 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Separation Consistency Training for Adaptation of Unsupervised Speech Separation
Paper and Code
Apr 23, 2022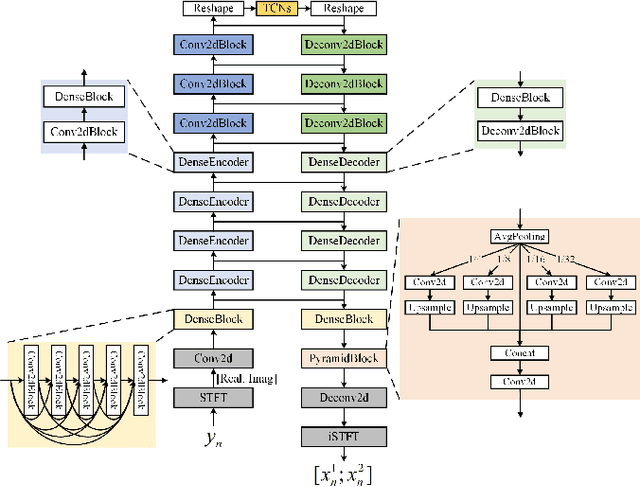
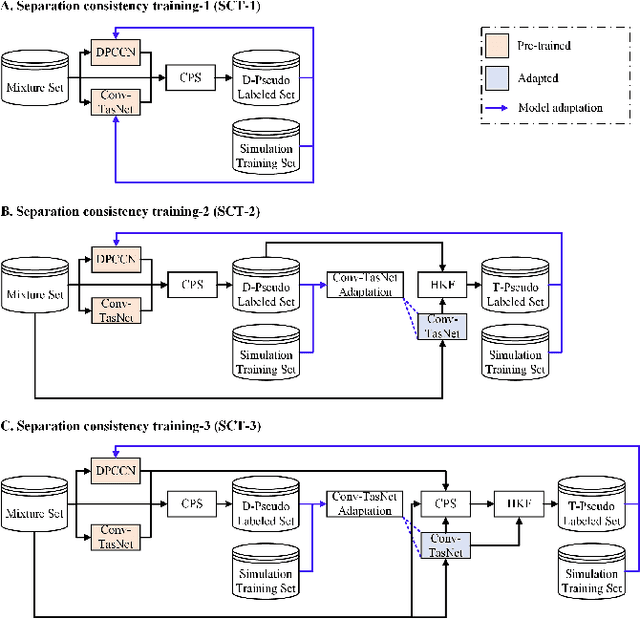
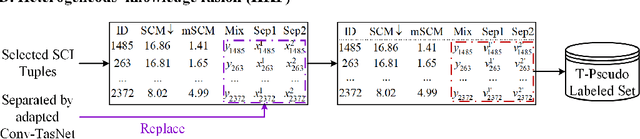
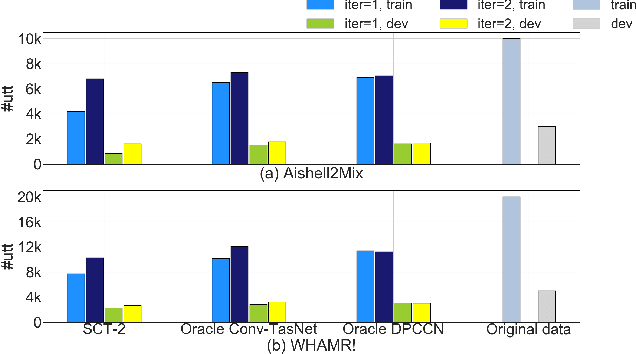
Recently, supervised speech separation has made great progress. However, limited by the nature of supervised training, most existing separation methods require ground-truth sources and are trained on synthetic datasets. This ground-truth reliance is problematic, because the ground-truth signals are usually unavailable in real conditions. Moreover, in many industry scenarios, the real acoustic characteristics deviate far from the ones in simulated datasets. Therefore, the performance usually degrades significantly when applying the supervised speech separation models to real applications. To address these problems, in this study, we propose a novel separation consistency training, termed SCT, to exploit the real-world unlabeled mixtures for improving cross-domain unsupervised speech separation in an iterative manner, by leveraging upon the complementary information obtained from heterogeneous (structurally distinct but behaviorally complementary) models. SCT follows a framework using two heterogeneous neural networks (HNNs) to produce high confidence pseudo labels of unlabeled real speech mixtures. These labels are then updated, and used to refine the HNNs to produce more reliable consistent separation results for real mixture pseudo-labeling. To maximally utilize the large complementary information between different separation networks, a cross-knowledge adaptation is further proposed. Together with simulated dataset, those real mixtures with high confidence pseudo labels are then used to update the HNN separation models iteratively. In addition, we find that combing the heterogeneous separation outputs by a simple linear fusion can further slightly improve the final system performance.