 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Acoustic Compensation and Adaptive Focal Training for Personalized Speech Enhancement
Nov 22, 2022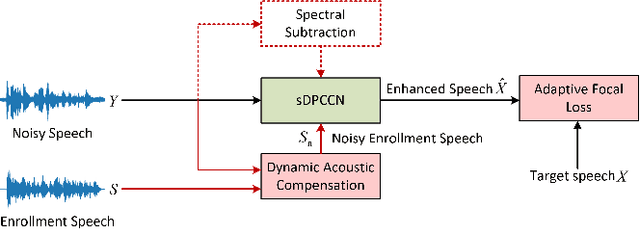
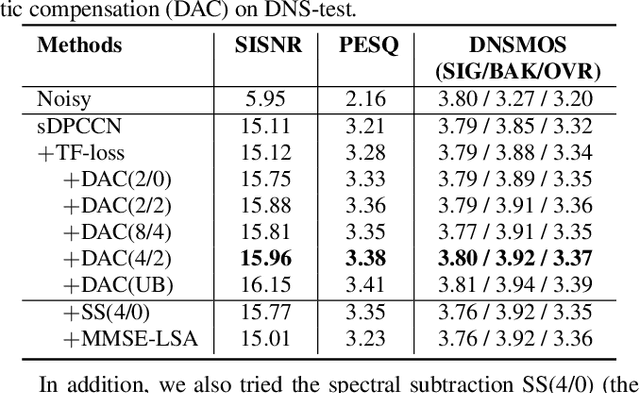
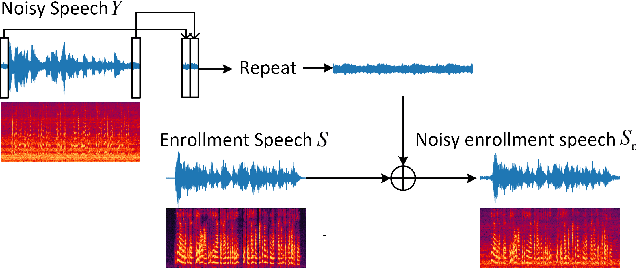
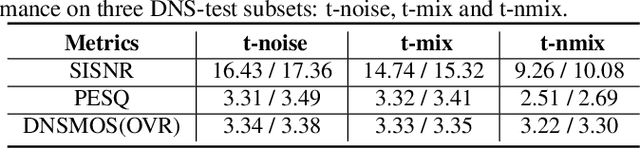
Recently, more and more personalized speech enhancement systems (PSE) with excellent performance have been proposed. However, two critical issues still limit the performance and generalization ability of the model: 1) Acoustic environment mismatch between the test noisy speech and target speaker enrollment speech; 2) Hard sample mining and learning. In this paper, dynamic acoustic compensation (DAC) is proposed to alleviate the environment mismatch, by intercepting the noise or environmental acoustic segments from noisy speech and mixing it with the clean enrollment speech. To well exploit the hard samples in training data, we propose an adaptive focal training (AFT) strategy by assigning adaptive loss weights to hard and non-hard samples during training. A time-frequency multi-loss training is further introduced to improve and generalize our previous work sDPCCN for PSE. The effectiveness of proposed methods are examined on the DNS4 Challenge dataset. Results show that, the DAC brings large improvements in terms of multiple evaluation metrics, and AFT reduces the hard sample rate significantly and produces obvious MOS score improvement.
PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
Mar 04, 2022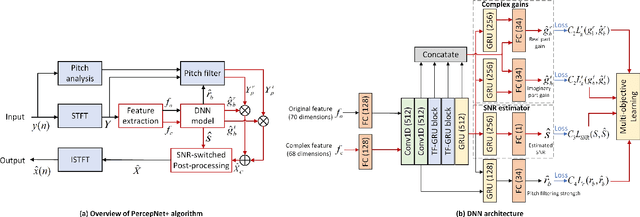
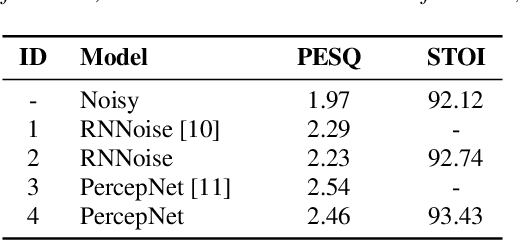
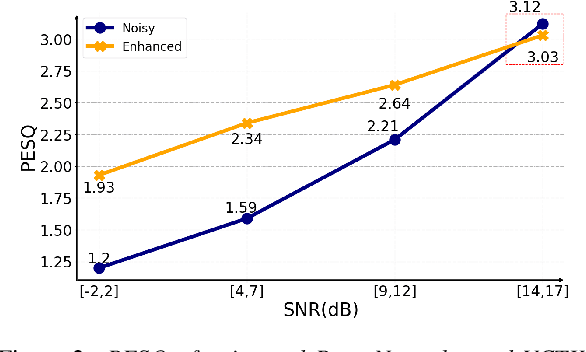
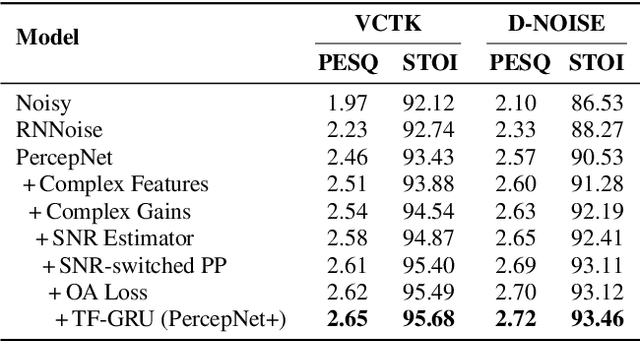
PercepNet, a recent extension of the RNNoise, an efficient, high-quality and real-time full-band speech enhancement technique, has shown promising performance in various public deep noise suppression tasks. This paper proposes a new approach, named PercepNet+, to further extend the PercepNet with four significant improvements. First, we introduce a phase-aware structure to leverage the phase information into PercepNet, by adding the complex features and complex subband gains as the deep network input and output respectively. Then, a signal-to-noise ratio (SNR) estimator and an SNR switched post-processing are specially designed to alleviate the over attenuation (OA) that appears in high SNR conditions of the original PercepNet. Moreover, the GRU layer is replaced by TF-GRU to model both temporal and frequency dependencies. Finally, we propose to integrate the loss of complex subband gain, SNR, pitch filtering strength, and an OA loss in a multi-objective learning manner to further improve the speech enhancement performance. Experimental results show that, the proposed PercepNet+ outperforms the original PercepNet significantly in terms of both PESQ and STOI, without increasing the model size too much.