external models and enabling efficient training on large, unlabeled datasets. Experimental results show that GenVC achieves state-of-the-art speaker similarity while maintaining naturalness competitive with leading approaches. Its autoregressive generation also allows the converted speech to deviate from the source utterance's temporal structure. This feature makes GenVC highly effective for voice anonymization, as it minimizes the preservation of source prosody and speaker characteristics, enhancing privacy protection.